


AI Innovations and Trends 07: Anthropic RAG, Chonkie, and A Hybrid RAG System

You can watch the video:
Hey there! Welcome to the 7th article in this exciting series. I'm thrilled to share with you three fascinating AI breakthroughs that we'll dive into today:
Anthropic’s RAG Solution: Contextual Retrieval
Chonkie: A Lightweight and Fast RAG Chunking Library
A Hybrid RAG System: KDD Cup’ 24 Top Rankings
Anthropic’s RAG Solution: Contextual Retrieval
Open-Source Code: Retrieval Augmented Generation with Contextual Embeddings.
Chunk Context Insufficiency Problems
In traditional RAG, documents are split into smaller chunks to enable efficient retrieval. While this approach works well for many applications, it can create problems since individual chunks lack sufficient context.
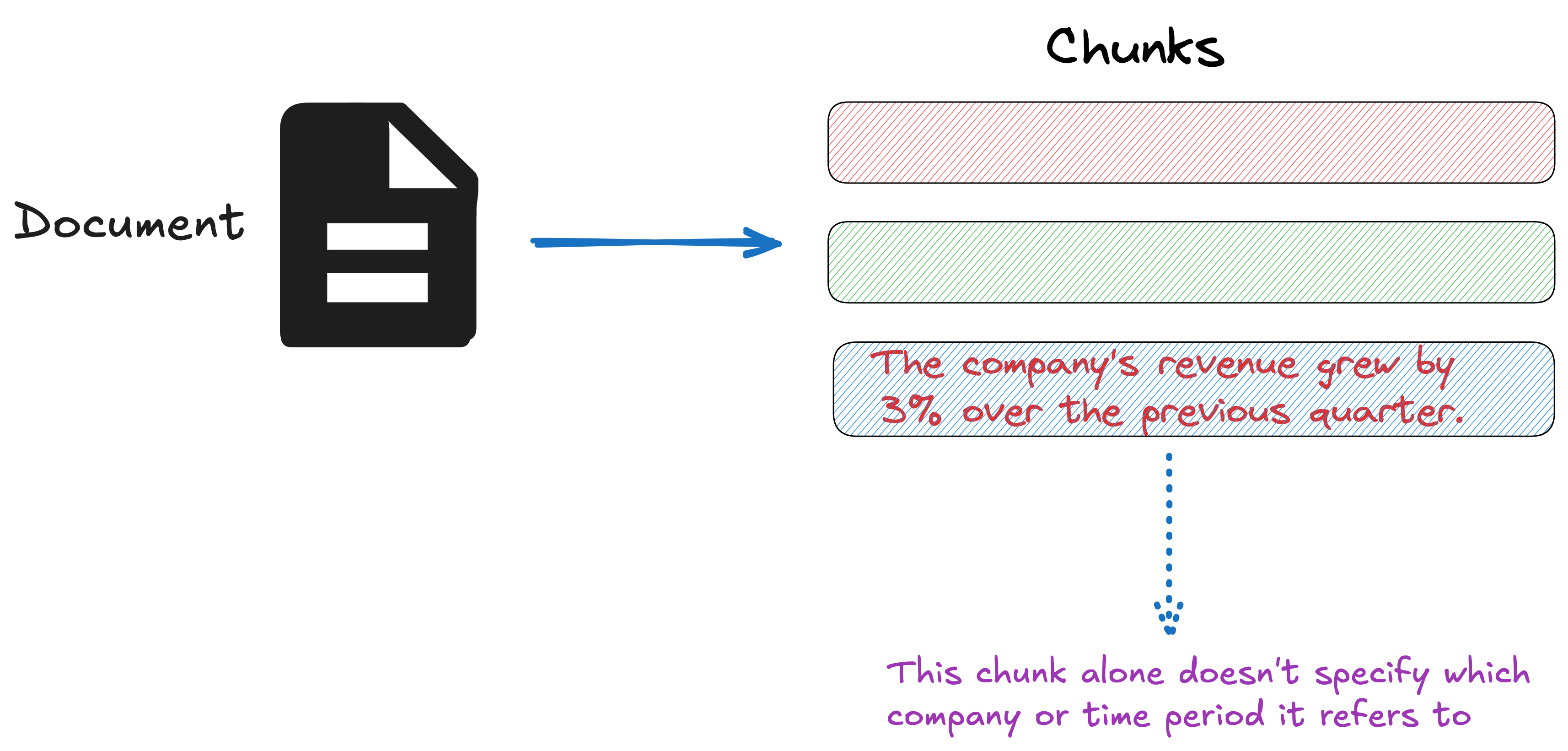
For example, imagine you have a collection of financial information (such as U.S. SEC filings) embedded in your knowledge base, and you receive this question: "What was the revenue growth for ACME Corp in Q2 2023?"
