


MultiModal RAG Unveiled: A Deep Dive into Cutting-Edge Advancements

Recently, I’ve observed that research on multimodal RAG (Retrieval-Augmented Generation) is increasing. Therefore, I believe it’s crucial to offer a concise overview of this field. By clarifying our thoughts, we can better grasp future research directions and recognize the potential applications.
This article primarily introduces the main categories of current multimodal RAG, highlights some of the latest developments, and offers personal insights.
Classification of Multimodal RAG
Due to the flexibility of multimodal RAG, there are various ways to classify it.
Here, we classify multimodal RAG based on storage and retrieval modality. It can be divided into three categories: Image-based RAG, text-based RAG, and cross-modality-based RAG.
As illustrated in Figure 1, (a) and (c) can be classified as image-based RAG, while (b) represents text-based RAG. The difference between Figure 1 (a) and (c) is that (a) can only process single-page documents, while (c) can handle long documents.
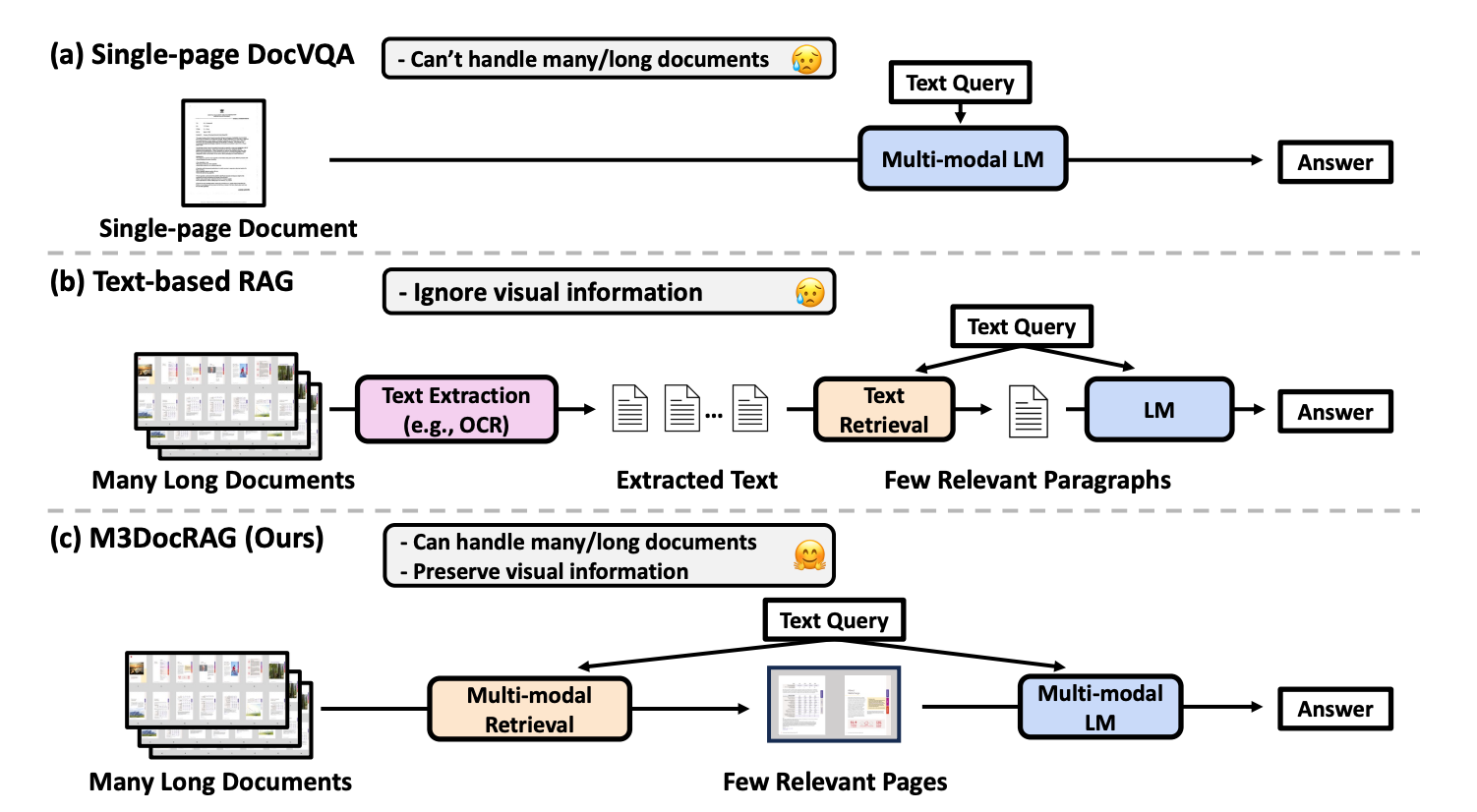
Cross-modality-based RAG are capable of storing and retrieving information across different modalities.

Figure 2 illustrates two distinct configurations of the cross-modality-based RAG pipeline, showcasing the integration of text and image modalities into the RAG system.
From an input source perspective, Figure 2(a) and (b) both utilize text and images extracted from PDF collections. The text undergoes embedding via a text embedding model (such as OpenAI’s text-embedding-3-small). In Figure 2(a), images are embedded using a multimodal embedding model (like CLIP). In contrast, Figure 2(b) processes images through a multimodal LLM to generate text summaries, which are then embedded using a text embedding model.
Regarding storage, Figure 2(a) maintains separate vector stores for text and image embeddings. Figure 2(b), however, stores both text embeddings and image-generated text summary embeddings in a single vector store.
For post-retrieval, both Figure 2(a) and (b) can feed the retrieved text and corresponding original images into a multimodal LLM to generate the final answer.
Next, let’s look at some specific examples of multimodal RAG implementation.
ColPali: The All-Seeing Document Retrieval That Understands Both Text and Image
Open source code: https://github.com/illuin-tech/colpali
Core Idea
When developing RAG systems, we often face this challenge: Can the system retrieve the correct document page for a given query?
Keep reading with a 7-day free trial
Subscribe to AI Exploration Journey to keep reading this post and get 7 days of free access to the full post archives.