


AI Innovations and Trends 10: LazyGraphRAG, Zerox, and Mindful-RAG
You can watch the video:
This article is the 10th in this promising series. Today, we will explore three exciting topics in AI:
LazyGraphRAG: Simplified and Efficient GraphRAG
Zerox: PDF to Markdown with Multimodal Models
Mindful-RAG: Overcoming Challenges in Knowledge Graph-Enhanced RAG
LazyGraphRAG: Simplified and Efficient GraphRAG
Recently, there have been many official updates to GraphRAG. I previously introduced DRIFT Search and incremental updates functionality. Today, let's look at its latest official improvement: LazyGraphRAG.
Traditional RAG, or vector RAG, uses best-first search to find source text chunks most similar to the query. However, it cannot grasp the full breadth of a dataset when handling global queries.
In contrast, GraphRAG global search employs breadth-first search, leveraging community structures of text entities to ensure comprehensive answers across the entire dataset. Yet it struggles to identify the most relevant communities for local queries.
LazyGraphRAG bridges these approaches, combining the strengths of vector RAG and graph RAG while addressing their limitations. It achieves this by integrating best-first and breadth-first search dynamics through iterative deepening. Unlike full GraphRAG's global search mechanism, this approach is "lazy" as it postpones LLM use.
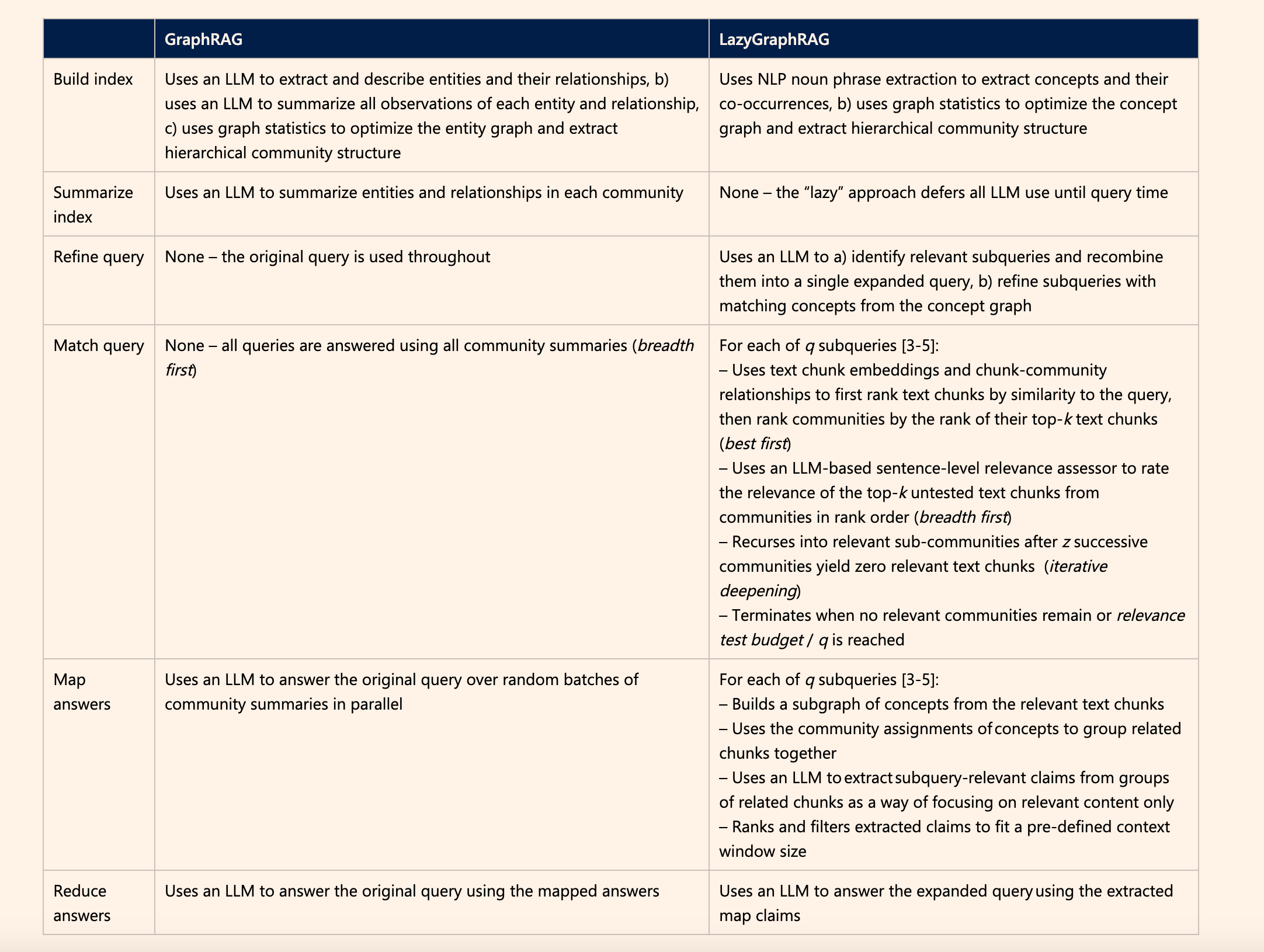
As shown in Figure 1, the key difference between GraphRAG and LazyGraphRAG lies in how they handle indexing and query processing.
GraphRAG uses an LLM during the indexing phase to extract and summarize entities and relationships, optimize community structures, and directly use these summaries to answer queries. LazyGraphRAG relies on lightweight NLP methods during indexing to extract concepts and co-occurrences, deferring computational costs to the query phase.
GraphRAG does not optimize queries and directly answers them based on community summaries, while LazyGraphRAG decomposes queries into subqueries and uses an LLM to improve matching and answer extraction.
