
Unveiling Monte Carlo Tree Search (MCTS): Rolling the Dice and Picking the Best
Intuition, Principles, Code, and Discussion

Imagine we're playing a game of Go. After our opponent places their stone (marked as 16 in Figure 1), we need to select our next move from among the empty positions on the board.

First, we eliminate moves that violate basic Go principles, such as the positions marked with X in Figure 2.
As reasonably skilled players, we can identify several strong options, marked by the three green points in Figure 2.
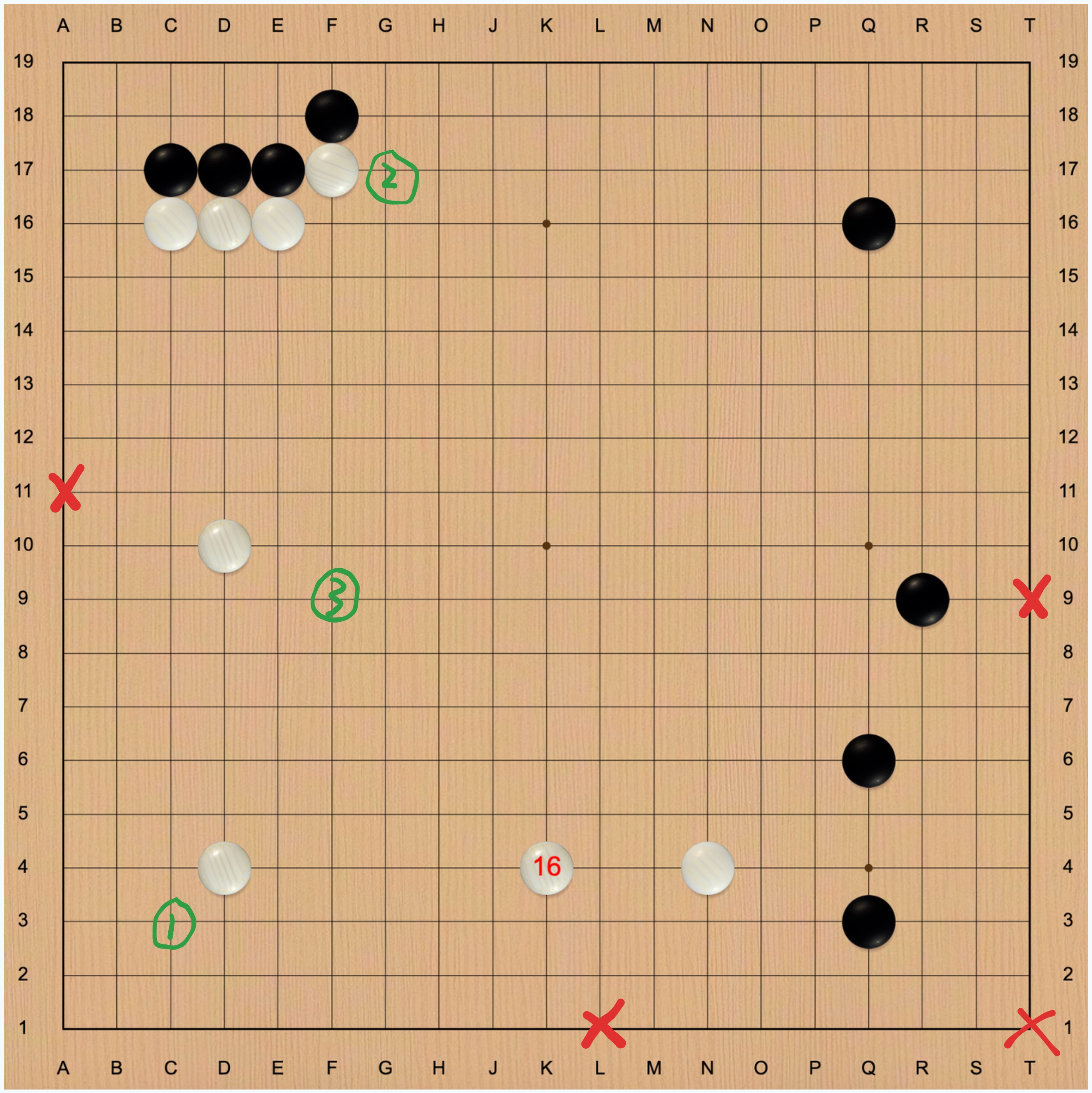
This creates three new branches, and then we consider how our opponent might respond to these four moves.
