


AI Innovations and Trends 06: Incremental Updates Functionality in GraphRAG, LLM-Aided OCR, and DocReLM

You can watch the video:
This article is the sixth in this series. Today we will explore three cutting-edge advancements in AI, which are:
Incremental Updates Functionality in GraphRAG
LLM-Aided OCR: Enhance OCR Output by Applying LLM Corrections
DocReLM: Intelligent Document Retrieval
Incremental Updates Functionality in GraphRAG
Previously, we discussed GraphRAG's important update—DRIFT Search, and today we'll look at another important update.
In my previous article, we introduced that GraphRAG's incremental updates functionality have not yet been implemented.
Recently, GraphRAG introduced incremental update functionality in its version 0.4.0. This feature now enables the updating of data on existing knowledge graphs without rebuilding the entire graph from scratch.
While writing this article, I discovered that the latest version is now 0.5.0.
Through initial analysis of the version 0.5.0 code, it was discovered that GraphRAG's incremental updates functionality is primarily concentrated in the update directory.
Detecting data changes: The get_delta_docs function compares the input dataset with the final documents in storage, identifying newly added and deleted documents.
async def get_delta_docs( input_dataset: pd.DataFrame, storage: PipelineStorage ) -> InputDelta: """Get the delta between the input dataset and the final documents. Parameters ---------- input_dataset : pd.DataFrame The input dataset. storage : PipelineStorage The Pipeline storage. Returns ------- InputDelta The input delta. With new inputs and deleted inputs. """ final_docs = await _load_table_from_storage( "create_final_documents.parquet", storage ) # Select distinct title from final docs and from dataset previous_docs: list[str] = final_docs["title"].unique().tolist() dataset_docs: list[str] = input_dataset["title"].unique().tolist() # Get the new documents (using loc to ensure DataFrame) new_docs = input_dataset.loc[~input_dataset["title"].isin(previous_docs)] # Get the deleted documents (again using loc to ensure DataFrame) deleted_docs = final_docs.loc[~final_docs["title"].isin(dataset_docs)] return InputDelta(new_docs, deleted_docs)The update_dataframe_outputs function is the core of the update phase in the pipeline. It's responsible for effectively merging new data with existing data. These output data typically represent the final results generated after multiple processing steps, including documents, entities, relationships, nodes, and communities.
These two functions are ultimately called in the run_pipeline_with_config function.
async def run_pipeline_with_config( config_or_path: PipelineConfig | str, workflows: list[PipelineWorkflowReference] | None = None, dataset: pd.DataFrame | None = None, storage: PipelineStorage | None = None, update_index_storage: PipelineStorage | None = None, cache: PipelineCache | None = None, callbacks: WorkflowCallbacks | None = None, progress_reporter: ProgressReporter | None = None, input_post_process_steps: list[PipelineWorkflowStep] | None = None, additional_verbs: VerbDefinitions | None = None, additional_workflows: WorkflowDefinitions | None = None, emit: list[TableEmitterType] | None = None, memory_profile: bool = False, run_id: str | None = None, is_resume_run: bool = False, is_update_run: bool = False, **_kwargs: dict, ) -> AsyncIterable[PipelineRunResult]: """Run a pipeline with the given config. Args: - config_or_path - The config to run the pipeline with - workflows - The workflows to run (this overrides the config) - dataset - The dataset to run the pipeline on (this overrides the config) - storage - The storage to use for the pipeline (this overrides the config) - cache - The cache to use for the pipeline (this overrides the config) - reporter - The reporter to use for the pipeline (this overrides the config) - input_post_process_steps - The post process steps to run on the input data (this overrides the config) - additional_verbs - The custom verbs to use for the pipeline. - additional_workflows - The custom workflows to use for the pipeline. - emit - The table emitters to use for the pipeline. - memory_profile - Whether or not to profile the memory. - run_id - The run id to start or resume from. """ if isinstance(config_or_path, str): log.info("Running pipeline with config %s", config_or_path) else: log.info("Running pipeline") run_id = run_id or time.strftime("%Y%m%d-%H%M%S") config = load_pipeline_config(config_or_path) config = _apply_substitutions(config, run_id) root_dir = config.root_dir or "" progress_reporter = progress_reporter or NullProgressReporter() storage = storage or _create_storage(config.storage, root_dir=Path(root_dir)) if