
O1 Replication Journey Part 2: Let a Great Teacher Guide Students

In my view, any kind of learning boils down to two key elements: training data and training methods. For enhancing LLM reasoning or replicating OpenAI o1, obtaining long-thought chains as training data is crucial.
In the previous article (O1 Replication Journey Part 1: From Shortcut Hunters to True Explorers), we explored tree search as a method for generating training data. While tree search is effective, it comes with high computational costs and long processing times.

In this article, we introduce O1 Replication Journey – Part 2: Surpassing O1-preview through Simple Distillation Big Progress or Bitter Lesson?, where the core idea is to obtain training data through distillation.
Specifically, by fine-tuning a base LLM with tens of thousands of samples distilled from o1’s long-thought chains, it’s possible to outperform o1-preview on the AIME (American Invitational Mathematics Examination)—all with surprisingly low technical complexity.
As in my previous article (O1 Replication Journey Part 1: From Shortcut Hunters to True Explorers), we’ll break this article into two main parts: training data and training methods.
Training Data
The underlying long thoughts of o1 in solving complex equations is shown in Figure 2.

The data comes from knowledge distillation using o1 model. Here's how it was done:
Direct prompting: Complex math problems are fed into o1 through its API, prompting it to generate detailed reasoning steps.
Generating long-chain thought processes: As the o1 tackled these problems, it produced step-by-step thought chains, including reflection, error correction, and backtracking.
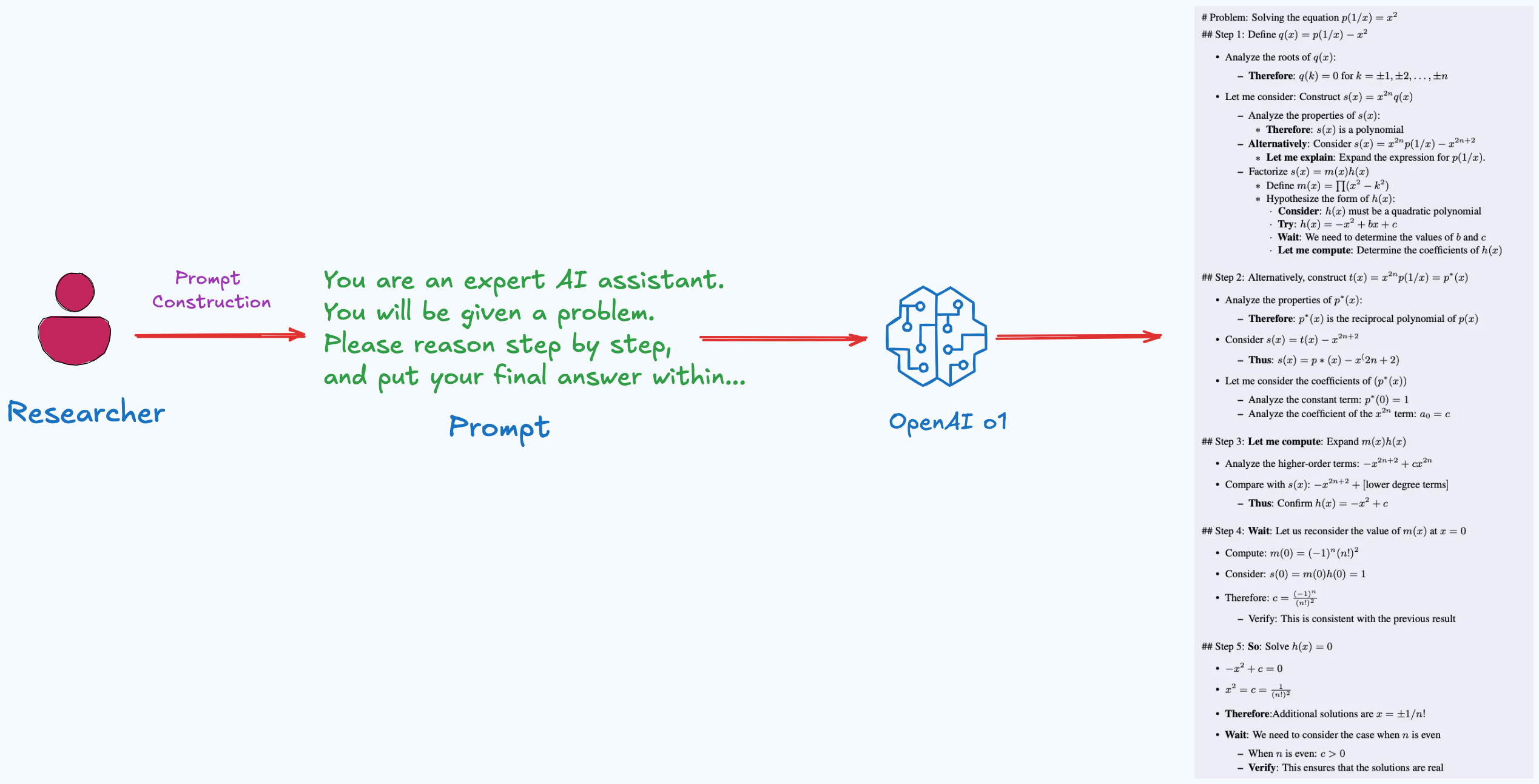
