


AI Innovations and Trends 03: LightRAG, Docling, DRIFT, and More

This article is the third in this series. Today we will look at four advancements in AI, which are:
LightRAG: Simple and Fast RAG
Docling: Efficient PDF Parsing with Layout Analysis and Structure Recognition
The DRIFT Search Feature of GraphRAG
Long-Context LLMs Meet RAG
LightRAG: Simple and Fast RAG
Open source code: https://github.com/HKUDS/LightRAG
Overview
LightRAG is a Retrieval-Augmented Generation (RAG) framework that enhances language model responses by integrating graph structures into text indexing and retrieval, improving contextual relevance and response coherence.
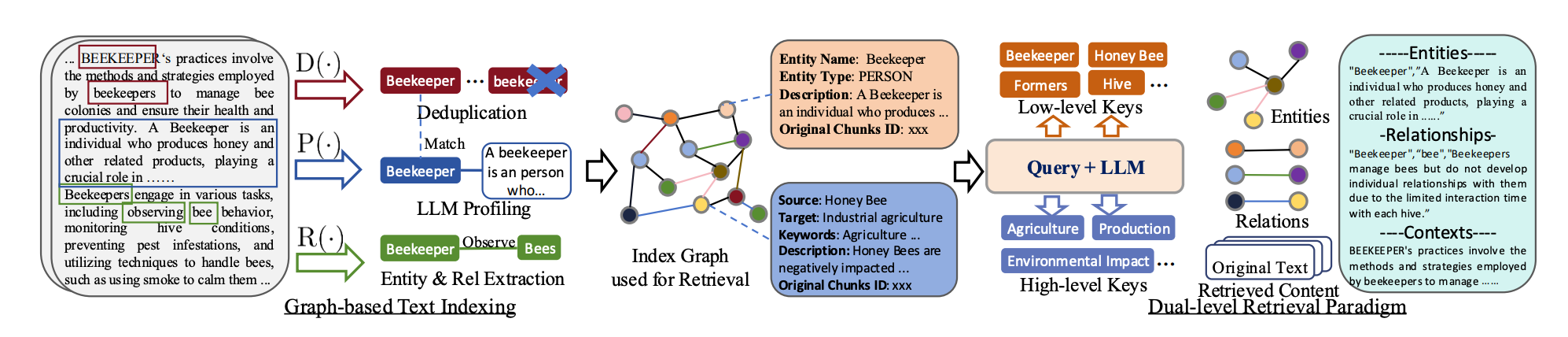
LightRAG employs a dual-level retrieval system, using both low-level and high-level data retrieval to better capture detailed and abstract information, thus addressing complex user queries comprehensively.
The model's graph-based approach enables efficient retrieval of related entities and relationships, significantly reducing response time while maintaining information richness and contextual understanding.
Additionally, LightRAG is designed to adapt quickly to new data through an incremental update mechanism, ensuring that the model remains relevant in dynamic, evolving data environments.
LightRAG demonstrates superior performance over NaiveRAG in terms of comprehensiveness, empowerment, and diversity, as shown in a case study on indigenous perspectives in corporate mergers.
