
AI Innovations and Trends 09: Cursor Tool's RAG Features, TableRAG, and Llama OCR

You can watch the video:
This article is the ninth installment in this series. Today, let's dive into three exciting advancements in AI:
Cursor Tool's RAG: Unlocking Code Indexing and Inference Technologies
TableRAG: Large-Scale Table Understanding
Llama OCR: An npm Library to Run OCR with Llama
Cursor Tool's RAG: Unlocking Code Indexing and Inference Technologies
Cursor is an AI-powered code editor designed to enhance the coding experience.

Recently, Cursor disclosed its codebase indexing and retrieval technology in its security documentation.
Although brief, the RAG method they describe is worth studying. Let me share my understanding.
Indexing Process

As shown in Figure 2, the indexing process begins by scanning the codebase and computing a Merkle tree of hashes of all files. This computed Merkle tree is then synchronized with the server, where periodic checks for hash mismatches are performed, ensuring that only modified files are uploaded.
The changed files are chunked and embedded on the server, with the embeddings stored in Turbopuffer. To support path-based filtering in search results, encrypted file path information and line ranges are also stored. In addition, AWS caching is leveraged to accelerate the re-indexing process.
Inference Process
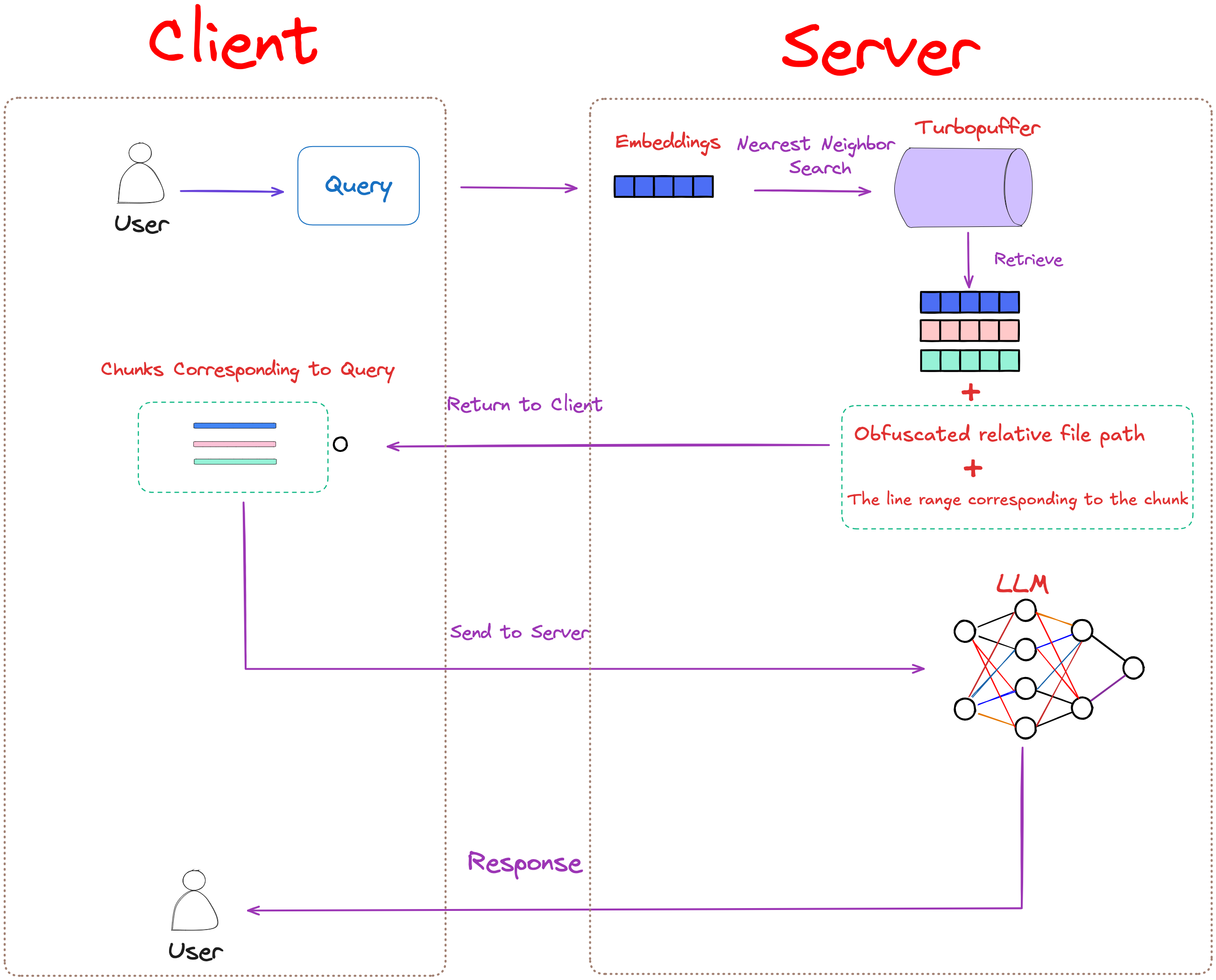
As shown in Figure 3, during the inference stage, an embedding is computed for the query, and a nearest-neighbor search is performed.
The retrieval returns the encrypted file path and line range, which the client uses to load the relevant file chunks. These chunks are then sent back to the server to generate the response to the query.
Commentary
From the above, I learned two insights:
In open-source or commercial projects, code security and privacy protection are crucial product requirements. By storing encrypted file paths and line ranges, ensuring code is never stored on servers, which reduces the risk of data leaks.
Using Merkle trees to track file changes minimizes unnecessary data transmission, which is a crucial optimization for large-scale codebases.
TableRAG: Large-Scale Table Understanding with RAG
Table comprehension is a challenging task for language models (LMs), especially when working with large tables. In a previous article, I explored RAG applied to tables. Today, let's explore another approach. I have detailed this method, and now I have some new insights.
Traditional language models methods struggle with large tables due to context-length limits, especially when tables exceed tens of thousands of tokens. Previous solutions that tried to compress table data often lost information or were computationally expensive. For instance, when dealing with large product sales tables, LMs must either process the entire dataset (risking token limits) or use incomplete data.
TableRAG solves this by using schema and cell retrieval to find key information without processing entire tables, reducing token usage while maintaining accuracy.
Comparison

