
O1 Replication Journey Part 3: Procrastination Problem of LLM
Can Inference-Time Scaling Make It Smarter?

This is the third article in the o1 Replication Journey series. In the first two, we explored:
O1 Replication Journey Part 1: From Shortcut Hunters to True Explorers
O1 Replication Journey Part 2: Let a Great Teacher Guide Students
In this article, we dive into O1 Replication Journey Part 3: Inference-time Scaling for Medical Reasoning. Whether you're simply curious about the principles behind OpenAI o1 or a technical expert looking to replicate it, you'll find this guide helpful.
Vivid Description
Imagine asking a friend a tough question.
If they answer right away, their response might be quick but not necessarily accurate. However, if you tell them, "Take your time, think it through," they'll likely pause, analyze the problem from different angles, and come up with a more thoughtful and reliable answer.
Inference-time scaling works the same way. By giving the LLM more time to process and reason before responding, it can tackle complex problems with greater accuracy and depth.
How can we achieve Inference-time Scaling?
So, that brings us to the question: how do we actually achieve Inference-time Scaling?
O1 Replication Journey Part 3 makes it happen through the following key approaches.
Knowledge Distillation: Learning from Stronger Models
We covered this in o1 Replication Journey Part 2—using high-quality data from a more powerful LLM to guide a weaker one.
O1 Replication Journey Part 3 collects journey learning data from OpenAI o1 and GPT-4o, then synthesizes two types of long-form data.
LongStep: By analyzing responses from o1 and GPT-4o, o1’s problem-solving steps are extracted and used to train LLMs to replicate reasoning capabilities, producing more thorough and detailed solutions.
LongMonolog: Carefully designed prompts instruct o1-preview to expand its summarized thoughts into longer, more reflective reasoning—similar to an inner monologue. This generates highly detailed responses with self-correction and extended reasoning.

Supervised Fine-tuning
The LongStep and LongMonolog datasets are used to fine-tune foundational models like Qwen2.5-32B-Instruct, Qwen2.5-72B-Instruct, and LLaMA3.1-70B-Instruct for better instruction following.
Chain-of-Thought (CoT)
There are two approaches:
CoT prompting expands a model’s reasoning ability during inference. By guiding the model to solve problems step by step, it effectively extends the inference time.
Chain-of-Thought Supervised Fine-Tuning (CoT SFT) trains the model using CoT data generated by GPT-4o. By fine-tuning on these samples, the model learns GPT-4o’s reasoning patterns, enabling it to produce clearer and more logical answers.
Majority Voting
Majority voting is an intuitive, plug-and-play approach commonly used for scaling inference time by leveraging the collective reasoning process across different computational runs.
Can Inference-time Scaling Improve Performance?
Figure 2 compares model accuracy across different strategies, showing that inference-time scaling significantly improves performance on complex medical questions.
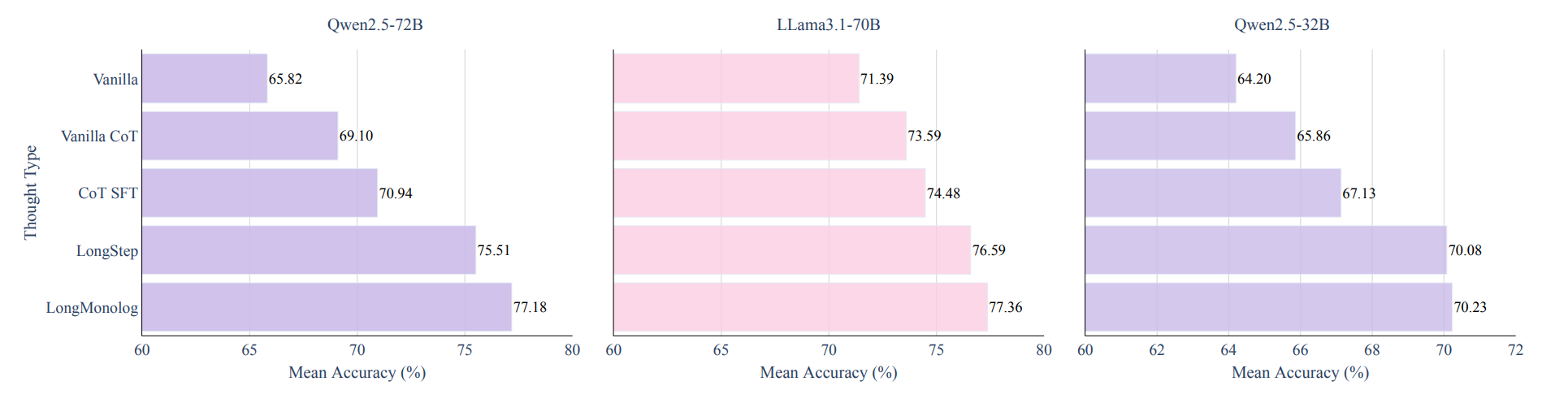
As shown in Figure 2, long-thought journey learning strategies (LongStep and LongMonolog) outperform traditional CoT methods, leading to significant accuracy gains in medical reasoning tasks. The improvement is especially pronounced on more complex datasets like JAMA.
In addition, larger LLMs (Qwen2.5-72B and LLaMA3.1-70B) benefit more from inference-time scaling, while smaller models, limited by computational capacity, show less noticeable gains.