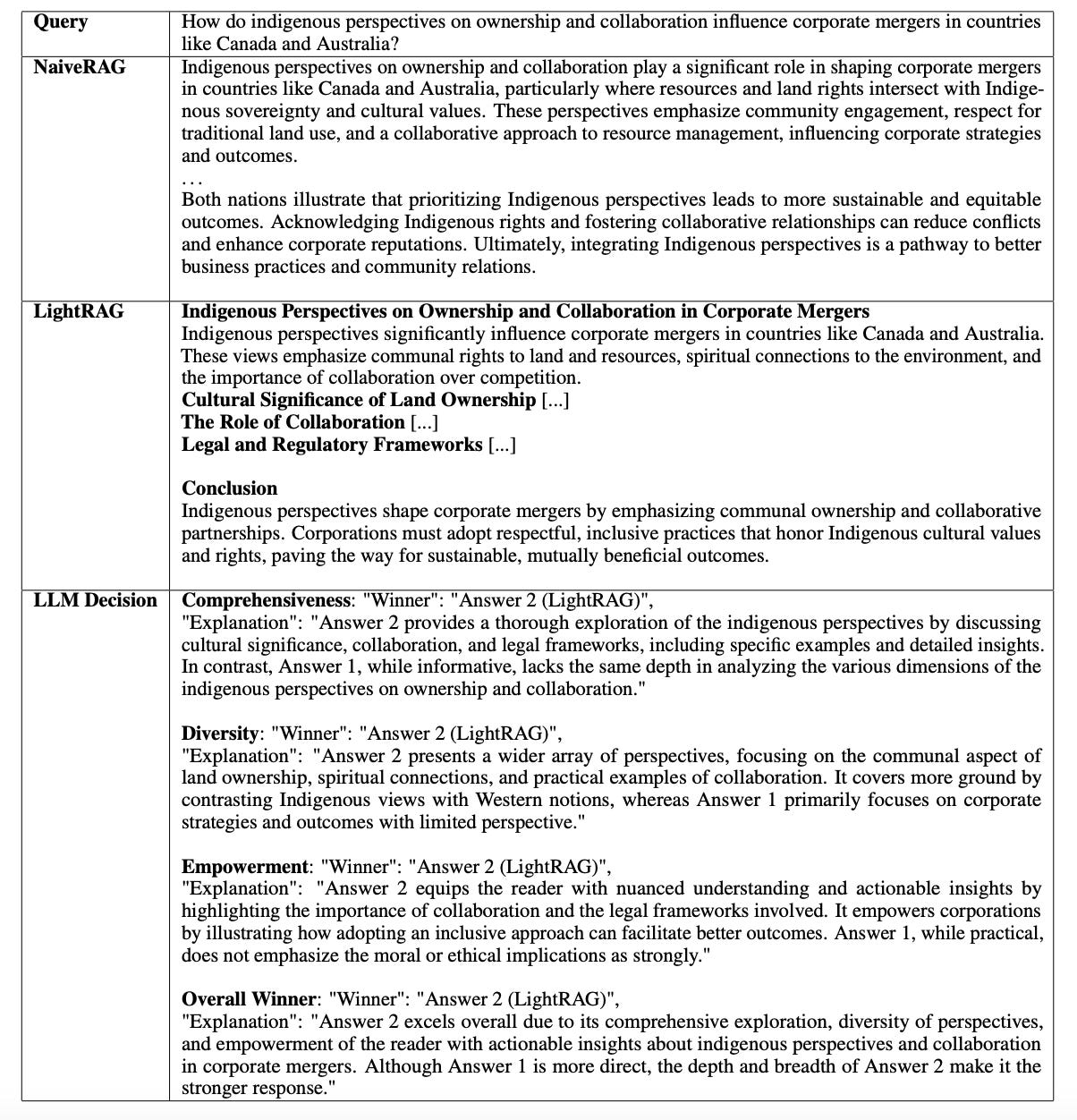
LightRAG delves deeper into key themes like cultural significance, collaboration, and legal frameworks, offering specific examples to support its insights. NaiveRAG, while informative, lacks this depth. The dual-level retrieval in LightRAG enables a thorough exploration of entities and relationships, effectively capturing the topic’s complexities and broader themes.
Comments and Insights: LightRAG vs. GraphRAG
Since both use a graph structure, what is the relationship between LightRAG and this year's popular GraphRAG?
Technical Inheritance: LightRAG is an improved version of GraphRAG. Both use graph structures to represent entities and relationships, enhancing the contextual understanding in information retrieval.
Retrieval Strategy: GraphRAG uses community traversal, retrieving information by traversing each community individually. This approach works well for broad queries but has a high computational cost. LightRAG, on the other hand, adopts a dual-level retrieval strategy, consisting of low-level and high-level retrieval, to handle both detailed and abstract information, making it more efficient for complex queries.
Computational Efficiency: GraphRAG has low efficiency when processing dynamic data updates, as it requires reconstructing the entire community structure, which is computationally expensive. LightRAG reduces this overhead significantly through an incremental update mechanism that allows rapid adaptation without re-indexing.
