
Unlocking DocReLM: A Dive into the Three Core Modules Powering Intelligent Document Retrieval

Today, let's examine a Retrieval-Augmented Generation (RAG) approach dedicated to addressing challenges in literature retrieval.
The rapidly expanding corpus of academic literature, now exceeding 200 million published documents and growing annually by millions of new entries, presents significant challenges for researchers trying to keep up with developments in their fields.
Existing document retrieval systems, such as Google Scholar, often struggle with semantic understanding, particularly in domains requiring specialized knowledge, which leads to suboptimal performance in retrieving the most relevant academic papers.
For example, when searching for a research paper on a specific topic like "quantum entanglement," a system like Google Scholar may present numerous results, many of which are only tangentially related due to its reliance on keyword matching. Such systems fail to grasp the underlying semantic relationships between concepts in complex domains. This highlights a fundamental issue: current systems are not equipped to understand the intricacies of domain-specific language, which hinders their ability to retrieve the most relevant papers efficiently.
In response, DocReLM aims to bridge this gap by leveraging large language models (LLMs) to enhance the semantic understanding of document retrieval. The system is designed to address three major challenges:
The complexity of domain-specific academic language.
The intricate relationships between references in academic papers.
Users’ imprecise queries.
System Architecture

As shown in Figure 1, DocReLM's architecture is designed to optimize document retrieval by leveraging LLMs through three primary components: retriever, reranker, and reference extractor.
The retriever is the initial module that rapidly identifies relevant documents from a vast corpus. This process utilizes algorithms such as BM25 for sparse retrieval and advanced neural models for dense retrieval, enhancing the system’s ability to connect semantically similar content.
The reranker refines the initial results. It operates as a cross-encoder, analyzing the concatenated query-passage pairs to produce a relevance score for each. This enhances interaction between the query and the document content, leading to more accurate rankings of the retrieved passages.
The reference extractor enriches the results by examining the references within the top-ranked documents. This module uses LLMs to identify and extract relevant paper identifiers from the references, effectively mimicking a researcher’s natural process of following citation trails to uncover additional pertinent literature.
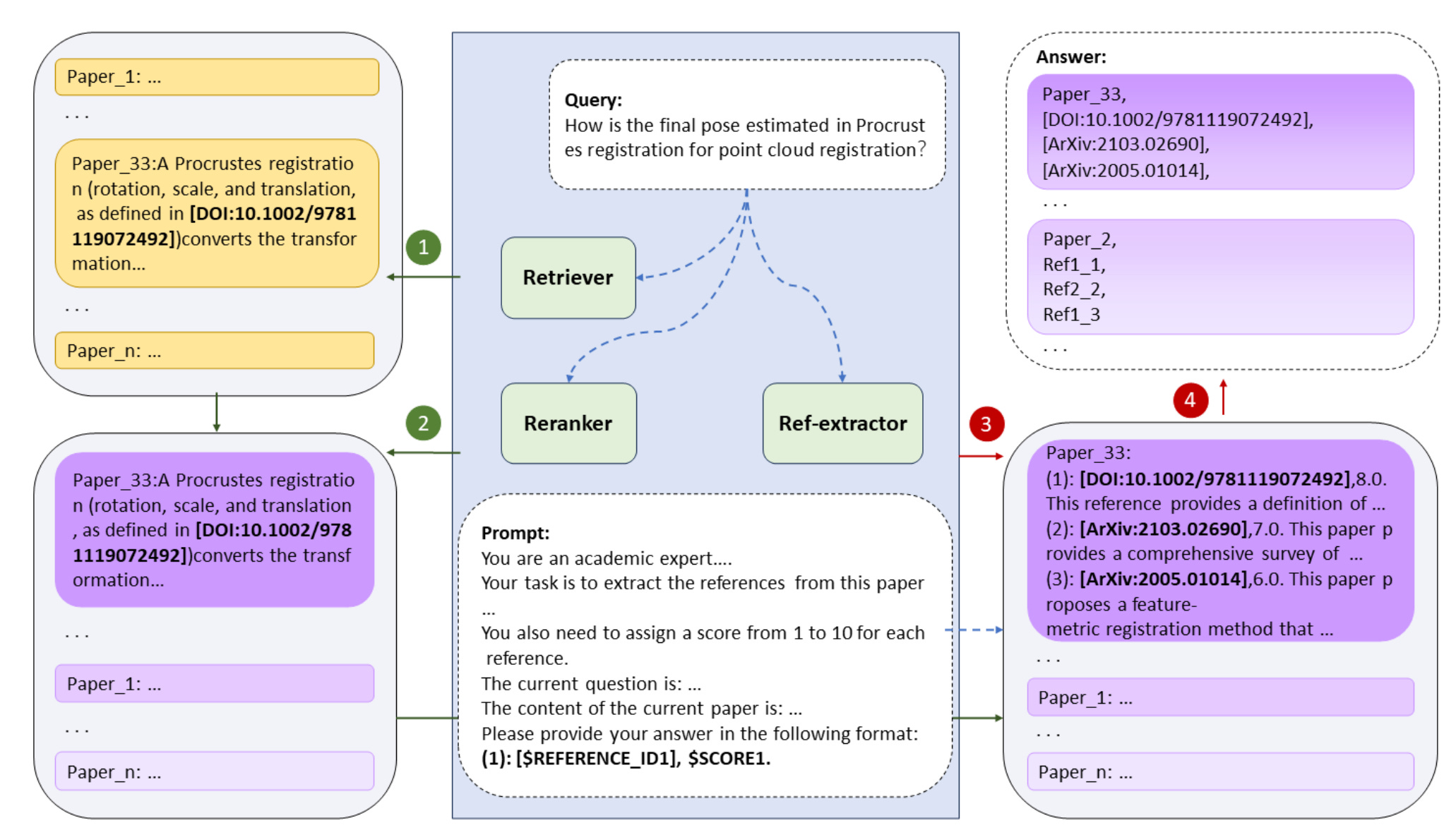
Overall, the integration of these components allows DocReLM to achieve superior retrieval accuracy by understanding both the context of queries and the relationships among academic papers.
Conclusion and Insights
This article explores how DocReLM uses large language models to revolutionize academic document retrieval. By combining dense retrievers, rerankers, and reference extractors, the system addresses key limitations in existing retrieval technologies.
From my perspective, the introduction of LLM-powered reference extraction is particularly noteworthy. This method could be expanded to other applications, such as legal document retrieval or patent analysis, where understanding the relationships between documents is crucial. However, fine-tuning this model to work in non-academic domains may require significant adaptation due to differences in language and citation practices.