is_update_run: update_index_storage = update_index_storage or _create_storage( config.update_index_storage, root_dir=Path(root_dir) ) cache = cache or _create_cache(config.cache, root_dir) callbacks = callbacks or _create_reporter(config.reporting, root_dir) dataset = ( dataset if dataset is not None else await _create_input(config.input, progress_reporter, root_dir) ) post_process_steps = input_post_process_steps or _create_postprocess_steps( config.input ) workflows = workflows or config.workflows if dataset is None: msg = "No dataset provided!" raise ValueError(msg) if is_update_run and update_index_storage: delta_dataset = await get_delta_docs(dataset, storage) # Fail on empty delta dataset if delta_dataset.new_inputs.empty: error_msg = "Incremental Indexing Error: No new documents to process." raise ValueError(error_msg) delta_storage = update_index_storage.child("delta") # Run the pipeline on the new documents tables_dict = {} async for table in run_pipeline( workflows=workflows, dataset=delta_dataset.new_inputs, storage=delta_storage, cache=cache, callbacks=callbacks, input_post_process_steps=post_process_steps, memory_profile=memory_profile, additional_verbs=additional_verbs, additional_workflows=additional_workflows, progress_reporter=progress_reporter, emit=emit, is_resume_run=False, ): tables_dict[table.workflow] = table.result progress_reporter.success("Finished running workflows on new documents.") await update_dataframe_outputs( dataframe_dict=tables_dict, storage=storage, update_storage=update_index_storage, config=config, cache=cache, callbacks=NoopVerbCallbacks(), progress_reporter=progress_reporter, ) else: ... ...
With its incremental update mechanism, GraphRAG efficiently maintains and updates knowledge graphs for large-scale datasets. This enhancement boosts the system's overall performance.
LLM-Aided OCR: Enhance OCR Output by Applying LLM Corrections
Open-source code: https://github.com/Dicklesworthstone/llm_aided_ocr
This project aims to transform raw OCR-scanned PDF text into highly accurate, properly formatted, and easily readable Markdown documents by leveraging the power of multimodal LLMs.
The codebase is concise, comprising only about 689 lines. The main function contains several key steps in the document processing workflow.
Environment Configuration and Logging Setup.
Model Download: If configured to use a local LLM, it calls the download_models function to download the model files, ensuring the necessary machine learning models are available locally for subsequent operations.
PDF File Processing: Calls the convert_pdf_to_images function to convert PDF files into images for OCR processing. Then uses OCR (via the ocr_image function) to extract text from each page image.
Text Post-processing: Uses LLMs to further process the OCR-extracted text, including error correction and format optimization, by calling the process_document function.
Saving Processed Results: Saves the original text extracted by OCR and the processed text to specified file paths.
Quality Assessment: Optionally performs a final quality assessment by comparing the pre- and post-processed text through the assess_output_quality function, providing a quality score and explanation to evaluate the effectiveness of the OCR and text processing workflow.
The corresponding prompt for enhancing the quality of OCR output is shown below.
async def process_chunk(chunk: str, prev_context: str, chunk_index: int, total_chunks: int, reformat_as_markdown: bool, suppress_headers_and_page_numbers: bool) -> Tuple[str, str]:
logging.info(f"Processing chunk {chunk_index + 1}/{total_chunks} (length: {len(chunk):,} characters)")
# Step 1: OCR Correction
ocr_correction_prompt = f"""Correct OCR-induced errors in the text, ensuring it flows coherently with the previous context. Follow these guidelines:
1. Fix OCR-induced typos and errors:
- Correct words split across line breaks
- Fix common OCR errors (e.g., 'rn' misread as 'm')
- Use context and common sense to correct errors
- Only fix clear errors, don't alter the content unnecessarily
- Do not add extra periods or any unnecessary punctuation
2. Maintain original structure:
- Keep all headings and subheadings intact
3. Preserve original content:
- Keep all important information from the original text
- Do not add any new information not present in the original text
- Remove unnecessary line breaks within sentences or paragraphs
- Maintain paragraph breaks
4. Maintain coherence:
- Ensure the content connects smoothly with the previous context
- Handle text that starts or ends mid-sentence appropriately
IMPORTANT: Respond ONLY with the corrected text. Preserve all original formatting, including line breaks. Do not include any introduction, explanation, or metadata.