A relevant chunk might contain the text: "The company's revenue grew by 3% over the previous quarter." However, this chunk alone doesn't specify which company or time period it refers to, making it difficult to retrieve and use the information effectively.
This problem is actually not uncommon, there have been other methods in the past that used context to improve retrieval:
Adding general document summaries to chunks, though Anthropic notes that experiments showed only minimal improvements.
Summary-based indexing, which according to Anthropic demonstrated poor performance in evaluations.
Contextual Retrieval
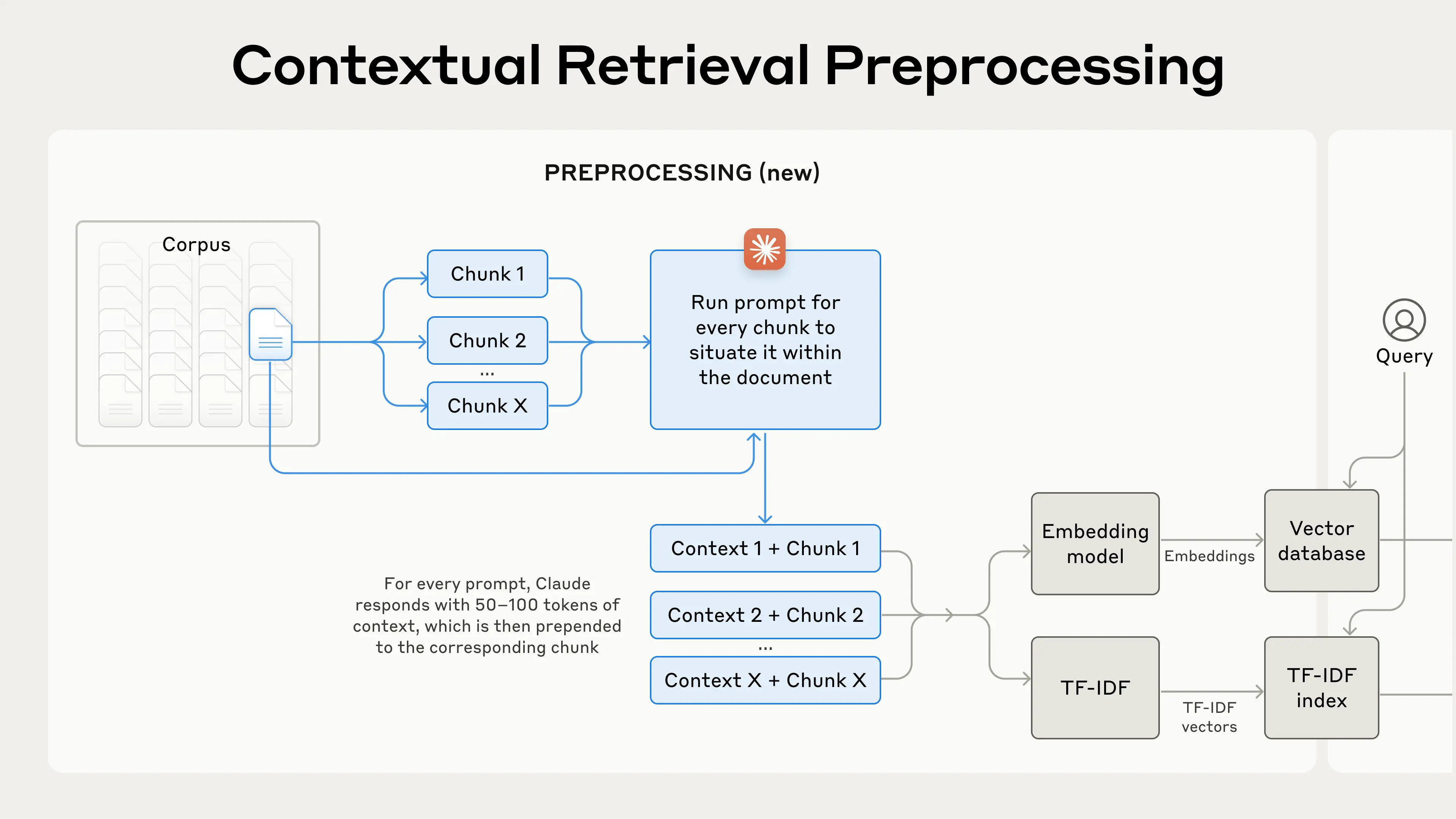
Anthropic proposes a Contextual Retrieval method, which prepends chunk-specific explanatory context to each chunk before embedding (“Contextual Embeddings”) and creating the BM25 index (“Contextual BM25”). By combining this approach with reranking, the method significantly improves retrieval precision and minimizes retrieval failures caused by context loss in large-scale knowledge bases.
