


AI Innovations and Trends 05: iText2KG, Meta-Chunking, and gptpdf

This article is the fifth in this series. Today we will explore three advancements in AI, which are:
iText2KG: Building Topic-Independent Knowledge Graphs Incrementally with LLMs
Meta-Chunking: The Art of Cutting Text with Logic, Not Scissors
gptpdf: A concise PDF parsing tool
iText2KG: Building Topic-Independent Knowledge Graphs Incrementally with LLMs
Open-source code: https://github.com/AuvaLab/itext2kg
Comparison
Those who worked on knowledge graph projects before the era of LLMs are well aware of the challenges involved in building knowledge graphs at that time.
Since the advent of the LLM era, LLM-based solutions for building Knowledge Graphs (KGs) can be categorized into three paradigms: ontology-guided, fine-tuning, and zero- or few-shot learning.

Overall, these methods have distinct advantages and limitations, requiring careful consideration based on application scenarios.
Ontology-based methods perform well in specific domains, efficiently extracting structured information, but their generalizability is limited, making them less suitable for diverse scenarios and domain-specific knowledge.
Fine-tuning methods are highly flexible and can adapt to various tasks while leveraging domain data to enhance performance, but they are resource-intensive and costly to train.
Zero-/few-shot methods are resource-efficient, requiring no annotated datasets or domain-specific fine-tuning, making them ideal for quickly adapting to new tasks. However, challenges remain with unresolved and semantically duplicated entities and relations, resulting in inconsistent graphs and requiring post-processing. Additionally, most approaches are topic-dependent.
iText2KG
iText2KG is a zero-shot, incremental knowledge graph construction method that eliminates the need for post-processing, adapts to various scenarios, and boasts a modular design.

Document Distiller: This module leverages LLMs to rewrite input documents into semantic blocks based on a user-defined schema, which acts as a flexible blueprint rather than a rigid ontology. It reduces noise and guides graph construction by extracting key concepts and organizing data into structured formats, such as JSON.
Incremental Entities Extractor: The iEntities Matcher extracts entities iteratively from semantic blocks, maintaining a global entity set by comparing new entities with existing ones using cosine similarity. Unique entities are either added directly or matched with existing ones based on similarity thresholds.
Incremental Relations Extractor: The iRelations Matcher identifies relations between global entities using semantic blocks as context, with options for either global or local context to balance richness and relevance. Global context enriches the graph with implied relations but risks irrelevant links, while local context focuses on explicitly stated relations for precision.
Graph Integrator: Global entities and relations are integrated into Neo4j to build the final knowledge graph. This step visualizes and organizes the extracted information into a structured, queryable format.
Commentary
I conducted a simple test using iText2KG's open-source code, building a knowledge graph from a novel. Here are my key observations:
The LLM's capability significantly impacts the quality of the knowledge graph; more advanced LLMs produce better results.
The processing speed is relatively slow.
iText2KG's approach shows promise, but to become a viable product, it needs improvements in areas such as processing large-scale unstructured text more efficiently and offering a wider range of user scenario tests.
Meta-Chunking: The Art of Cutting Text with Logic, Not Scissors
Comparison
Chunking has long been a crucial stage in mainstream RAG systems, and I've explored this topic multiple times before.

I created a table comparing the currently popular chunking methods, as shown in Figure 4.