Previous context:
{prev_context[-500:]}
Current chunk to process:
{chunk}
Corrected text:
"""
ocr_corrected_chunk = await generate_completion(ocr_correction_prompt, max_tokens=len(chunk) + 500)
processed_chunk = ocr_corrected_chunk
# Step 2: Markdown Formatting (if requested)
if reformat_as_markdown:
markdown_prompt = f"""Reformat the following text as markdown, improving readability while preserving the original structure. Follow these guidelines:
1. Preserve all original headings, converting them to appropriate markdown heading levels (# for main titles, ## for subtitles, etc.)
- Ensure each heading is on its own line
- Add a blank line before and after each heading
2. Maintain the original paragraph structure. Remove all breaks within a word that should be a single word (for example, "cor- rect" should be "correct")
3. Format lists properly (unordered or ordered) if they exist in the original text
4. Use emphasis (*italic*) and strong emphasis (**bold**) where appropriate, based on the original formatting
5. Preserve all original content and meaning
6. Do not add any extra punctuation or modify the existing punctuation
7. Remove any spuriously inserted introductory text such as "Here is the corrected text:" that may have been added by the LLM and which is obviously not part of the original text.
8. Remove any obviously duplicated content that appears to have been accidentally included twice. Follow these strict guidelines:
- Remove only exact or near-exact repeated paragraphs or sections within the main chunk.
- Consider the context (before and after the main chunk) to identify duplicates that span chunk boundaries.
- Do not remove content that is simply similar but conveys different information.
- Preserve all unique content, even if it seems redundant.
- Ensure the text flows smoothly after removal.
- Do not add any new content or explanations.
- If no obvious duplicates are found, return the main chunk unchanged.
9. {"Identify but do not remove headers, footers, or page numbers. Instead, format them distinctly, e.g., as blockquotes." if not suppress_headers_and_page_numbers else "Carefully remove headers, footers, and page numbers while preserving all other content."}
Text to reformat:
{ocr_corrected_chunk}
Reformatted markdown:
"""
processed_chunk = await generate_completion(markdown_prompt, max_tokens=len(ocr_corrected_chunk) + 500)
new_context = processed_chunk[-1000:] # Use the last 1000 characters as context for the next chunk
logging.info(f"Chunk {chunk_index + 1}/{total_chunks} processed. Output length: {len(processed_chunk):,} characters")
return processed_chunk, new_context
Overall, this project involves integrating OCR technology with LLMs for document processing, represents a technically advanced and practically valuable direction.
DocReLM: Intelligent Document Retrieval
Next, let's examine a RAG approach dedicated to addressing challenges in literature retrieval. I have detailed this method in my previous article, and now I have some new insights.
Current document retrieval systems like Google Scholar lack deep semantic understanding in specialized fields, leading to poor search results. When searching for topics like "quantum entanglement," these systems rely on simple keyword matching rather than understanding complex domain concepts, resulting in many irrelevant results.
DocReLM aims to bridge this gap by leveraging LLMs to enhance the semantic understanding of document retrieval. It is designed to address three major challenges:
The complexity of domain-specific academic language.
The intricate relationships between references in academic papers.
Users’ imprecise queries.
