


Meta CRAG KDD Cup 2024 Top Rankings: A Hybrid RAG Implementation Strategy

Today, we will examine an engineering-focused RAG solution that ranks among the top in the Meta CRAG KDD Cup 2024. It has also been open-sourced, allowing interested readers to study the code.
Current large language models (LLMs) face several limitations:
Lack of domain expertise: LLMs struggle with specialized fields like law and medicine due to insufficient exposure to such domains during pre-training.
Hallucinations: These models often generate incorrect or inconsistent information. For example, when asked, "Which number is larger, 3.11 or 3.9?" many LLMs incorrectly respond that 3.11 is larger than 3.9, which highlights the hallucination issue.
Static knowledge: LLMs tend to lack up-to-date information, making it difficult to apply them in fast-changing domains like finance and sports. For example, imagine asking an LLM for legal advice based on new regulations. The LLM may respond based on outdated data because it lacks real-time updates.
In this post, we explore "A Hybrid RAG System with Comprehensive Enhancement on Complex Reasoning". This study presents a novel Retrieval-Augmented Generation (RAG) system designed to address the key challenges mentioned above, specifically enhancing complex reasoning capabilities through a hybrid approach.
System Design
A Hybrid Retrieval-Augmented Generation (RAG) system that incorporates external knowledge bases to improve the reasoning and numerical computation capabilities of LLMs.