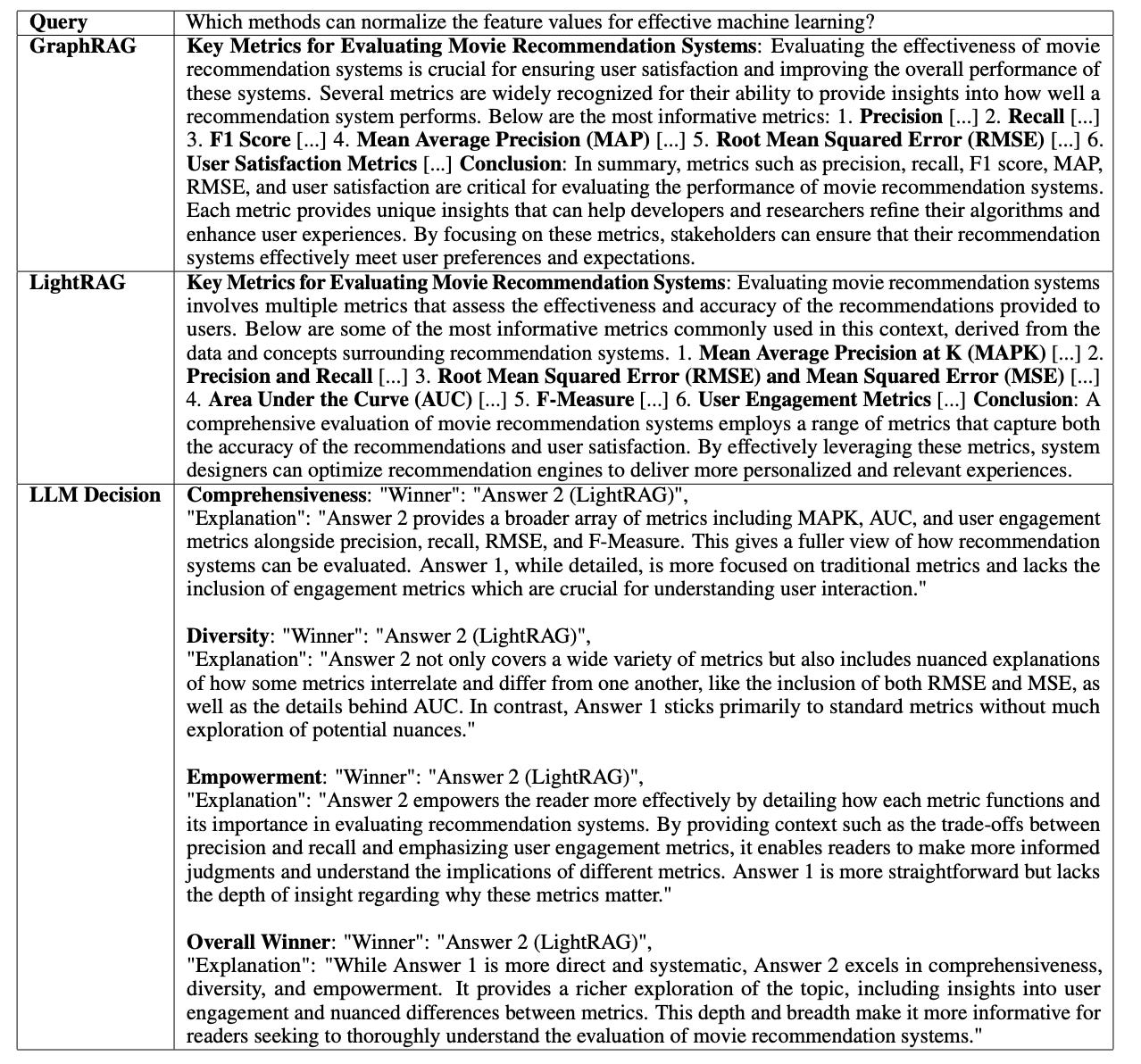
Response Diversity and Comprehensiveness: GraphRAG primarily focuses on global information, while LightRAG’s dual-level retrieval mechanism enhances response diversity and comprehensiveness by covering both detailed and higher-level thematic information, as shown in Figure 3.