Since o1 hides its reasoning process, distilling it can be tricky, so it's a bit disappointing that it doesn't share the specifics of how the prompts were designed to extract o1’s thought process. But given OpenAI’s policies, that’s understandable.
Training Method
O1 Replication Journey – Part 2 follows a two-stage Supervised Fine-Tuning (SFT) process.
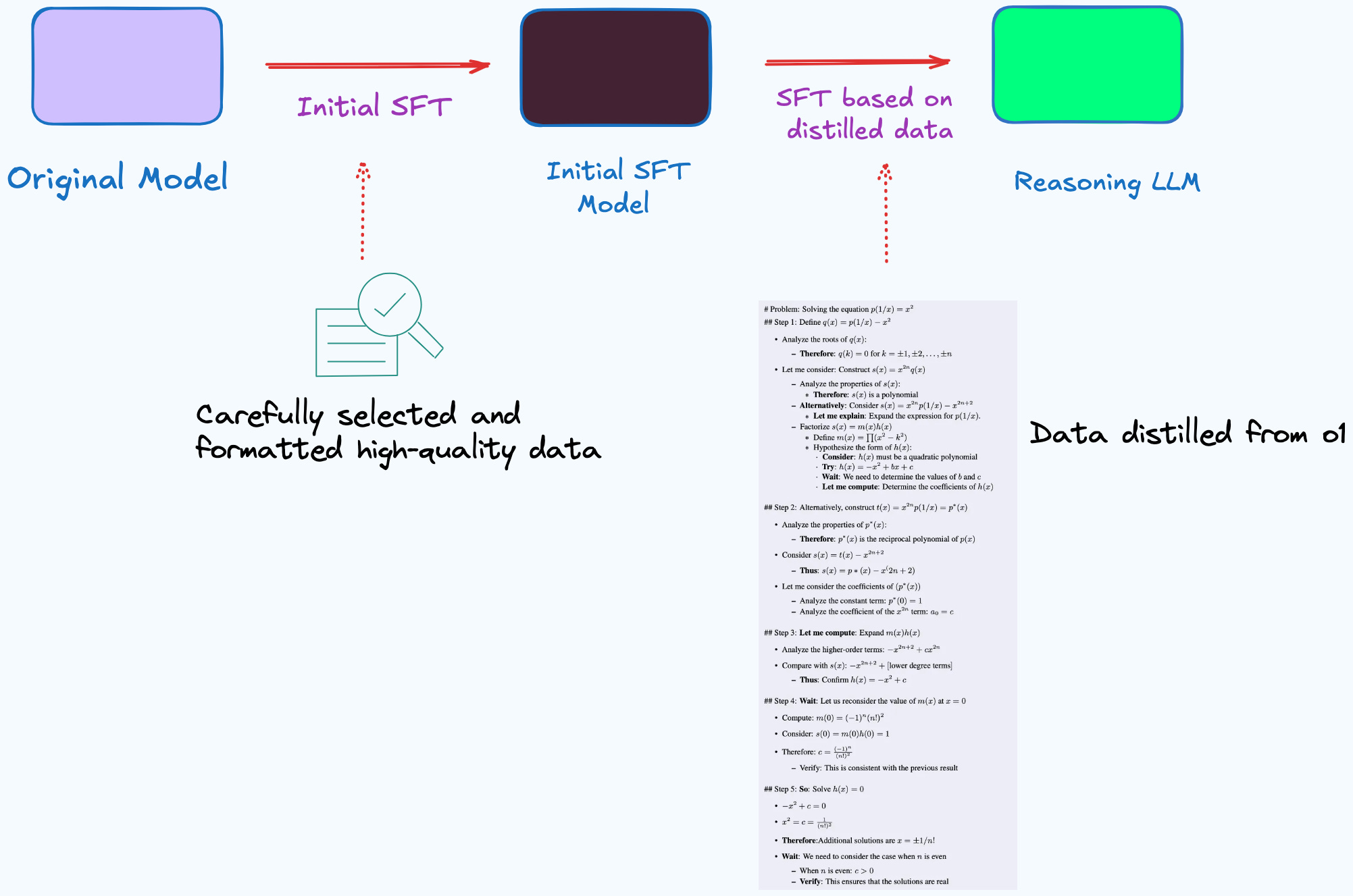
In the first phase, the goal is to familiarize the model with long-form reasoning. It is trained on a carefully selected and formatted high-quality dataset, designed to produce more detailed, step-by-step responses. This phase ensures that the model produces detailed reasoning and maintains a consistent output style, laying the groundwork for distillation.
The second phase focuses on distillation-based fine-tuning, using high-quality long-thought data distilled from o1. This step further enhances the model’s reasoning ability and ensures its outputs remain precise, coherent, and consistently structured.
Bitter Lesson of Distillation
In addition, O1 Replication Journey – Part 2 highlights the potential risks of distillation.
At first glance, distillation seems like an elegant solution: a model can directly learn o1’s reasoning patterns, gain a quick performance boost, and follow a relatively straightforward process.
But this convenience comes at a cost. The most immediate technical limitation is: Distillation is inherently constrained—no matter how much we refine the process, the model’s capabilities will never exceed those of its teacher (o1). This creates an implicit ceiling effect, which becomes a serious issue when expanding AI into new domains or tackling novel challenges.