BM25 (Best Matching 25) is a ranking function that uses lexical matching to find precise word or phrase matches. It's particularly effective for queries that include unique identifiers or technical terms. BM25 works by building upon the TF-IDF (Term Frequency-Inverse Document Frequency) concept.
Key Steps: Generating Context
Instruct Claude to generate concise, chunk-specific context by analyzing the entire document's context to explain each chunk. The prompt is as follows:
DOCUMENT_CONTEXT_PROMPT = """
<document>
{doc_content}
</document>
"""
CHUNK_CONTEXT_PROMPT = """
Here is the chunk we want to situate within the whole document
<chunk>
{chunk_content}
</chunk>
Please give a short succinct context to situate this chunk within the overall document for the purposes of improving search retrieval of the chunk.
Answer only with the succinct context and nothing else.
"""Here's an example of a contextualized chunk:
original_chunk = "The company's revenue grew by 3% over the previous quarter."
contextualized_chunk = "This chunk is from an SEC filing on ACME corp's performance in Q2 2023; the previous quarter's revenue was $314 million. The company's revenue grew by 3% over the previous quarter."Key Steps: Quick and Low-cost
Anthropic’s Prompt caching (Tutorial Code) is an optimization technique that stores frequently used prompts and related documents in a cache.
Once a document is loaded into the cache, subsequent queries can reference the cached content without reloading the entire document. This approach significantly reduces latency (by over 2x) and costs (by up to 90%), making the process more efficient and cost-effective.
Commentary
I have previously discussed approaches such as enhance global understanding or MemoRAG that can help mitigate the chunk context insufficiency problem.
While prompt cache reduces the time and cost needed to reload documents, the system still needs to reference relevant documents or content from the cache during each user query, and the number of queries itself has not decreased.
Additionally, while prompt caching reduces latency, it doesn’t address scenarios with dynamic knowledge bases (e.g., frequently updated technical documentation). Cached context might become outdated in such cases.
Chonkie: A Lightweight and Fast RAG Chunking Library
Open-Source Code: https://github.com/bhavnicksm/chonkie
I have written many articles about chunking before.
Recently I saw a new chunking library called chonkie, which provides several ways for chunking.
TokenChunker: Splits text into fixed-size token chunks.
WordChunker: Splits text into chunks based on words.
SentenceChunker: Splits text into chunks based on sentences.
SemanticChunker: Splits text into chunks based on semantic similarity.
SDPMChunker: Splits text using a Semantic Double-Pass Merge approach.
Chonkie also conducted some comparative experiments, showing faster speed.

Chonkie's code is not difficult, interested readers can check it out.
A Hybrid RAG System: KDD Cup’ 24 Top Rankings
Open-source code: https://gitlab.aicrowd.com/shizueyy/crag-new
Next, we will examine an engineering-focused RAG solution that ranks among the top in the Meta KDD Cup 2024. I have detailed this method in my previous article, and now I have some new insights.
Current large language models (LLMs) face three key limitations:
Lack of domain expertise: LLMs struggle with specialized fields like law and medicine.
Hallucinations: LLMs often generate incorrect information. For example, when asked, "Which number is larger, 3.11 or 3.9?" many LLMs incorrectly respond that 3.11 is larger than 3.9, which highlights the hallucination issue.
Static knowledge: LLMs lack up-to-date information for fast-changing domains like finance and sports.
"A Hybrid RAG System" presents a novel RAG system that addresses these challenges through a hybrid approach to enhance complex reasoning capabilities.
System Design
"A Hybrid RAG System" incorporates external knowledge bases to improve the reasoning and numerical computation capabilities of LLMs.

