


AI Innovations and Insights 21: Marco-o1, Plan×RAG, and PPTX to MarkDown
This article is the 21st in this compelling series. Today, we will explore three intriguing topics in AI, which are:
Marco-o1: Smart Mountaineering for LLM Reasoning
Plan×RAG: Project Manager for Step-by-Step Problem Solving with Traceable Results
PPTX2MD: A PPTX to Markdown Converter
Exquisite Video Imagery:
Marco-o1: Smart Mountaineering for LLM Reasoning
Open-source code: https://github.com/AIDC-AI/Marco-o1
Vivid Description
Marco-o1 is like a mountain expedition team, aiming to find the optimal path to reach the summit (solve complex problems).
Through a route planner (Chain of Thought (CoT)), the expedition team breaks down big goals into smaller, manageable steps to achieve them gradually. With the help of drones (Monte Carlo Tree Search (MCTS)), they simulate and explore multiple routes, using confidence scores to select the best path. Additionally, the team relies on a compass (reflection mechanism) to check and correct their direction.
Overview
Since its release, OpenAI's recent o1 model has become well-known for its exceptional reasoning capabilities, sparking numerous efforts to replicate it.
Marco-o1 is a reproduction approach that integrates cutting-edge technologies including Chain of Thought (CoT) fine-tuning, Monte Carlo Tree Search (MCTS), and reflection mechanisms to expand the model's reasoning capabilities.
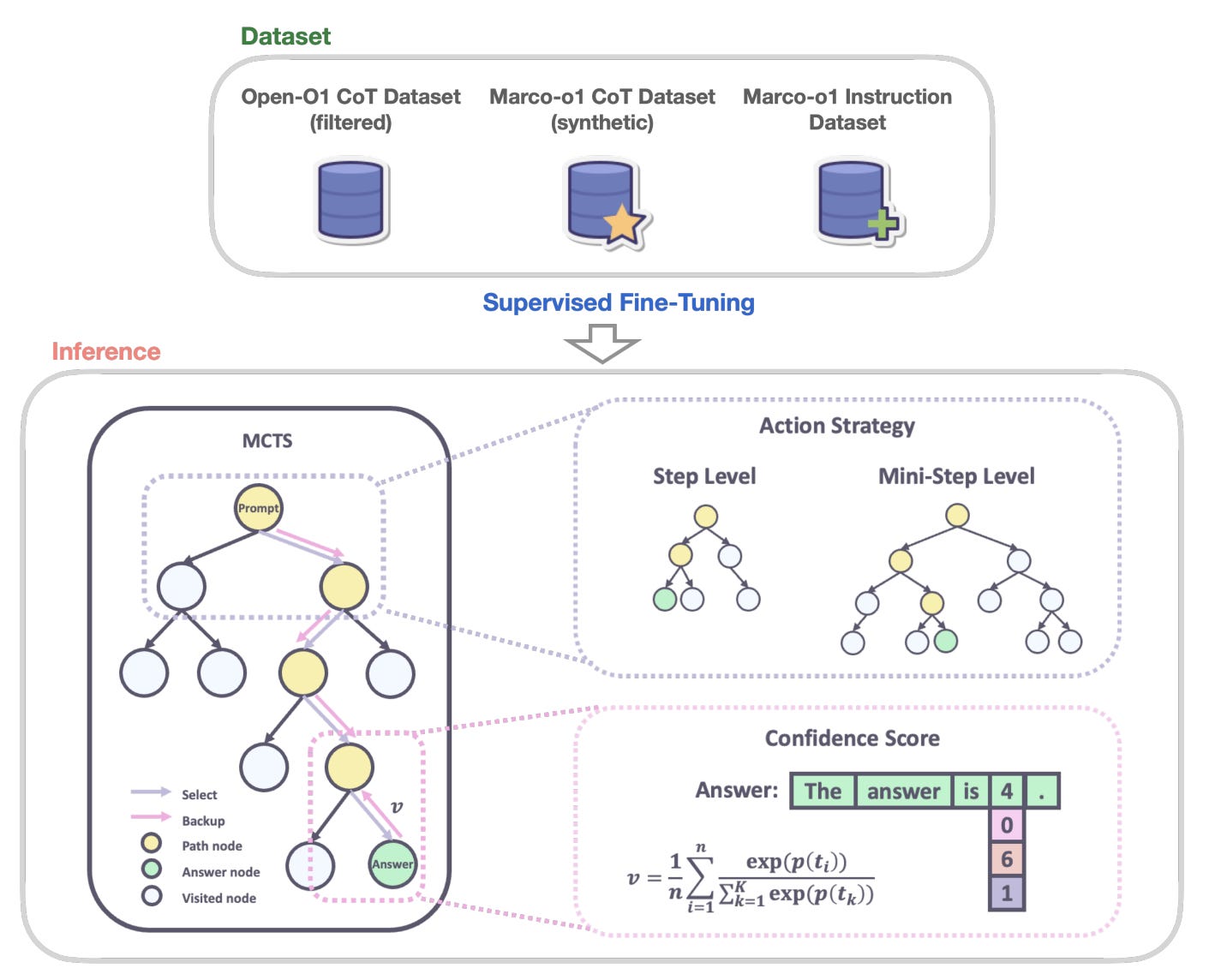
First, perform full-parameter fine-tuning on Qwen2-7B-Instruct with CoT data to enhance its capability in handling complex tasks. Notably, Marco-o1 CoT is a dataset generated using MCTS.