As shown in Figure 4(d), TableRAG encodes and retrieves only essential schema and cell values relevant to the question, offering a streamlined input that maximizes efficiency and accuracy.
TableRAG
TableRAG combines schema and cell retrieval to extract key information from large tables efficiently. Instead of processing entire tables, it uses targeted queries to minimize token usage.
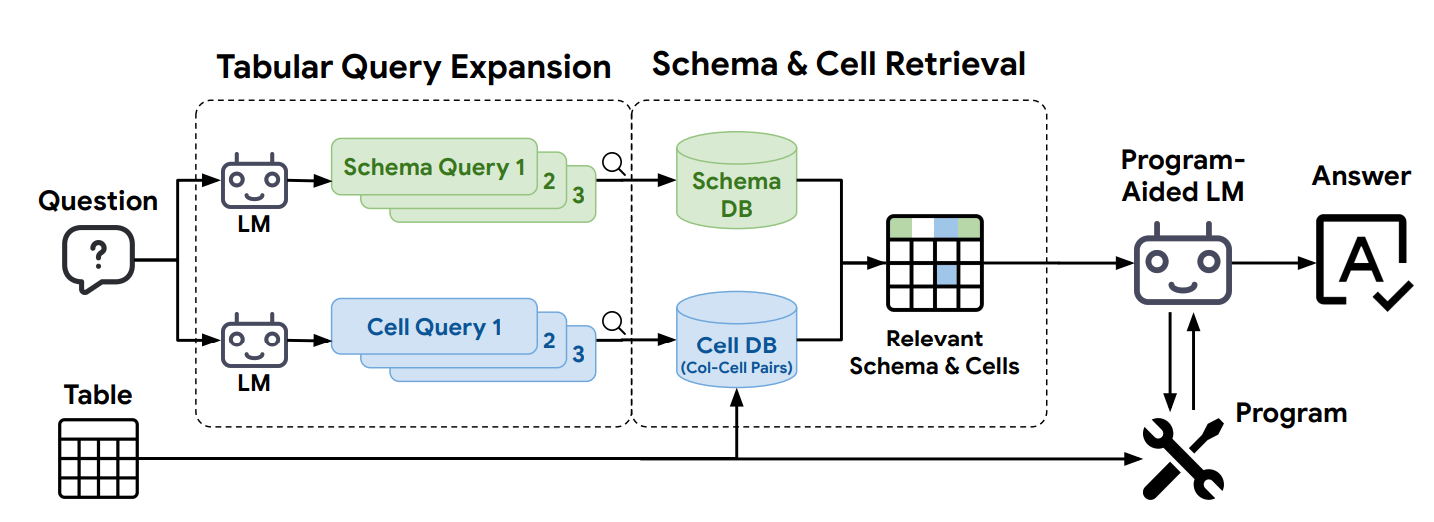
As shown in Figure 5, the framework builds schema and cell databases from tables. LMs expand questions into queries to retrieve relevant schemas and column-cell pairs. Top results are then combined in the LM solver's prompt for answering questions.