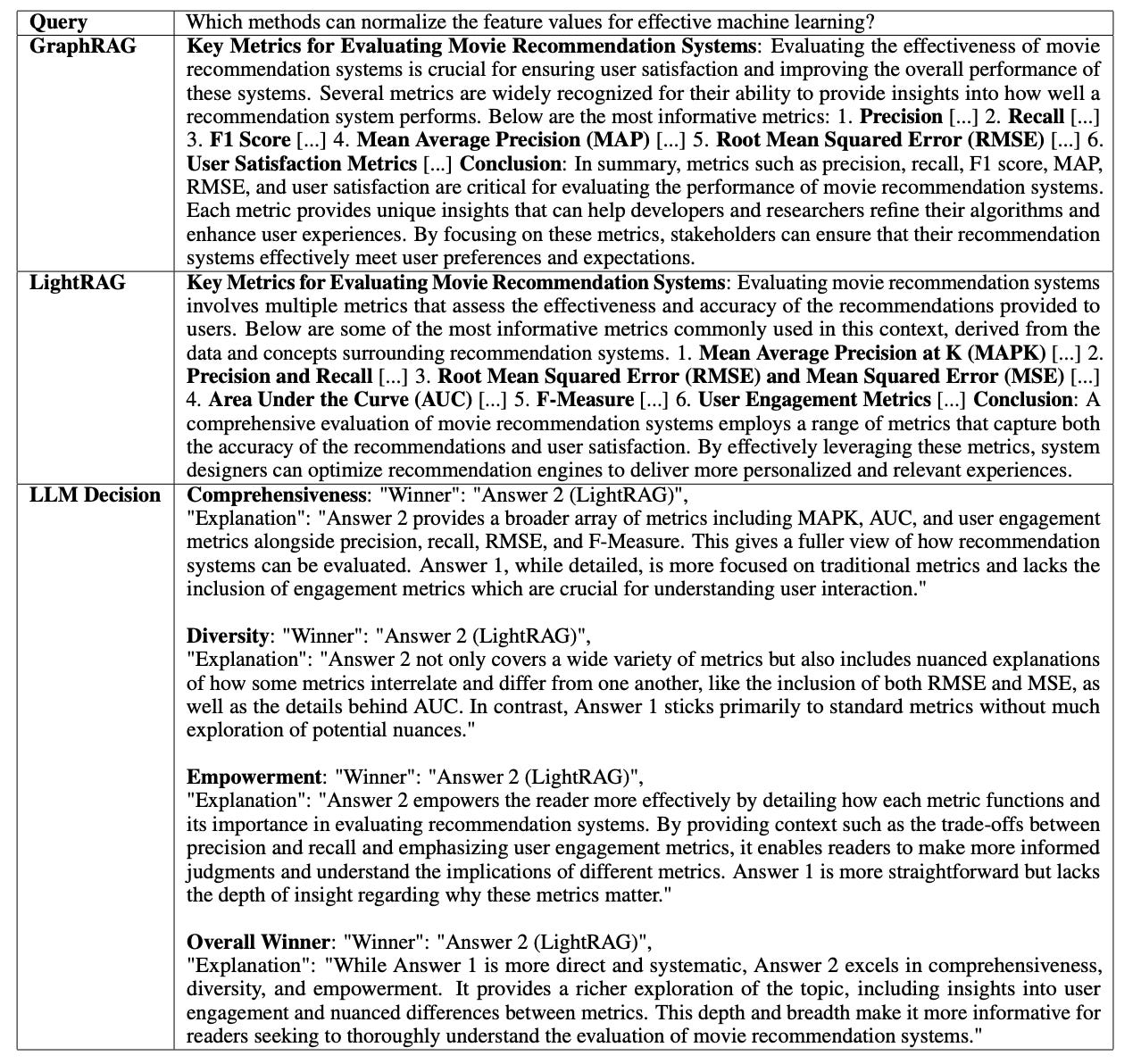
Figure 3: Case Study: Comparison Between LightRAG and the Baseline Method GraphRAG. Source: LightRAG.
Docling: Efficient PDF Parsing with Layout Analysis and Structure Recognition
Open source code: https://github.com/DS4SD/docling
Overview
Docling implements a linear document processing pipeline.

Each document is first parsed by a PDF backend, which extracts text content and coordinates from each page and generates bitmap images to support subsequent operations. Next, the model pipeline independently applies AI models on each page to extract content features such as layout and table structures. Finally, results from all pages are aggregated, and a post-processing stage adds metadata, detects language, infers reading order, and assembles a document object that can be serialized into JSON or Markdown.
Layout Analysis Model
The layout analysis model in Docling is an object detector that predicts bounding boxes and classes of elements on a page image. Based on RT-DETR architecture and retrained on the DocLayNet dataset, it processes page images at 72 dpi with sub-second latency on a single CPU.
