


TableRAG

Table comprehension is a challenging task for language models (LMs), especially when working with large tables. In a previous article, I explored RAG applied to tables. Recently, I read a new paper and wanted to share it with everyone.
Traditional methods face limitations when handling large tables, especially due to LM context-length constraints. For example, popular models like GPT-4 struggle with tables that exceed tens of thousands of tokens, significantly hindering their ability to analyze large datasets efficiently. Prior approaches attempted to condense table data, but this often led to information loss or computational inefficiency when embedding entire rows and columns.
Imagine a table containing sales data for thousands of products, with information spanning categories, prices, and order statuses. Traditional LM-based methods would either attempt to process the entire table, risking token overload, or rely on truncated data, which could omit essential insights.
TableRAG introduces an innovative RAG framework that combines schema and cell retrieval to pinpoint essential information, bypassing the need to process entire tables. This approach allows LMs to retrieve only necessary data, minimizing token usage while preserving crucial insights.

The key differences between prior table prompting approaches and TableRAG is shown in Figure 1.
(a) Read Table: The LM processes the entire table, a method often impractical for large tables due to token limits.
(b) Read Schema: The LM only reads the table's schema (column names and types), which reduces context size but omits detailed content.
(c) Row-Column Retrieval: Rows and columns are encoded and filtered by relevance to the question, but encoding all rows and columns is still unmanageable for very large tables.
(d) Schema-Cell Retrieval (TableRAG): TableRAG encodes and retrieves only essential schema and cell values relevant to the question, offering a streamlined input that maximizes efficiency and accuracy.
(e) TableRAG’s approach (d) outperforms others, especially in retrieving both column and cell information effectively on the ArcadeQA dataset, enhancing reasoning and reducing token load.
TableRAG
TableRAG introduces a Retrieval-Augmented Generation (RAG) approach that combines schema retrieval and cell retrieval to access critical information from large tables without requiring the entire table in the prompt. This method leverages query-based retrieval to streamline token usage while preserving essential information.
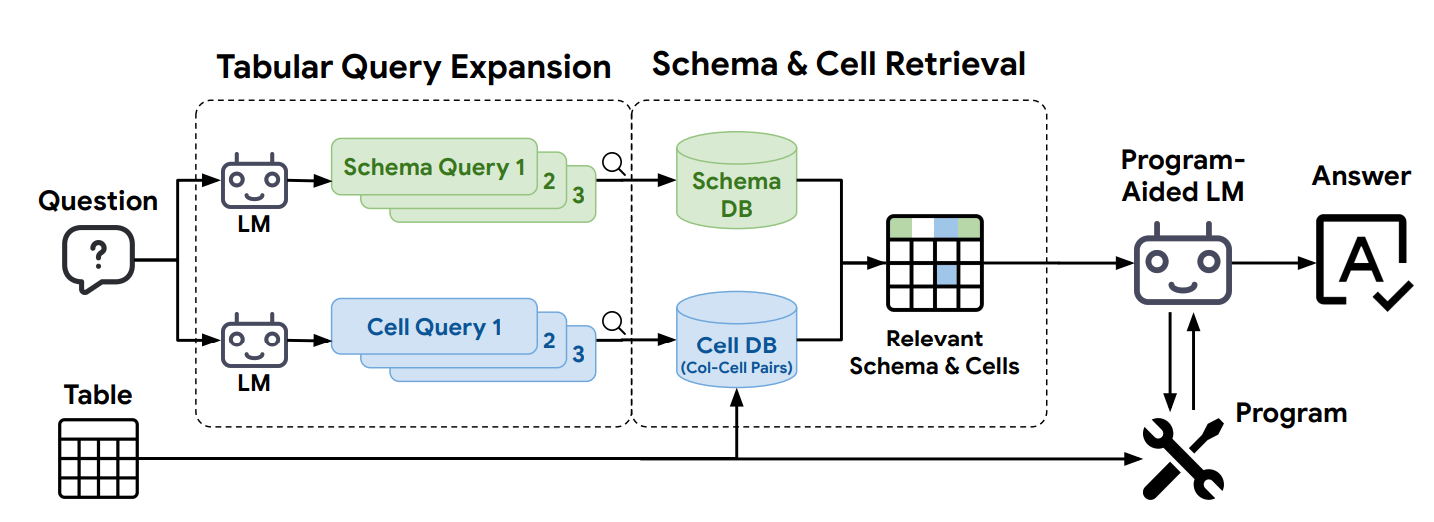
As shown in Figure 2, the table is used to construct the schema and cell databases. A question is expanded into multiple schema and cell queries by language models (LMs). These queries are then used sequentially to retrieve schemas and column-cell pairs. The top K candidates from each query are combined and incorporated into the LM solver's prompt to answer the question.
Core Components of TableRAG
Tabular Query Expansion
Tabular Query Expansion initiates the data retrieval process by generating separate queries for schema and cell values, enhancing retrieval precision. Unlike previous approaches that use a single question-based query, TableRAG expands the question into multiple, targeted queries for both schema and cell components.
For example, if asked, “What is the average price for wallets?”, TableRAG creates schema-related queries for columns like “product” and “price,” while cell queries focus on values like “wallet.” This two-pronged approach enables more relevant data extraction.