More fundamentally, the widespread reliance on distillation may be causing us to miss critical opportunities for real innovation. In other words, o1’s real breakthroughs likely go beyond solving complex problems—they lie in inference-time scaling and search optimization. Skipping over these foundational advancements could widen the infrastructure gap in AI development.
My Thoughts on Distillation: Is It Really Worth Investing In?
There are still important questions worth exploring when it comes to distillation. Here are a few key insights:
Loss of information: o1 may rely on internal search, reinforcement learning, or other hidden computational mechanisms. Since distillation captures only its outputs rather than its full reasoning process, it might not fully preserve o1’s true capabilities.
Possible Distillation Methods: Since o1 hides its reasoning process, distilling it can be tricky. There are some unconventional ways to bypass these output restrictions, such as jailbreaking or prompt hacking—techniques that fall under the broader field of model security and adversarial attacks.
Commercial Challenges: The distilled data from O1 can’t be used commercially. According to OpenAI’s Terms of Service, API-generated samples require authorization before being used in commercial products. To make the data viable for real-world applications, it would need to be re-labeled and carefully filtered.
Overall, if you have ambitious goals—whether it's keeping your reasoning LLM at the cutting edge or building a commercial product—I wouldn’t recommend using distillation to obtain training data.
That said, distillation itself isn’t the problem—it’s a valuable tool in the AI toolbox. For scientific research or personal projects, this approach can be a quick way to understand how advanced reasoning LLMs think or to rapidly develop prototype systems.