In simple terms, here is Marco-o1's reasoning process:
Problem Decomposition: Using Chain-of-Thought (CoT) to break down complex problems into multiple sub-problems.
Reasoning Path Exploration: Combining Monte Carlo Tree Search (MCTS) to generate multiple reasoning paths, with each path corresponding to different solutions.
Backpropagation: Calculating confidence scores for steps in each path to determine the overall rollout path reward.
Selection: Prioritizing the optimal path based on confidence scores to explore more likely correct solutions..
Answer Generation: Outputting the final answer based on the optimal reasoning path.
In addition, two optimizations were made:
Mini-steps (32 or 64 tokens) were introduced, considering more granular steps during the search process, which improved the model's ability to navigate complex reasoning tasks.
A reflection mechanism was introduced by adding the phrase "Wait! Maybe I made some mistakes! I need to rethink from scratch." at the end of each thought process. This improved accuracy on challenging problems by 50%.
Commentary
I initially planned to study Marco-o1's MCTS implementation, but as of January 21, 2025, the GitHub repository has not yet released the MCTS code.
In addition, I have two concerns:
The reflection mechanism design is relatively simple, primarily implemented by having the model regenerate reasoning paths. However, it hasn't been thoroughly proven in experiments whether the regenerated paths are sufficiently diverse or can effectively avoid previous errors.
The reward signal relies directly on confidence scores, and this single signal may prevent the reward function from accurately distinguishing the quality of complex paths. Multi-dimensional reward signals could be introduced, for example, combining path conciseness, task completion accuracy, and other comprehensive evaluations.
Plan×RAG: Project Manager for Step-by-Step Problem Solving with Traceable Results
Vivid Description
Plan×RAG works like a software project manager that uses a step-by-step plan (Directed Acyclic Graph (DAG)) to break big problems into smaller, easier tasks. It uses team members (expert modules) working together, and incorporates an audit system (single-document traceability) to verify the results of each task.
Overview
The standard RAG framework uses a "retrieve-then-reason" approach, retrieving and reasoning over documents to generate responses. However, this method struggles with irrelevant documents, insufficient information, and context window limitations. Additionally, RAG's inability to properly attribute generated content to source documents reduces its credibility and interpretability, leading to a critical limitation: the lack of attribution.
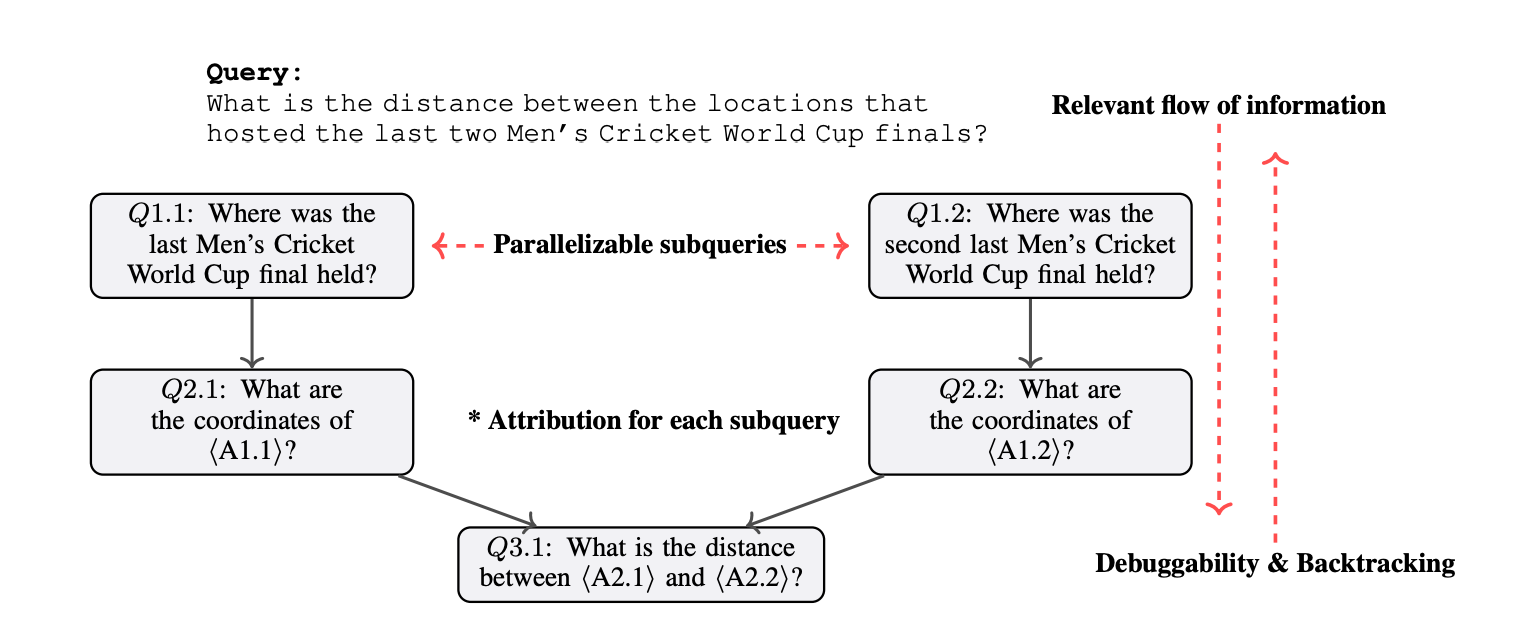
Instead of traditional "retrieve-then-reason", Plan×RAG introduces a "plan-then-retrieve" framework that decomposes complex queries into sub-queries structured within a Directed Acyclic Graph (DAG). The DAG concept is similar to the MindSearch we introduced earlier.