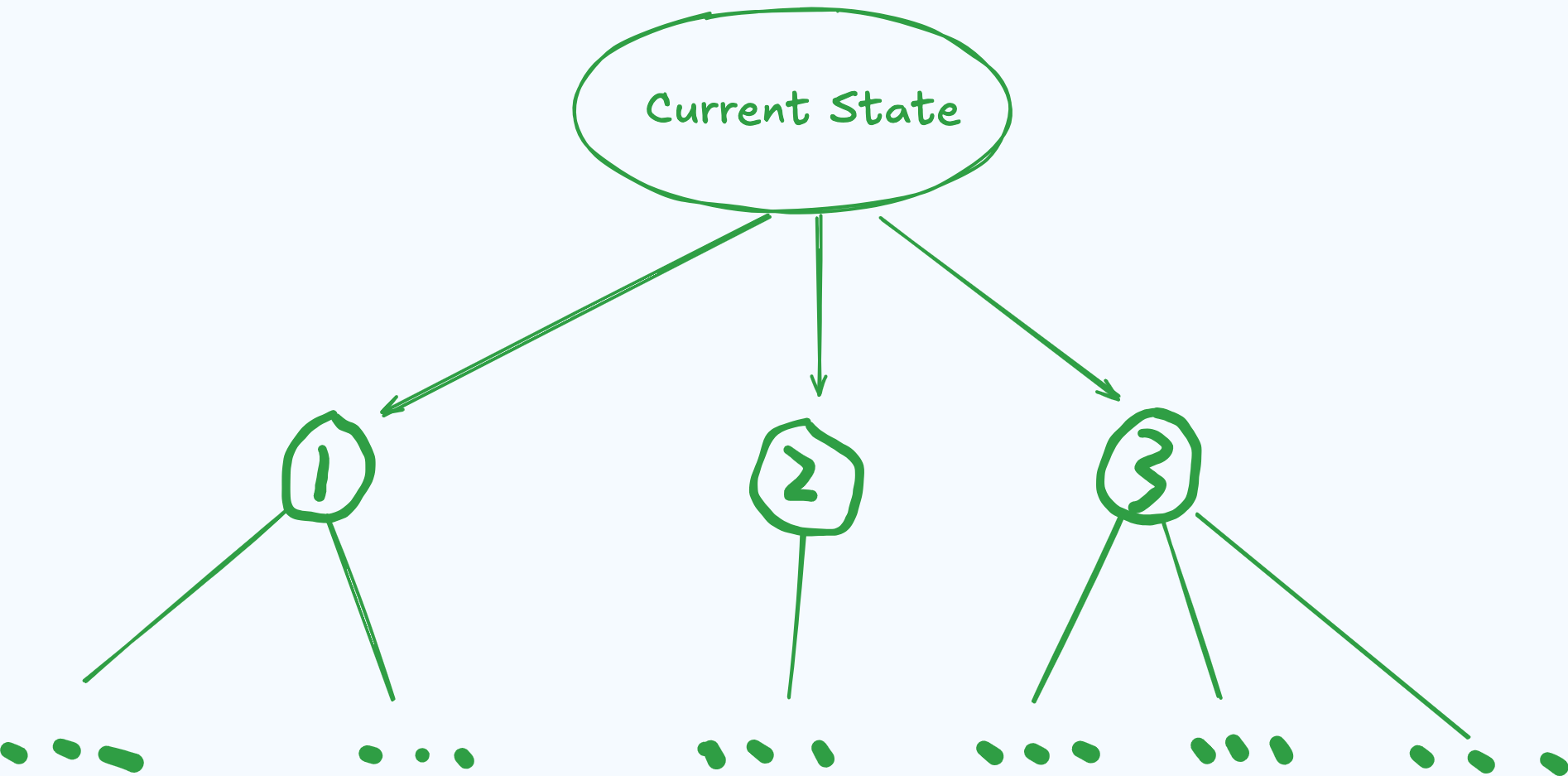
As this process continues, it creates a massive search space reaching 10^172 possible states - a number vastly larger than the estimated atoms in the universe (about 10^80). This makes it impossible to enumerate every possible move combination.
There are several pruning methods, such as alpha-beta pruning and heuristic search. In addition, as demonstrated by AlphaGo, we can use neural networks to evaluate positions, combined with the Monte Carlo Tree Search (MCTS) algorithm.