As shown in Figure 6, TableRAG’s workflow for the query “What is the average price for wallets?” includes several key steps, from query generation and relevant data retrieval to final computation.
Tabular Query Expansion: TableRAG first expands the user query into multiple sub-queries specifically targeting both schema and cell data. These sub-queries help identify relevant columns and keywords. For instance, schema queries generate terms like “product name,” “price,” and “category,” while cell queries target specific values such as “wallet.”
Schema Retrieval: TableRAG uses a pre-trained encoder to retrieve relevant columns, such as the "price" column, along with its data type (e.g., string type). Example values like "$449" and "$399" are provided, helping the model understand the structure and data range of the table.
Cell Retrieval with Encoding Budget: During cell retrieval, TableRAG retrieves values directly relevant to the query from the cell database. For example, values in the "description" column that mention "wallet" are extracted. In addition, the "description" column contains free-form text, which likely results in a high number of unique values, many of which may be truncated due to the cell encoding budget.
Program-Aided LM: After gathering the necessary schema and cell data, TableRAG’s program-aided solver executes the data processing tasks. Using Python operations, the model first cleans the price column (removing symbols and converting strings to float values), then filters rows containing “wallet,” and finally calculates the average price across these entries to arrive at the answer.
Through this process, TableRAG efficiently limits its retrieval scope by fetching only the schema and cell data that directly relates to each query, thereby reducing token usage.
Commentary
TableRAG leverages diverse perspectives on tabular information and the capabilities of LLMs, which represents a different direction from the multimodal RAG I discussed previously.
In my opinion, while TableRAG shows strong performance, its effectiveness depends on query-based expansion. This key mechanism's success hinges on the quality of generated queries—imprecise queries can lead to missed key information and reduced retrieval relevance. Additionally, finding the right encoding budget presents a tradeoff: too small a budget leads to information loss, while too large a budget reduces efficiency.
Future improvements could focus on developing smarter query-based expansion could enhance the precision of schema and cell retrieval. In addition, implementing adaptive encoding budgets that adjust automatically based on query complexity and table size could optimize the framework's overall efficiency.
Llama OCR: An npm Library to Run OCR with Llama
Finally, let's take a look at Llama OCR, a new open-source OCR project implemented in TypeScript.
The main process uses the free Llama 3.2 endpoint from Together AI to parse images and return markdown.
import { ocr } from "llama-ocr";
const markdown = await ocr({
filePath: "./trader-joes-receipt.jpg", // path to your image (soon PDF!)
apiKey: process.env.TOGETHER_API_KEY, // Together AI API key
});The core function and prompt comprise only 78 lines.
import Together from "together-ai";
import fs from "fs";
export async function ocr({
filePath,
apiKey = process.env.TOGETHER_API_KEY,
model = "Llama-3.2-90B-Vision",
}: {
filePath: string;
apiKey?: string;
model?: "Llama-3.2-90B-Vision" | "Llama-3.2-11B-Vision" | "free";
}) {
const visionLLM =
model === "free"
? "meta-llama/Llama-Vision-Free"
: `meta-llama/${model}-Instruct-Turbo`;
const together = new Together({
apiKey,
});
let finalMarkdown = await getMarkDown({ together, visionLLM, filePath });
return finalMarkdown;
}
async function getMarkDown({
together,
visionLLM,
filePath,
}: {
together: Together;
visionLLM: string;
filePath: string;
}) {
const systemPrompt = `Convert the provided image into Markdown format. Ensure that all content from the page is included, such as headers, footers, subtexts, images (with alt text if possible), tables, and any other elements.
Requirements:
- Output Only Markdown: Return solely the Markdown content without any additional explanations or comments.
- No Delimiters: Do not use code fences or delimiters like \`\`\`markdown.
- Complete Content: Do not omit any part of the page, including headers, footers, and subtext.
`;
const finalImageUrl = isRemoteFile(filePath)
? filePath
: `data:image/jpeg;base64,${encodeImage(filePath)}`;
const output = await together.chat.completions.create({
model: visionLLM,
messages: [
{
role: "user",
// @ts-expect-error
content: [
{ type: "text", text: systemPrompt },
{
type: "image_url",
image_url: {
url: finalImageUrl,
},
},
],
},
],
});
return output.choices[0].message.content;
}
function encodeImage(imagePath: string) {
const imageFile = fs.readFileSync(imagePath);
return Buffer.from(imageFile).toString("base64");
}
function isRemoteFile(filePath: string): boolean {
return filePath.startsWith("http://") || filePath.startsWith("https://");
}Commentary
This project is in its early stages and is currently developing interesting new features, such as multi-page PDF OCR capabilities by taking screenshots and feeding them to the vision model.
We can keep tracking its development.
Finally, if you’re interested in the series, feel free to check out my other articles.