
The Roadmap to Reproduce OpenAI o1
An Intelligent Expedition Team

After OpenAI o1's release, its powerful reasoning abilities far surpassed those of earlier LLMs, reaching performance levels comparable to PhD-level expertise.
Currently, as far as I know, there are two paradigms for reproducing o1:
Knowledge Distillation-Based: This is a shortcut method that distills o1's data and fine-tunes LLMs (such as Llama 3.2, Qwen2, etc.) to mimic o1's reasoning style. However, these methods are limited by the capability ceiling of the teacher model.
Reinforcement Learning-Based: This is a more orthodox approach that progresses step by step, focusing on four key components: policy initialization, reward design, search, and learning, to achieve the goal of reproducing o1, as shown in Figure 1.

Although there is already some information available about reproducing o1, this article is primarily based on a serious survey, introducing the reproduction roadmap of o1 based on reinforcement learning. The roadmap is shown in Figure 2.

Vivid Description
Imagine you're preparing an expedition team to find a legendary treasure. This journey follows four key steps:
Policy Initialization – Equipping and Training the Team
Before setting out, you must equip your explorers and train them. You start with experienced guides (pre-trained LLMs) and teach them how to read maps and use a compass (language understanding and reasoning). Then, you refine their skills by showing them how to interpret complex clues and follow instructions (instruction fine-tuning), ensuring they can navigate the challenges ahead.Reward – Setting Up Motivation and Feedback
To keep the team on track, you introduce a reward system:Outcome Reward: Only rewarded if they find the treasure (correct final answer).
Process Reward: Earn rewards for each clue they uncover or correct step they take (gradual improvement).
This ensures they not only aim for the goal but also receive guidance along the way.
Search – Exploring the Unknown
The team can't rely on guesswork alone—they must explore strategically. Some plan multiple routes in advance (Tree Search), while others adjust step by step (Sequential Revisions). Their decisions improve with self-evaluation (internal feedback) and environmental clues (external feedback), helping them navigate more effectively.Learning – Growing from Experience
After each expedition, the team reviews their journey, learning what worked and what didn’t. By refining their strategies, they become better explorers. Similarly, the model uses search-generated data to refine its policies, improving performance over time.
In short, this roadmap is like training an intelligent expedition team—each step works together to help them find the best solutions, just as it enables models like o1 to develop powerful reasoning abilities.
Policy Initialization
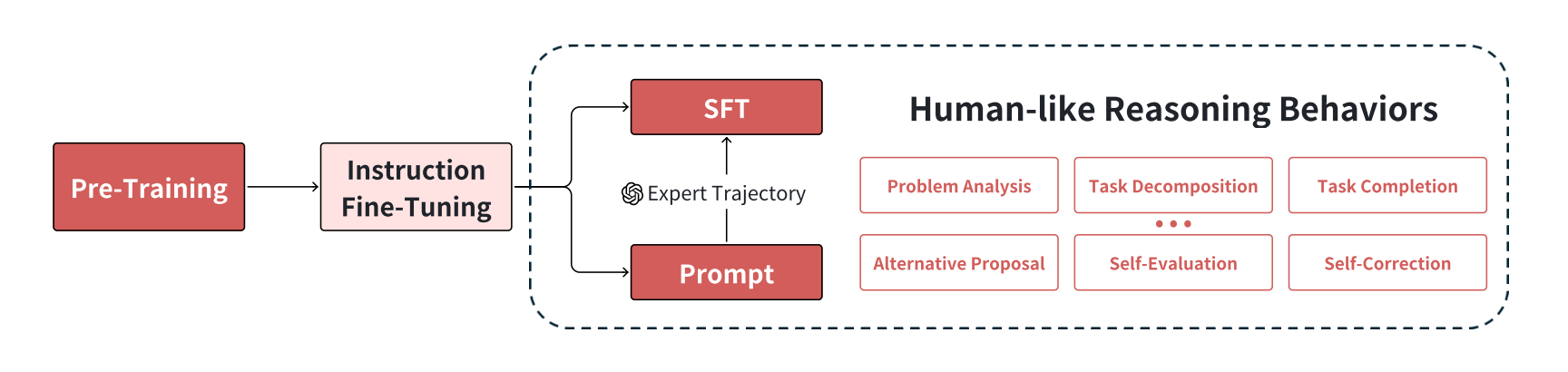
As shown in Figure 3, policy initialization involves three key stages:
Pre-training: The model learns foundational language understanding through self-supervised learning on large-scale text corpora.
Instruction fine-tuning: This step shifts the model from simple token prediction to generating responses that align with human expectations.
Developing human-like reasoning behaviors: While instruction-tuned models demonstrate broad task capabilities and an understanding of user intent, models like o1 require a more sophisticated reasoning skill set to reach their full potential. As shown in Figure 4, six human-like reasoning behaviors were identified to help o1 explore the solution space more effectively.