Schema Retrieval
Schema retrieval is the next step, focusing on retrieving the structural elements of the table, such as column names and data types, without requiring the model to encode all rows. Using an pre-trained encoder, TableRAG matches schema queries with encoded column names and ranks them based on their relevance to the question.
For instance, given the question “What is the average price for wallets?”, TableRAG might retrieve schema information for “product” and “price” columns, enabling efficient and accurate analysis.
For columns with numerical or datetime data types, TableRAG retrieves minimum and maximum values, while categorical columns display the three most frequent categories as examples. This process ensures that the LM receives an informative overview of the table structure at a minimal token cost.
Cell Retrieval
Cell retrieval further refines the information available to the LM by identifying relevant cell values within specific columns. This step builds a database of distinct column-value pairs, which significantly reduces the token count needed to represent the table, especially for large tables with millions of cells.
Cell retrieval is crucial in TableRAG, enhancing the language model’s (LM’s) ability to understand tables through:
Cell Identification: It allows LMs to accurately detect specific keywords within a table, essential for effective indexing. For example, it can differentiate between terms like "tv" and "television," ensuring searches and operations rely on precise data entries.
Cell-Column Association: It enables LMs to link specific cells to their corresponding column names, which is essential for handling questions about particular attributes. For instance, associating the term "wallet" with the "description" column facilitates accurate row indexing.
Cell Retrieval with Encoding Budget
However, to manage token usage efficiently, TableRAG employs an Encoding Budget B, a cap on the number of distinct cell values that can be encoded. This encoding budget ensures that TableRAG retrieves only the top-ranked values based on frequency and relevance.
If the table contains more distinct values than the set budget B, TableRAG selectively encodes only the most frequently occurring values.
For example, if analyzing a large product dataset, TableRAG would prioritize frequently appearing categories within “product” and “price” fields to remain within the encoding budget. This targeted retrieval helps the model maintain a low token count while preserving essential information for accurate responses.
Program-Aided Solver
The final component, the Program-Aided Solver, allows TableRAG to dynamically interact with the table data after retrieving the most relevant schema and cell values. This solver is compatible with programmatically enabled LM agents, like the ReAct framework, allowing TableRAG to perform calculations or apply logical operations based on the query.
For instance, if tasked with calculating an average, the Program-Aided Solver can filter for relevant entries and compute the answer without further manual intervention.
The corresponding prompt is shown in Figure 5.

Case Study

As shown in Figure 6, TableRAG’s workflow for the query “What is the average price for wallets?” includes several key steps, from query generation and relevant data retrieval to final computation.
Tabular Query Expansion: TableRAG first expands the user query into multiple sub-queries specifically targeting both schema and cell data. These sub-queries help identify relevant columns and keywords. For instance, schema queries generate terms like “product name,” “price,” and “category,” while cell queries target specific values such as “wallet.”
Schema Retrieval: In the schema retrieval stage, TableRAG uses a pre-trained encoder to retrieve relevant columns, such as the “price” column, along with its data type (e.g., string type). Example values like “$449” and “$399” are provided, helping the model understand the structure and data range of the table.
Cell Retrieval: During cell retrieval, TableRAG retrieves values directly relevant to the query from the cell database. For example, values in the “description” column that mention “wallet” are extracted. This step provides specific data points that complement the schema retrieval results and are essential for accurately answering the query.
Program-Aided LM: After gathering the necessary schema and cell data, TableRAG’s program-aided solver executes the data processing tasks. Using Python operations, the model first cleans the price column (removing symbols and converting strings to float values), then filters rows containing “wallet,” and finally calculates the average price across these entries to arrive at the answer.
This detailed process ensures that TableRAG effectively narrows the retrieval scope, only fetching schema and cell data directly relevant to the query. This approach reduces token usage, enhancing both efficiency and accuracy.
Evaluation
The TableRAG framework was rigorously tested on datasets (ArcadeQA and BirdQA) and consistently outperformed other retrieval approaches. Figure 7 provides a comprehensive comparison.

Conclusion and Insights
This article explored TableRAG, an innovative idea for large-scale table comprehension that achieves a balance between scalability and precision. By employing a retrieval-augmented approach with schema and cell retrieval, TableRAG minimizes token usage and computational costs, setting a new benchmark in table analysis for language models.
From my perspective, despite its strong performance, TableRAG has some limitations:
Dependency on Pre-encoded Structure: TableRAG’s schema and cell retrieval rely heavily on pre-encoded schema and cell data, which may pose challenges in dynamic or frequently changing datasets. For instance, when table structures or content changes significantly, re-encoding can add time and computational cost.
Encoding Budget Balance: While the encoding budget method effectively controls token usage, setting an optimal budget remains challenging in practice. A small budget may lead to information loss, while a larger budget could compromise efficiency.
In my opinion, possible future improvements could include:
Dynamic Encoding Mechanisms: Enhancing TableRAG to adapt its encoding process more flexibly in dynamic data environments could reduce reliance on pre-encoding.
Smarter Query Expansion: Optimizing schema and cell expansion based on user queries to improve retrieval precision.
Cross-Dataset Generalization: While TableRAG performs well across datasets, further validation in other domains, such as finance and healthcare, could enhance its versatility.