Architecture
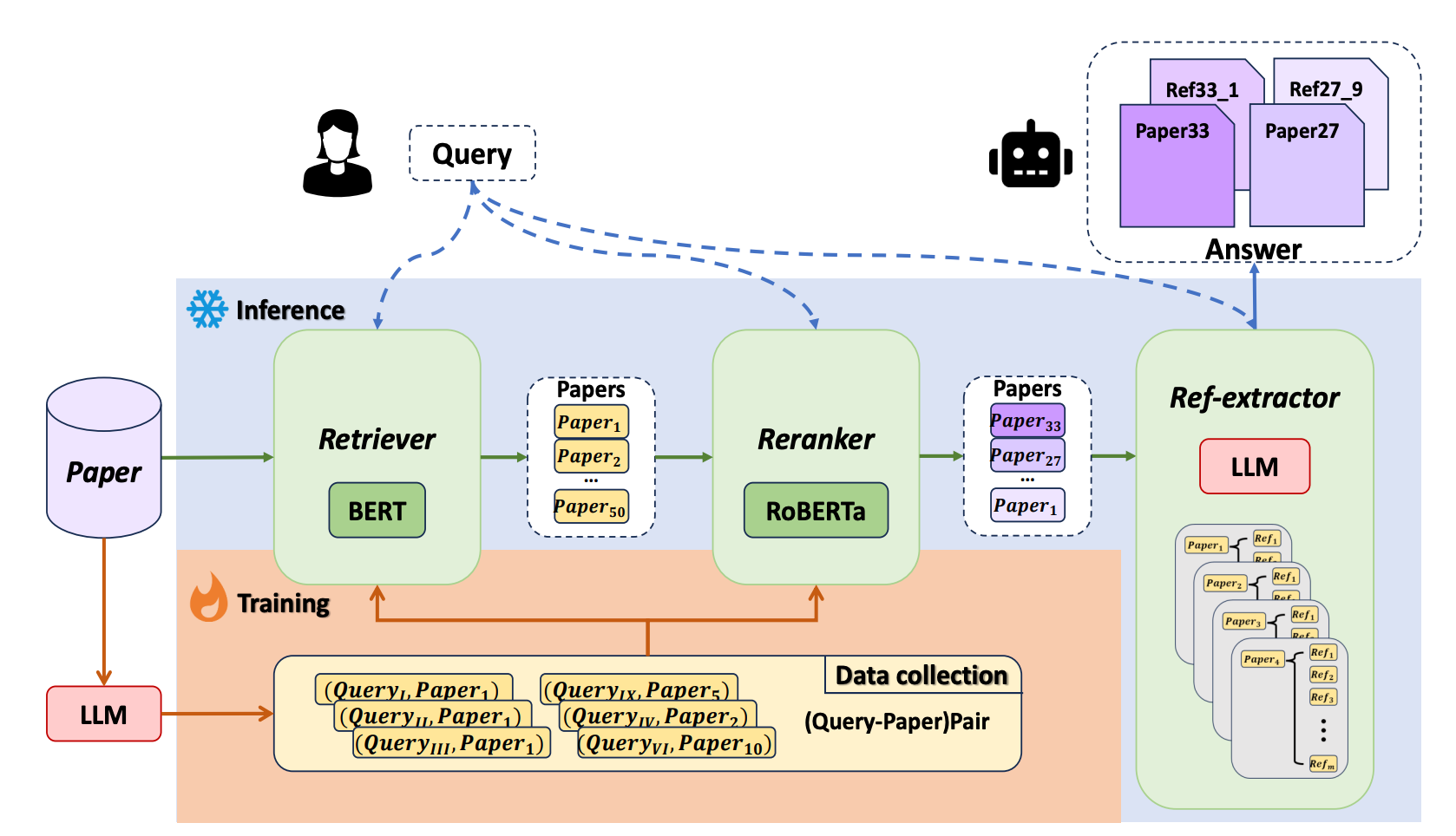
DocReLM uses LLMs to enhance document retrieval through three components:
The retriever quickly finds relevant documents using algorithms such as BM25 for sparse retrieval and advanced neural models for dense retrieval.
The reranker improves results by scoring query-passage pairs using cross-encoder.
The reference extractor analyzes citations in top documents to find additional relevant papers. This module uses LLMs to identify and extract relevant paper identifiers from the references, similar to how researchers follow citation trails.