Figure 4: Exemplars of Human-like Reasoning Behaviors. [Source].

Policy initialization for o1-like models comes with two main challenges:
Balancing efficiency and exploration: Striking the right balance between efficient sampling and exploring diverse possibilities is tricky. While human demonstrations offer valuable guidance, they can sometimes limit the discovery of better strategies, as seen in the difference between AlphaGo and AlphaGo Zero.
Generalizing across domains: Instead of excelling only in specific areas like mathematics and coding, models need versatile reasoning skills that apply to a wide range of tasks, including safety checks. Building such broadly applicable capabilities is both essential and complex.
Reward Design
Next, we enter the reward design phase, which aims to provide guidance signals for search and learning.
The reward for LLMs fall into two main categories:
Outcome rewards score outputs based on predefined goals, like checking if a math solution is correct. They are simple to use but ignore errors in intermediate steps, which can reinforce flawed reasoning and hinder step-by-step learning. Despite these limitations, their simplicity makes them widely used.
Process rewards, on the other hand, provide feedback for both final and intermediate steps, offering more detailed guidance. However, they are harder to design and implement.
The resulting models are typically referred to as the Outcome Reward Model(ORM) and the Process Reward Model(PRM)

In essence, Outcome rewards can be seen as a simplified version of process rewards, where intermediate feedback is absent.
Reward design methods for models can use direct signals from real or simulated environments, AI judgment, or data-driven approaches. Real environments provide straightforward rewards, while simulated ones reduce costs but risk distribution shifts. Preference-based methods like RLHF align behavior with human values, while expert data methods like Inverse Reinforcement Learning (IRL) recover reward functions from expert trajectories but are more complex. Reward shaping refines weak signals to improve learning but requires careful design to avoid negative effects.
o1’s Reward Design
o1’s reasoning skills suggest its reward model incorporates multiple reward design methods.
For math and programming tasks, it likely uses process rewards to track intermediate steps, with reward shaping converting outcome rewards into process rewards.
When no reward signal is available from the environment, o1 may rely on preference data and expert data.
Its robust reward model, fine-tuned across diverse domains, adapts using ground truth and solution pairs.
In addition, it is more likely to predict rewards by generating with LLM rather than through value heads.
Reward design for reproducing o1 faces three main challenges.
First, distribution shifts occur as models explore beyond the training data, and while scaling data and iterative training help, they don’t fully solve the problem.
Second, designing fine-grained rewards for language tasks is difficult due to the vast action space and the need to balance token-level, step-level, or solution-level feedback.
Third, selecting the right data for complex tasks is tricky, as preference-based feedback can sometimes degrade the performance of the policy model, and evaluating reward effectiveness becomes harder as task complexity grows.
Search
Search refers to the process of finding the correct solution through multiple attempts or strategic exploration based on certain guidance, such as rewards or heuristic rules.
For models like o1, search is crucial for solving complex reasoning tasks during both training and inference.
Internal guidance relies on the model’s own states or evaluation capabilities, such as using token probabilities in greedy or beam search. External guidance, on the other hand, uses environment- or task-related signals to guide the search process.

Search strategies can be divided into two categories:
Tree search explores multiple solutions simultaneously, offering a global view and broader coverage.
Sequential revisions refine each attempt based on previous ones, acting as a more efficient local search.
o1’s Search
During training, o1 likely uses tree search techniques, such as BoN and other tree search algorithms, while relying mainly on external guidance. This approach allows the model to gradually improve its reasoning capabilities, as tree search can generate many candidate solutions in parallel, efficiently creating abundant high-quality training data.
At test time, o1 may rely on sequential revisions with internal guidance, using reflection to refine and correct its search.
Of course, there are some challenges of search for reproducing o1:
Overcoming inverse scaling: Reducing test-time search can limit inverse scaling but also reduces search scope. A better approach is improving the reward model’s generalization by increasing its size and training data.
Avoiding overthinking simple tasks: Simple problems like "1+1=?" don’t need complex reasoning. Adding a length penalty to the chain of thought (CoT) through reward shaping can limit unnecessary steps, saving resources and reducing delays.
Balancing tree search and sequential revisions: Combining tree search and sequential revisions improves performance, but with a fixed budget, resource allocation is challenging. Empirical scaling laws can guide the balance.
Improving search efficiency: Search efficiency is limited by memory speeds and lack of parallelism in some tree search algorithms (like MCTS). Solutions include engineering optimizations like KV-cache sharing and algorithmic improvements such as KV-cache compression and speculative sampling.
Learning
Policy initialization uses human-expert data, but reinforcement learning is needed for its ability to surpass human performance. Unlike expert data, it learns through trial and error, as seen with AlphaGo’s discovery of groundbreaking moves like the famous “Move 37.”
The policy can be improved through policy gradient methods or behavior cloning (supervised learning). Unlike in policy initialization, behavior cloning here learns from the search process rather than human experts.