Background
Monte Carlo Tree Search (MCTS) first gained widespread attention in 2016 when AlphaGo defeated top human Go player Lee Sedol 4-1.
AlphaGo and its successor AlphaGo Zero combined several existing technologies: including Monte Carlo Tree Search (MCTS), Reinforcement Learning (RL), Convolutional Neural Networks (CNN), residual networks, self-play, and more.
Recently, OpenAI's o1 and o3 model implementations have sparked numerous research studies and speculation, with many reproduction attempts using Monte Carlo Tree Search (MCTS) as their search method.
This article focuses on explaining Monte Carlo Tree Search (MCTS) in a simple and clear way, helping you understand how it reduces vast search spaces.
Core Idea of MCTS
Thinking back to our Go game strategy, when our opponent moves, we perform:
Selection: Use our intuition to identify the possible moves and choose the most promising point.
Expansion: After choosing a specific branch, we begin strategizing by adding a new child node under the selected node of the branch, along with additional information. For example, '0/0' in Figure 4 indicates 0 simulations and 0 wins.
Simulation: Suppose our brain were powerful enough (like a computer), we could randomly simulate the game until its end, as illustrated by the branch at the bottom of Figure 4.
Backpropagation:
If we win, we reward each node along the path starting from the leaf node. The simplest way is to increase the success rate of each node in the path.
When we lose, we decrease each node's success rate along that path.
As shown in the top right of Figure 3, after 22 simulations with 11 wins, it is recorded as 11/22.
This straightforward process forms the core idea of the MCTS algorithm.
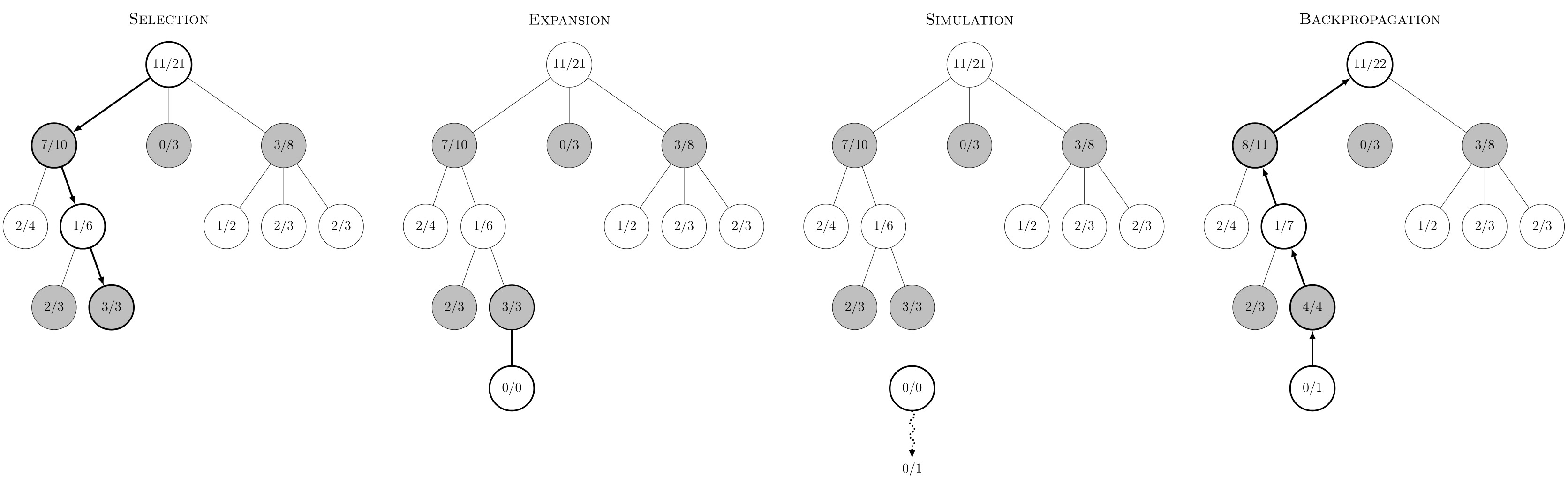
An important question arises: What principles should guide our node selection? The most intuitive approach is to choose the node with the highest win rate (wins/visits).
But this strategy has a problem. When a suboptimal node happens to win in the early random simulations, the algorithm will keep selecting that node thereafter.
Keep reading with a 7-day free trial
Subscribe to AI Exploration Journey to keep reading this post and get 7 days of free access to the full post archives.