As shown in Figure 4, the system’s architecture consists of six main components:
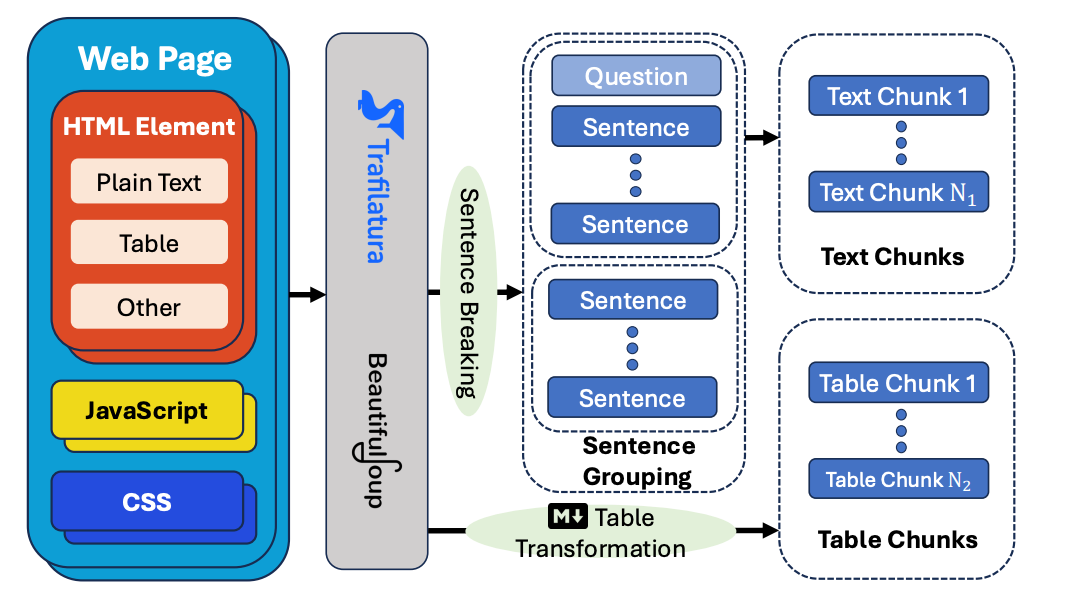
Web Page Processing: Extracts useful information from web pages by removing noisy elements like HTML tags and JavaScript. It uses Trafilatura for text extraction with BeautifulSoup as backup, divides content into semantic chunks, and converts tables to Markdown format for easier processing.

Figure 5: The design of the web page processing utilizes Trafilatura and BeautifulSoup to extract plain text and tables from web pages. Following this extraction, Blingfire is employed to segment the plain text into sentences, which are then grouped into chunks based on heuristic methods. Additionally, the tables are converted into Markdown format for further processing. Source: A Hybrid RAG System. Attribute Predictor: Classifies question types (simple vs. complex) or temporal relevance (static vs. dynamic). Using In-Context Learning and SVM classification, it helps the system adapt its reasoning approach based on question type.
Numerical Calculator: LLMs struggle with numerical calculations in domains like finance and sports. To address this, a Numerical Calculator extracts values from tables and text, using Python-based computation to perform accurate arithmetic operations and prevent calculation errors. For detailed information, please refer to this article.
LLM Knowledge Extractor: Complements external references by using the model's built-in knowledge. It extracts facts from the LLM's internal database and merges them with external sources to enhance answers when retrieved documents are outdated. It is effective for static domains.
Knowledge Graph Module: Queries structured databases for entity relationships. While function-calling methods were tested for dynamic query generation, a simpler rule-based approach was implemented due to resource limitations.
Reasoning Module: Combines all gathered information and uses Zero-Shot Chain-of-Thought (CoT) to generate answers. It breaks down complex reasoning tasks into smaller steps, asking intermediate questions when needed to ensure accuracy.
Each component plays a distinct role in ensuring accurate information retrieval, precise calculations, and logical reasoning.
Commentary
This Hybrid RAG system represents an improvement over traditional RAG models. The module that impressed me is the use of external tools for enhanced numerical calculations.
However, I believe that there are some areas for improvement:
The system’s complex reasoning paths may result in high computational costs and latency, which could be a bottleneck in resource-constrained environments.
The current rule-based query generation limits complex scenarios. A more flexible, automated function-calling approach could improve KG data retrieval.
The system struggles with real-time data, defaulting to "I don't know" for dynamic queries. Future versions could better incorporate dynamic data sources to improve real-time ability.
Conclusion
In this edition of AI Innovations and Trends, we've explored three groundbreaking AI technologies that uniquely advance our understanding and capabilities in artificial intelligence, bringing fresh perspectives and solutions to longstanding challenges.
Finally, if you’re interested in the series, feel free to check out my other articles.