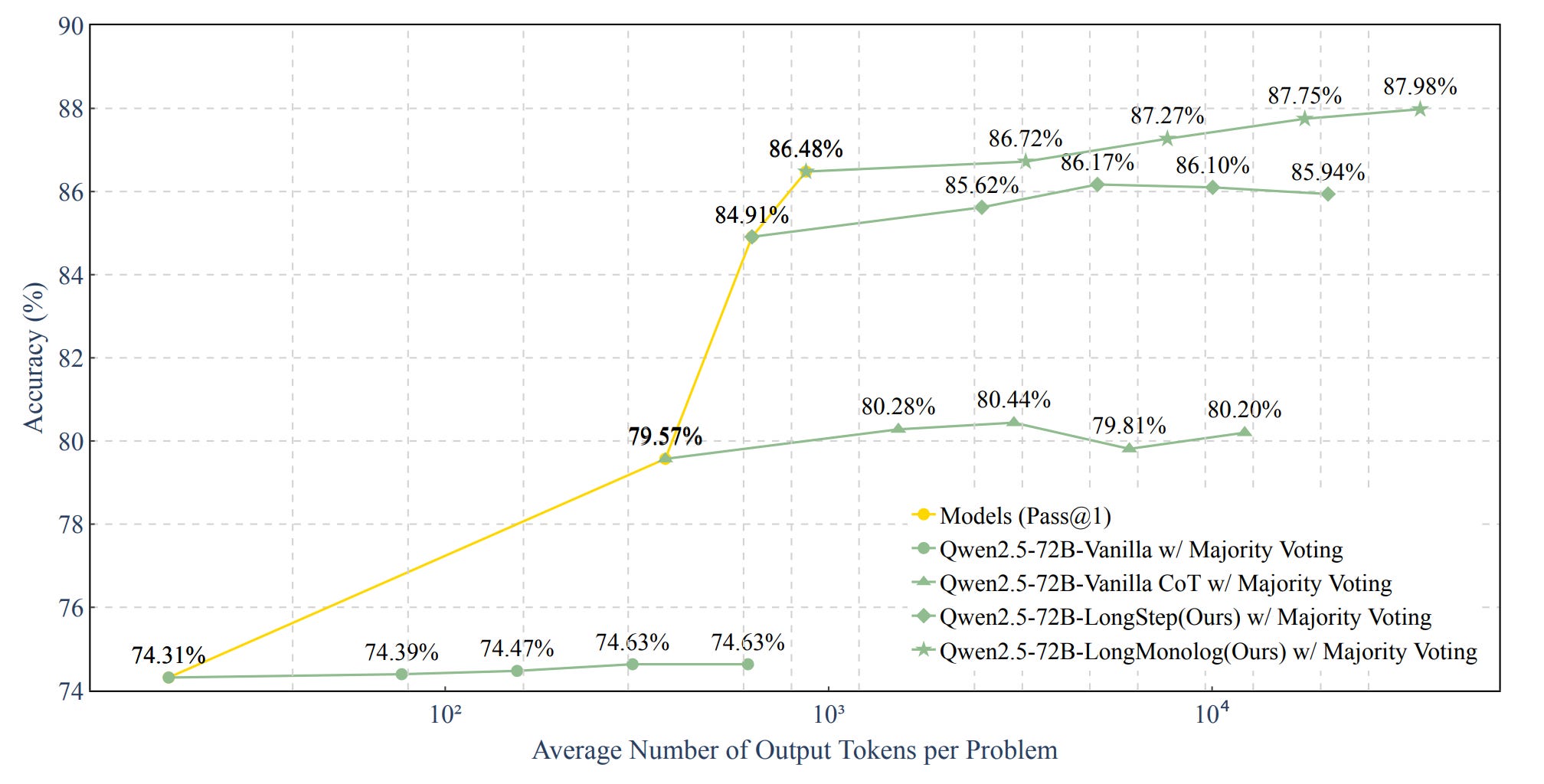
Experiments with the Qwen2.5-72B model on the MedQA dataset compared four approaches using majority voting across 4, 8, 16, and 32 rounds.
Figure 3 shows that increasing inference time, measured by the number of output tokens, improves accuracy on the MedQA dataset. However, majority voting alone has limited impact, while combining it with CoT or journey learning leads to greater improvements. This highlights the importance of incorporating long thinking into the reasoning process.
Thoughts and Insights
Inference-time Scaling is a hot topic right now, and I’ve learned a lot from it and sparked some new ideas.
Experiments confirm that inference-time scaling improves LLM performance on medical tasks. But does this improvement continue indefinitely? Is there a point of diminishing returns where, beyond a certain threshold, additional reasoning time no longer leads to meaningful gains—or even starts to degrade performance?
Would it be possible to implement Adaptive Inference-time Scaling, where the length of the reasoning chain adjusts dynamically? Simple tasks would use shorter reasoning chains, while more complex ones would allow for extended reasoning.
One approach could be Task Complexity Estimation, enabling the model to assess a problem’s difficulty and automatically allocate the appropriate reasoning time.
In addition, a closer look at failure cases could provide valuable insights into where models struggle the most. Which types of medical questions lead to errors, and why? For instance, how well do models handle rare diseases or problems involving complex pathophysiological mechanisms? Analyzing these patterns could help refine their reasoning capabilities.