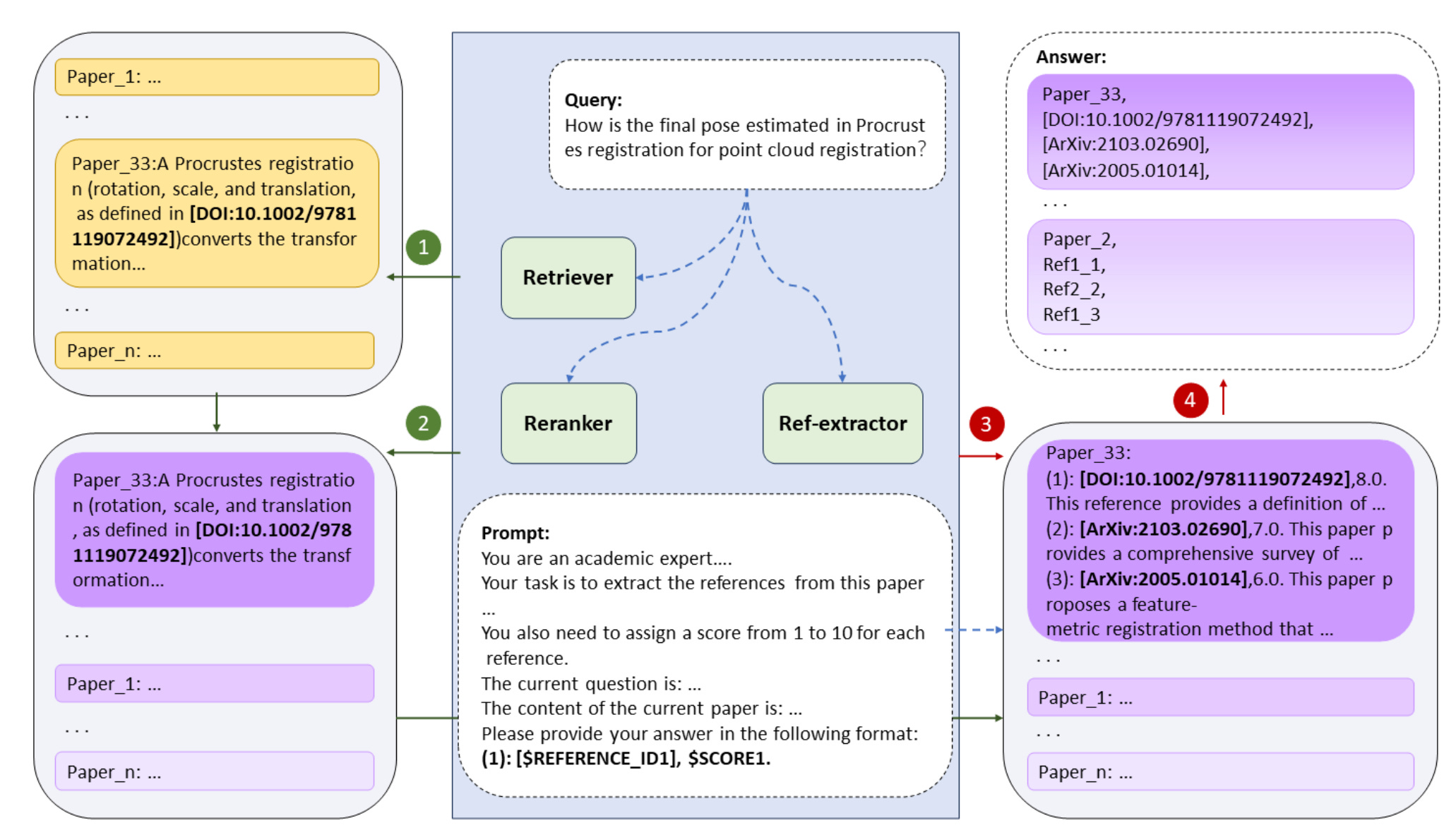
Commentary
From my perspective, the introduction of LLM-powered reference extraction is useful. This method could be expanded to other applications, such as legal document retrieval or patent analysis, where understanding the relationships between documents is crucial.
In addition, DocReLM demonstrates how LLMs can not only generate content but also improve smaller models' performance through knowledge distillation. This hybrid approach offers cost efficiency.
However, there are still room for improvement.
Introducing an LLM-powered dynamic query expansion mechanism could help users better express their needs. The system could dynamically adjust queries during retrieval, similar to "smart search suggestions," and interactively generate queries that better align with user intent based on their feedback.
Users need to understand why papers are recommended. A transparency feature showing matching text and context would build trust.
Fine-tuning this model to work in non-academic domains may require significant adaptation due to differences in language and citation practices.
Conclusion
We explored three key AI advancements.
GraphRAG's incremental updates enable efficient knowledge graph maintenance without full rebuilds, saving time and resources for dynamic data management.
LLM-aided OCR enhances digitized text processing by improving OCR accuracy and readability.
DocReLM improves document retrieval by better understanding academic language and reference relationships.
These innovations reflect AI's evolution toward smarter, context-aware systems that meet specific needs.
Finally, if you’re interested in the series, feel free to check out my other articles.