Unlike solutions (such as Self-RAG or RQ-RAG) requiring model fine-tuning, Plan×RAG uses frozen LMs as plug-and-play experts, making it cost-effective for smaller businesses.

Plan×RAG has five steps: Receive Input Query, Building the Reasoning Plan, Processing Sub-queries, Merge Sub-query Answers, and Return the Final Answer.
Commentary
The introduction of DAG and the collaborative mechanism of modular experts made me realize that future LLMs should be more like orchestratable systems rather than mere language generation tools.
However, In my view, DAG implementation faces efficiency challenges in high-load scenarios. Solutions could include:
Lightweight DAG optimization algorithms for simpler processing.
Dynamic DAG pruning to remove unnecessary paths.
PPTX2MD: A PPTX to Markdown Converter
Open-source code: https://github.com/ssine/pptx2md
Overview
I recently discovered a tool that converts PPT to Markdown. The demonstration is as follows:

Let's look at how it works.
The parse function is the core component that extracts various elements from PPTX slides, and converts them into a unified Python data structure.
def parse(config: ConversionConfig, prs: Presentation) -> ParsedPresentation:
result = ParsedPresentation(slides=[])
for idx, slide in enumerate(tqdm(prs.slides, desc='Converting slides')):
if config.page is not None and idx + 1 != config.page:
continue
shapes = []
try:
shapes = sorted(ungroup_shapes(slide.shapes), key=attrgetter('top', 'left'))
except:
logger.warning('Bad shapes encountered in this slide. Please check or remove them and try again.')
logger.warning('shapes:')
try:
for sp in slide.shapes:
logger.warning(sp.shape_type)
logger.warning(sp.top, sp.left, sp.width, sp.height)
except:
logger.warning('failed to print all bad shapes.')
if not config.try_multi_column:
result_slide = GeneralSlide(elements=process_shapes(config, shapes, idx + 1))
else:
multi_column_slide = get_multi_column_slide_if_present(
prs, slide, partial(process_shapes, config=config, slide_id=idx + 1))
if multi_column_slide:
result_slide = multi_column_slide
else:
result_slide = GeneralSlide(elements=process_shapes(config, shapes, idx + 1))
if not config.disable_notes and slide.has_notes_slide:
text = slide.notes_slide.notes_text_frame.text
if text:
result_slide.notes.append(text)
result.slides.append(result_slide)
return resultIt works by first iterating through each slide, decomposing and sorting its shapes, then applying specific processing functions based on shape type to handle text blocks, titles, images, and tables. It can handle multi-column layouts and extract notes if needed. The function packages all processed content into a ParsedPresentation object before returning it.
Commentary
Converting PPTX to Markdown is much simpler than converting to PDF—at least there's a clear path to follow.
Finally, if you’re interested in the series, feel free to check out my other articles.