Policy Gradient methods come in various forms, including REINFORCE, Actor-Critic, PPO, and DPO. Figure 8 compares REINFORCE, PPO, DPO, and behavior cloning.

For memory cost, PPO is memory-intensive, requiring a reward function, value function, and reference policy. DPO is simpler and more efficient but needs preference data. Behavior cloning, needing no reference policy, is the most memory-efficient.
For data utilization, PPO and DPO use all state-action pairs from search (Dsearch), including negative rewards. Behavior cloning only uses the subset of state-action pairs (Dexpert) from search with high rewards, limiting its scope. So PPO and DPO make better use of data than behavior cloning, as they can learn from both positive and negative actions to improve the policy.
o1’s Learning
Overall, o1 likely starts with behavior cloning for an efficient warm-up phase, transitioning to PPO or DPO when improvements plateau. This combination leverages the efficiency of behavior cloning early on while utilizing PPO or DPO’s ability to learn from a broader range of data for further optimization. This approach is consistent with the post-training strategies used in LLama2 and LLama3.
There are also challenges of learning for reproducing o1:
Training efficiency is hindered by slow search processes like MCTS, which can be improved by optimizing algorithms or reusing data from previous iterations.
Learning a strong question generator is challenging, as questions must be relevant, solvable, and able to improve learning. LLM can mitigate this problem.
Off-policy learning struggles with distribution shift, which can be reduced by limiting search scale, sampling from the current policy, or using techniques like importance sampling. Another is to apply behavior cloning to convert off-policy learning into on-policy learning.
Open-source o1 Project
Although o1 has no published paper, several open-source implementations are available. These can be seen as components or specific cases of the framework discussed here.

Among these, I think the following three reproductions are particularly representative and worth studying in depth:
o1 Replication Journey – Part 1: Expert Iteration. The tree data generated through beam search is traversed, with specific nodes refined by GPT-4 and then used in supervised fine-tuning. This process, described as expert iteration, highlights the model's self-reflection abilities through GPT-4 refinement.
o1 Replication Journey – Part 2: Distillation and CoT Recovery. It takes a different approach, focusing on distilling o1-mini. While o1-mini only outputs CoT summaries, Part 2 tries to recover the hidden CoT by prompt o1-mini to augment the summary.
Marco-o1 is like a mountain expedition team, aiming to find the optimal path to reach the summit (solve complex problems). Through a route planner (Chain of Thought (CoT)), the expedition team breaks down big goals into smaller, manageable steps to achieve them gradually. With the help of drones (Monte Carlo Tree Search (MCTS)), they simulate and explore multiple routes, using confidence scores to select the best path. Additionally, the team relies on a compass (reflection mechanism) to check and correct their direction.
Commentary
Since o1's release, numerous reproduction methods have emerged. Offering a systematic approach to building LLMs with advanced reasoning skills and highlighting key advancements is valuable.
Here are my thoughts:
o1-like Models can be seen as a combination of LLMs and AlphaGo-style systems. Could this approach extend to other fields, such as combining reinforcement learning and physical modeling to simulate complex systems?
Search plays a dual role: generating high-quality training data during training and improving performance during inference by efficiently exploring solution spaces. Common strategies like tree search and sequential revision are effective, but efficiency remains a limitation. I believe there will be more diverse strategies in the future to assist search in exploring reasoning spaces.
Domain generalization is a key challenge for LLM reasoning development. Designing reward signals and reasoning mechanisms that avoid overfitting to specific tasks or domains is a critical issue that needs to be addressed.
The shortcoming is that while this core framework—policy initialization, reward design, search, and learning—is comprehensive and logically clear, it lacks sufficient experimental data to validate its feasibility and effectiveness, making it difficult to clearly evaluate the method's actual performance.