Table Structure Recognition
The TableFormer model, a vision-transformer model for table structure analysis, identifies logical row and column structures, categorizing cells as headers or body. Detected table objects are fed to TableFormer, which processes tables in 2-6 seconds on a CPU.
OCR
Docling includes optional OCR support, particularly for scanned PDFs or embedded bitmaps. It uses EasyOCR, running at 216 dpi to capture fine details, though it can be slow (around 30 seconds per page on CPU).
Evaluation
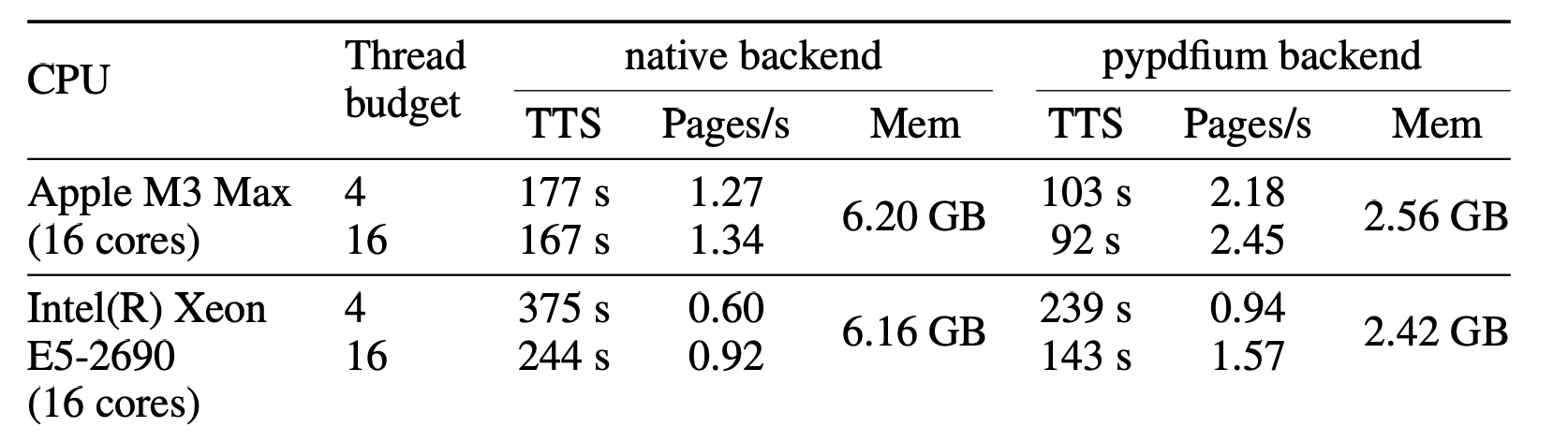
Measurements were taken on two hardware systems: a MacBook Pro M3 Max and a server running Ubuntu 20.04 LTS with an Intel Xeon E5-2690 CPU. The thread budget was fixed at 4 (default) and 16 (equal to the core count of the test hardware), with results shown in Figure 5.
Comments and Insights
In general, when designing our own document parsing tool, we can refer to Docling's pipeline process. Some of Docling's key models can be replaced with smaller models that we train ourselves.
Additionally, Docling's optimization approach for multi-threading is worth referencing.
The DRIFT Search Feature of GraphRAG
DRIFT Search (Dynamic Reasoning and Inference with Flexible Traversal) is an extension of GraphRAG, enhancing local search efficiency by incorporating community information. It combines global and local search methods, generating more detailed responses.
DRIFT offers a three-phase process:
An initial comparison of the query with top community reports for broad answers and guiding questions;
Refined local searches for intermediate answers, enriching context;
A hierarchical, relevance-ranked output of questions and answers.

This process integrates community insights, enhancing local search and ensuring the final results are both extensive and specific.
In benchmarking DRIFT against local search, DRIFT showed superior performance in comprehensiveness (78%) and diversity (81%).
Comments and Insights
Balancing between global search and local search in GraphRAG has always been a challenge. By incorporating community information, DRIFT Search broadens the starting point for local searches, making responses more diverse and relevant.
DRIFT shows promise in scenarios requiring layered and detailed responses and may drive RAG systems toward more adaptive architectures.
Long-Context LLMs Meet RAG
In my previous articles, we introduced the relevant content about long-text LLMs and RAG. Here, let's look at a new study.