Based on official testing, LazyGraphRAG shows remarkable performance. Its indexing cost is only 0.1% of GraphRAG's cost and matches that of vector RAG. Additionally, its query performance surpasses other methods while maintaining lower costs.
Commentary
I believe anyone who has worked on knowledge graph projects understands that constructing and querying them requires significant time and effort.
In my view, LazyGraphRAG is actually a simplification of GraphRAG's data structure. It takes a lightweight approach by moving away from traditional knowledge graph concepts of entities and relationships. Instead, it uses simple NLP concepts and co-occurrences, and delays LLM processing until necessary, which substantially reduces construction costs.
Since its release, GraphRAG has not been practical for real-world production use, so the goal of LazyGraphRAG is to make it applicable for production environments.
Zerox: PDF to Markdown with Multimodal Models
Recently, multimodal LLMs have been increasingly used for OCR tasks, with tools like the previously discussed gptpdf and Lllma OCR. Today, let's look at another tool with a similar approach: Zerox.
Code
The testing code is shown below. The model can be switched to Gemini, Anthropic, or others.
from pyzerox import zerox
import os
import json
import asyncio
###################### Example for OpenAI ######################
model = "gpt-4o-mini" ## openai model
os.environ["OPENAI_API_KEY"] = "" ## your-api-key
# Define main async entrypoint
async def main():
file_path = "https://omni-demo-data.s3.amazonaws.com/test/cs101.pdf" ## local filepath and file URL supported
## process only some pages or all
select_pages = None ## None for all, but could be int or list(int) page numbers (1 indexed)
output_dir = "./output_test" ## directory to save the consolidated markdown file
result = await zerox(file_path=file_path, model=model, output_dir=output_dir,
custom_system_prompt=custom_system_prompt,select_pages=select_pages, **kwargs)
return result
# run the main function:
result = asyncio.run(main())
# print markdown result
print(result)Zerox's core idea is very simple, and we can observe it clearly in the Zerox function:
Input a file (PDF, DOCX, image, etc.)