As shown in Figure 1, the system’s architecture consists of six main components:
Web Page Processing
Attribute Predictor
Numerical Calculator
LLM Knowledge Extractor
Knowledge Graph Module
Reasoning Module
Each component plays a distinct role in ensuring accurate information retrieval, precise calculations, and logical reasoning.
1. Web Page Processing
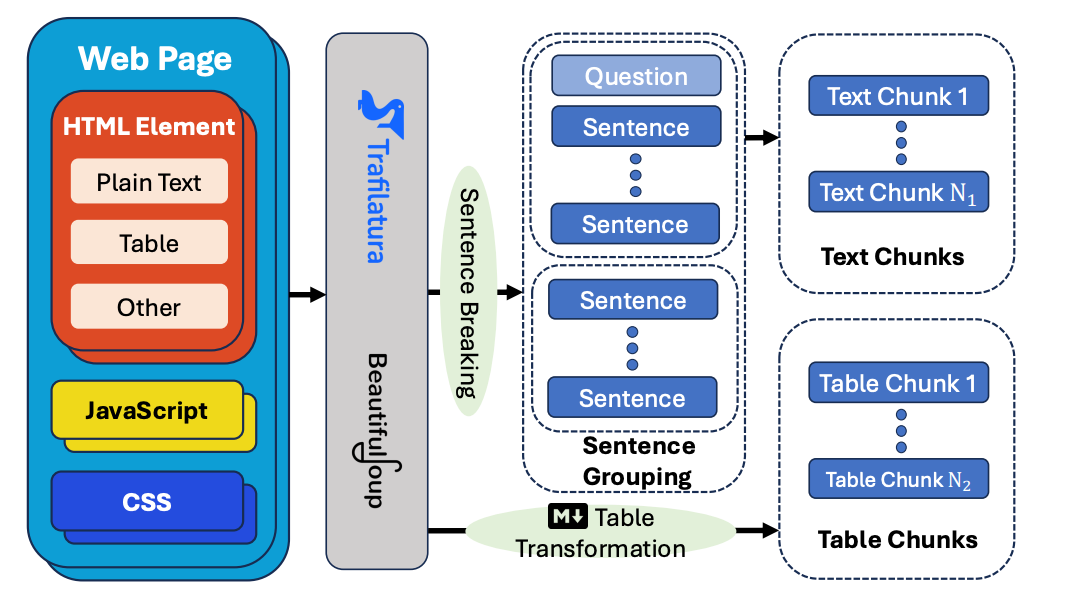
The first module focuses on extracting useful information from web pages, addressing the challenges of processing noisy web data that often includes irrelevant HTML tags, JavaScript, and other distractions.
To mitigate this, Trafilatura is utilized to clean the web pages by extracting relevant text, while BeautifulSoup acts as a backup for cases where Trafilatura cannot fully handle the webpage. The processed text is then divided into chunks, ensuring better semantic coherence for subsequent retrieval tasks. Similarly, tables are converted into a structured Markdown format for easier processing by the system.
2. Attribute Predictor
The Attribute Predictor is crucial for classifying the types of questions posed to the system. It differentiates between simple and complex question types, including multi-hop and aggregation questions, and assesses the temporal relevance of the question (static or dynamic).
The predictor utilizes In-Context Learning (ICL) and Support Vector Machines (SVM) to achieve this classification. By understanding the question type, the system adjusts its strategy, enhancing reasoning in difficult cases.
3. Numerical Calculator
Numerical reasoning is a well-known challenge for LLMs. In domains like finance and sports, the ability to perform precise numerical operations is critical.
To overcome the inherent weaknesses of LLMs in this area, a Numerical Calculator is introduced that extracts and computes values directly from tables and text chunks. This external tool uses Python-based computation to handle arithmetic operations, preventing the system from generating incorrect values.
4. LLM Knowledge Extractor
While the system primarily relies on external references for information, the LLM Knowledge Extractor adds an additional layer by utilizing the knowledge already embedded in the model.
This module extracts factual information from the LLM's internal knowledge base and combines it with external data sources. The goal is to improve answer quality in cases where retrieved documents may be outdated or irrelevant. This module is especially effective for static, slow-changing domains.
5. Knowledge Graph Module
To further enhance the system's reasoning capabilities, the Knowledge Graph (KG) Module is incorporated. This module queries a structured knowledge base to retrieve precise information related to entities and their relationships.
Initially, a rule-based approach was adopted for generating queries to the KG. However, function-calling methods were also experimented with, dynamically creating queries based on the LLM’s understanding of the question. Due to resource constraints, the rule-based method was primarily used in the current implementation.
6. Reasoning Module
The Reasoning Module consolidates all retrieved information (including text chunks, tables, knowledge graph data, and internal LLM knowledge) and generates a final answer.
This module leverages the Zero-Shot Chain-of-Thought (CoT) technique to guide the LLM through complex reasoning tasks, such as multi-hop reasoning. The system is capable of asking intermediate questions and breaking down the reasoning process into smaller steps to generate accurate answers.
Evaluation
Extensive experiments were conducted on the CRAG Benchmark, which evaluates retrieval-augmented models in real-world applications. The results indicate that the system significantly reduced hallucination rates and improved answer accuracy.
Figure 3 illustrates the improvement over the baseline model in the public test dataset, demonstrating a reduction in hallucinations and increased accuracy.

As shown in Figure 4, the ablation study demonstrates the contribution of each module to the system’s overall performance. Notably, the Reasoning Module and Numerical Calculator significantly improved results.

Conclusion and Insights
This post delves into a Hybrid RAG system, which represents a significant improvement over traditional RAG models. In summary, the key innovations are:
A hybrid RAG system that integrates multiple layers of retrieval and reasoning processes.
The use of external tools for enhanced numerical calculations.
A carefully crafted reasoning module that reduces hallucination and improves response accuracy.
However, I believe that there are some areas for improvement:
Optimization of the Knowledge Graph Module: While acknowledging the importance of KG queries, the current implementation relies on rule-based query generation, which can be limiting in complex scenarios. Introducing a more flexible, automated function-calling approach could significantly improve the system's performance in retrieving structured data from KGs in future versions.
Limitations in Handling Dynamic Information: The system currently struggles with rapidly changing information, such as real-time data. The solution of outputting "I don’t know" for dynamic queries helps reduce hallucinations, but it also limits the system's ability to provide useful real-time answers. Future improvements could explore ways to incorporate dynamic data sources more effectively, enhancing the system's responsiveness to real-time changes.