In long-context LLMs, as the number of retrieved passages increases, the model's performance initially improves but then begins to decline. This phenomenon is mainly attributed to the disruptive effect of retrieved "hard negatives."
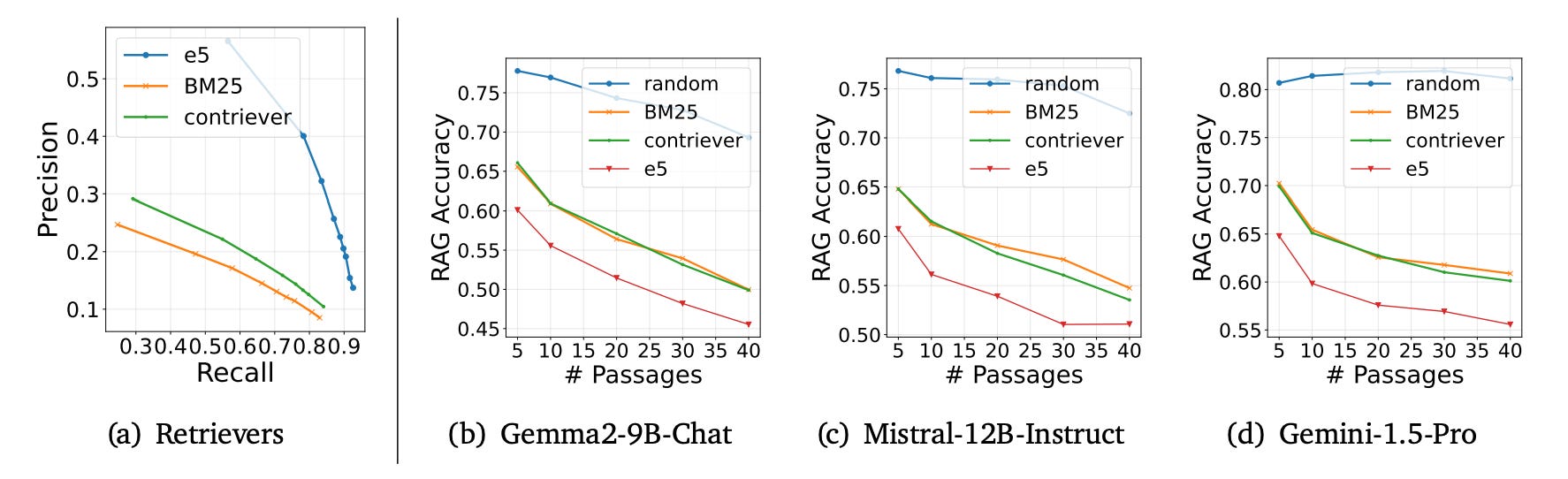
"Hard negatives" refer to retrieved passages or documents that are highly similar or contextually relevant to the query but do not contain the correct answer or relevant information. These passages can be misleading for the model because they appear closely related to the topic or query but, in fact, provide incorrect or irrelevant information.
Strategies
Through a series of experiments, this study analyzes the causes of this phenomenon and proposes several strategies to improve the robustness and output quality of long-context LLMs in RAG tasks:
Retrieval Reordering: Based on the “lost-in-the-middle” phenomenon, this strategy suggests positioning high-scoring retrieved documents at the beginning and end of the input sequence. By prioritizing key information in these positions, the model can more effectively focus on relevant content, reducing the impact of "hard negatives"—highly similar but incorrect information that disrupts model performance.
Implicit Robustness Fine-tuning: Since LLMs do not explicitly acquire the ability to handle noise during standard training, the study introduces a fine-tuning method using retrieved content with noise (including potentially irrelevant information). This method enables the model to exhibit greater robustness when encountering “hard negatives.”
Explicit Relevance Fine-tuning: While implicit fine-tuning enhances robustness, it does not explicitly train the model to identify relevant documents. Therefore, the study proposes adding an intermediate reasoning step, allowing the model to first analyze and identify relevant information before generating the final output, thus improving accuracy in detecting and utilizing relevant content within the retrieved context.
It also suggests further exploration of automated retrieval ordering optimization and fine-tuning LLMs with more granular, multi-step reasoning chains to enhance their application capabilities in RAG tasks.
Finally, if you’re interested in the series, feel free to check out my other articles.