Meta-Chunking
Meta-Chunking is a novel text segmentation approach designed to balance granularity between sentences and paragraphs, enhancing logical coherence. This method allows for dynamic adjustment of chunk sizes, ensuring logical integrity while maintaining efficiency.
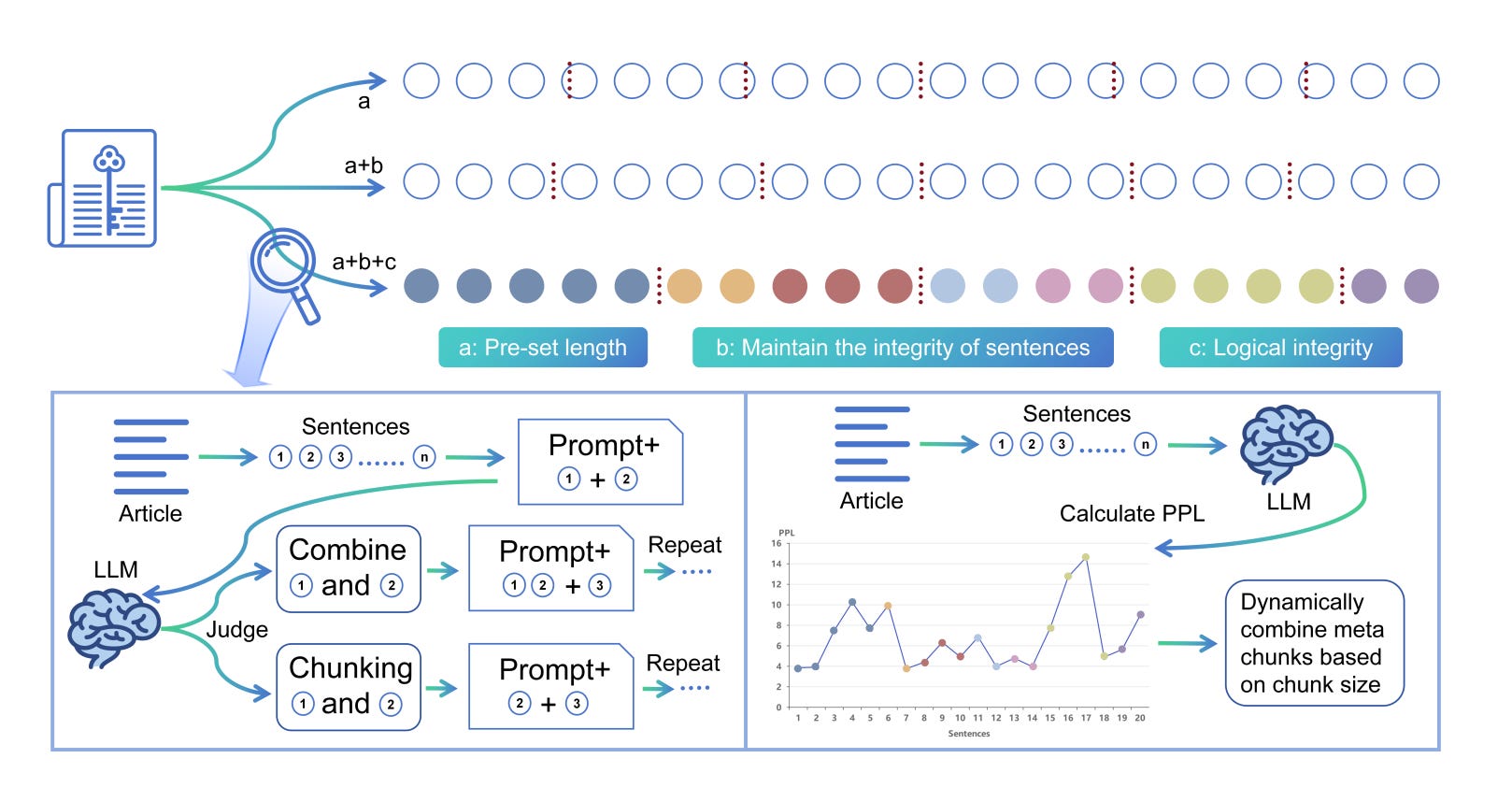
Meta-Chunking introduces two strategies:
Margin Sampling Chunking evaluates whether consecutive sentences should be segmented based on the probability difference of binary classification performed by a language model. The decision is guided by a threshold that adjusts dynamically, enabling smaller models to make effective segmentation decisions with reduced reliance on model size.
Perplexity Chunking calculates the perplexity of each sentence in its context to detect significant changes in perplexity distribution, identifying optimal segmentation points. By analyzing minima in the perplexity sequence, it pinpoints logical breaks while maintaining contextual coherence.
Both methods aim to enhance segmentation quality by leveraging logical and linguistic connections, surpassing traditional rule-based and semantic approaches.
Commentary
Meta-Chunking excels in improving logical coherence and chunking efficiency.
In my opinion, there are challenges for real-world deployment:
Dynamic Adaptability: The dependence on threshold tuning (e.g., perplexity threshold) for different datasets suggests the need for automatic parameter adjustment mechanisms.
Computational Cost: LLM dependence may require optimization for hardware resources. While smaller models are explored, further optimizing for lightweight models could improve deployment feasibility.
User-Centric Features: In real-world applications, users may have specific requirements for chunking granularity. Enhancing user customization options would be beneficial.
gptpdf: A Concise PDF Parsing Tool
Open source code: https://github.com/CosmosShadow/gptpdf
Core Idea
This tool's idea is very simple, It first parses PDF pages to extract images, drawings, and text regions, saving each region as a separate image. Then, it uses a language model to generate markdown content. Finally, it outputs a markdown file and a list of images for further processing or display.
The language model can be configured, with GPT-4o as the default.
GPT-4o's default prompt is in Chinese, I used a translation tool to translate it into English:
DEFAULT_PROMPT = """Using markdown syntax, convert the recognized text from the image into markdown format. You must ensure:
1. The output language should match the recognized language in the image. For example, if the recognized text is in English, the output must also be in English.
2. Do not provide explanations or include irrelevant text; output only the content from the image. For example, do not output phrases like "Here is the markdown text generated from the image content:" Instead, directly output the markdown.
3. Do not enclose content in ```markdown```. Use $$ $$ for block formulas, $ $ for inline formulas, and ignore long lines and page numbers.
Again, do not explain or include unrelated text; output only the content from the image directly.
"""
DEFAULT_RECT_PROMPT = """In the image, some areas are marked with red rectangles and names (%s).
If an area is a table or an image, insert it into the output content using the format ![](). Otherwise, directly output the text content.
"""
DEFAULT_ROLE_PROMPT = """You are a PDF document parser that outputs image content using markdown and LaTeX syntax.
"""
In addition, we can pass custom prompts. Here is an example:
prompt = {
"prompt": "Custom prompt text",
"rect_prompt": "Custom rect prompt",
"role_prompt": "Custom role prompt"
}
content, image_paths = parse_pdf(
pdf_path=pdf_path,
output_dir='./output',
model="gpt-4o",
prompt=prompt,
verbose=False,
)
Usage
gptpdf can be used standalone or integrated into existing RAG workflows.
from gptpdf import parse_pdf
api_key = 'Your OpenAI API Key'
content, image_paths = parse_pdf(pdf_path, api_key=api_key)
print(content)Commentary
This tool is simple to use and easy to integrate.
Developers with an interest in PDF parsing solutions should keep it on their radar.
Conclusion
The advancements discussed—iText2KG, Meta-Chunking, and gptpdf—highlight the growing sophistication in leveraging LLMs for practical applications.
Finally, if you’re interested in the series, feel free to check out my other articles.