Convert the file into a series of images
Process each image through an LLM to generate Markdown
Combine all responses into a complete Markdown document
The default system prompt is shown below.
class Prompts:
"""Class for storing prompts for the Zerox system."""
DEFAULT_SYSTEM_PROMPT = """
Convert the following PDF page to markdown.
Return only the markdown with no explanation text.
Do not exclude any content from the page.
"""Figure 2 is the results provided by this project.

Commentary
By leveraging advanced multimodal LLMs like GPT-4o-mini or Llama 3.2 for document parsing, the system can handle unfamiliar PDFs and images without pre-training data, delivering high-precision OCR results.
This is an elegant approach that doesn't require building a document parsing pipeline.
However, it has three main limitations: lack of privacy assurance when handling confidential code or files with closed-source models, limited user control over intermediate outputs such as layouts, and the high cost associated with multimodal LLMs.
Mindful-RAG: Overcoming Challenges in Knowledge Graph-Enhanced RAG
In RAG systems, integrating LLMs with knowledge graphs (KGs) offers a promising avenue for enhancing factual accuracy in complex question-answering tasks. Despite these advancements, LLMs still face challenges in providing accurate answers even when the necessary information is available.
Mindful-RAG investigates these challenges and improves accuracy through intent-based and contextual knowledge retrieval.
I have detailed this method, and now I have some new insights.
KG-Based RAG Failure Analysis
As shown in Figure 3, Mindful-RAG delves into a comprehensive failure analysis of these methods, presenting critical error patterns and their implications.

Solution
Mindful-RAG improves KG-based RAG systems through better intent identification and context alignment, targeting the key failure points in reasoning and KG topology.
A case study using the query "Who is Niall Ferguson's wife?" from WebQSP dataset demonstrates how the system handles relationship queries that require precise contextual understanding.
Identify Key Entities and Relevant Tokens: In this example, "Niall Ferguson" and "wife" - to help locate relevant knowledge graph information.
Identify the Intent: In this case, the intent is to "identify the spouse of Niall Ferguson." This crucial step guides the retrieval process by ensuring the system precisely understands the query's purpose.
Identify the Context: In this case, the context involves personal relationships, marital status and distinguishing between current and past spouses, which is essential for determining the correct spouse in the query.
Candidate Relation Extraction: Extracts candidate relations from the knowledge graph within a one-hop distance from the key entity. For "Niall Ferguson," this includes details about his profession, personal life, and family ties. Traditional methods often fail here by including irrelevant relations without context.
Intent-Based Filtering and Context-Based Ranking of Relations: In this case, the relation "people.person.spouse_s" is identified as the most relevant, considering the intent to identify the current spouse.
Contextually Align the Constraints: Aligns results with time and location constraints. For this query, the system checks marriage dates to distinguish between current and past spouses. This step is crucial to avoid confusion between past and current spouses.
Intent-Based Feedback: Verifies if answers match the identified intent and context, refining responses if needed. For example, it correctly identifies "Ayaan Hirsi Ali" as Niall Ferguson's current spouse, while traditional systems might incorrectly select "Sue Douglas," a former spouse.
Commentary
Traditional KG-based RAG systems use basic semantic matching that can lead to incorrect answers by selecting the first listed spouse without considering time context or query intent. Mindful-RAG improves accuracy by focusing on exact intent and context, especially helpful for complex queries needing precise disambiguation.
In my view, while Mindful-RAG has its advantages, it also faces several challenges.
The system's effectiveness depends heavily on the quality and completeness of the knowledge graph. In areas where the knowledge graph is sparse or poorly organized, its performance can suffer.
Another issue is that Mindful-RAG relies on static knowledge graphs, but real-world applications often require dynamic updates. Fields like news, social media, and market trends demand real-time integration of new information to stay relevant.
Finally, if you’re interested in the series, feel free to check out my other articles.