
NodeRAG: Installing a "Structured Brain" for LLMs — AI Innovations and Insights 43

Welcome back, we’re now at Chapter 43 of this ongoing journey.
Overview
Open-source code: https://github.com/Terry-Xu-666/NodeRAG
Traditional RAG often struggles with fragmented content and redundant information. Graph-based RAG improves on this, but its simplistic graph structure falls short when it comes to capturing complex meanings.
That’s where NodeRAG comes in — by combining heterogeneous nodes with graph algorithms, it rebuilds knowledge representation to make RAG smarter, more precise, and better structured.
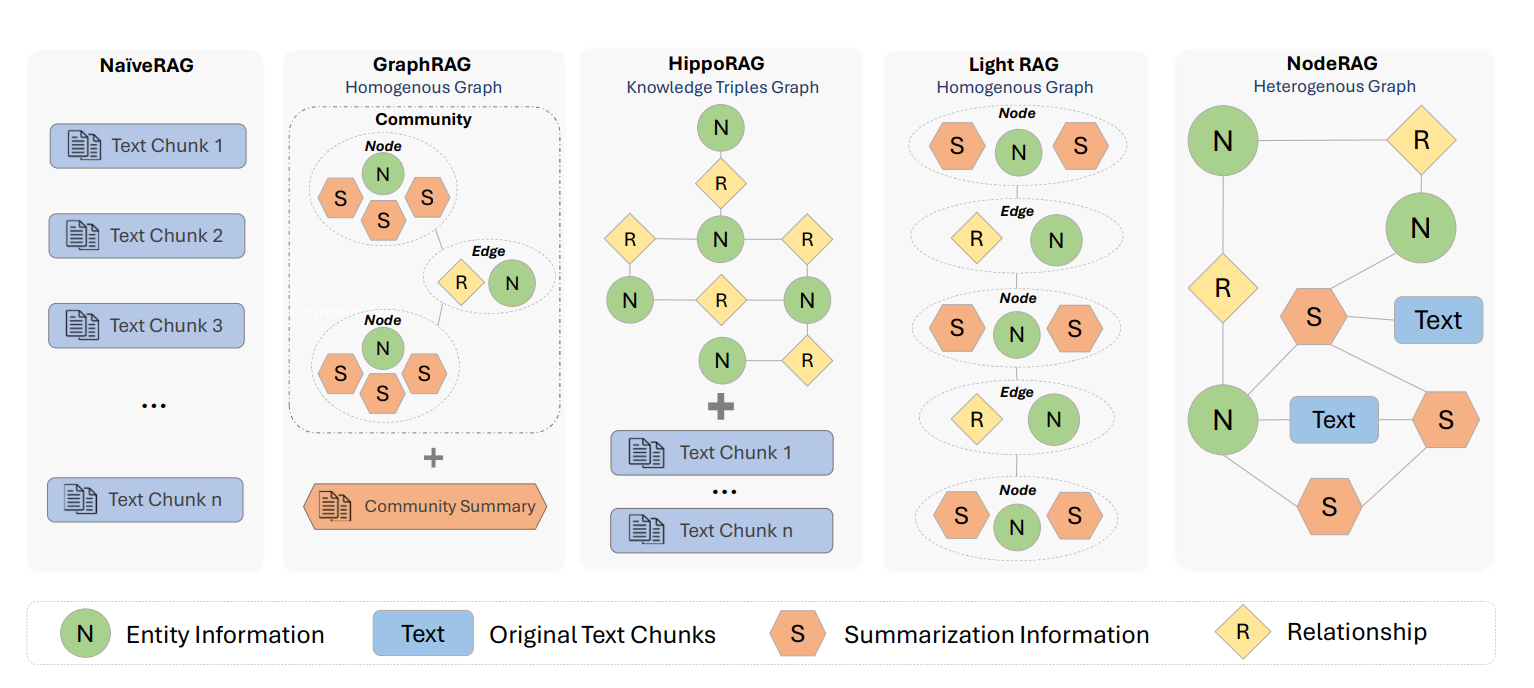
As shown in Figure 1:
NaïveRAG (Advanced RAG 01: Problems of Naive RAG) retrieves fragmented text chunks, often leading to redundant information.
HippoRAG (AI Innovations and Insights 31: olmOCR , HippoRAG 2, and RAG Web UI) brings in knowledge graphs but struggles with high-level summarization.
GraphRAG (AI Exploration Journey: Graph RAG) tries to solve this by retrieving community summaries, but the results can still feel too broad.
LightRAG (AI Innovations and Trends 03: LightRAG, Docling, DRIFT, and More) incorporates one-hop neighbors, which helps contextually, but also retrieves redundant nodes.
NodeRAG takes a different approach — by using multiple types of nodes, like high-level elements, semantic units, and relationships, it enables more precise, hierarchical retrieval while reducing irrelevant information.
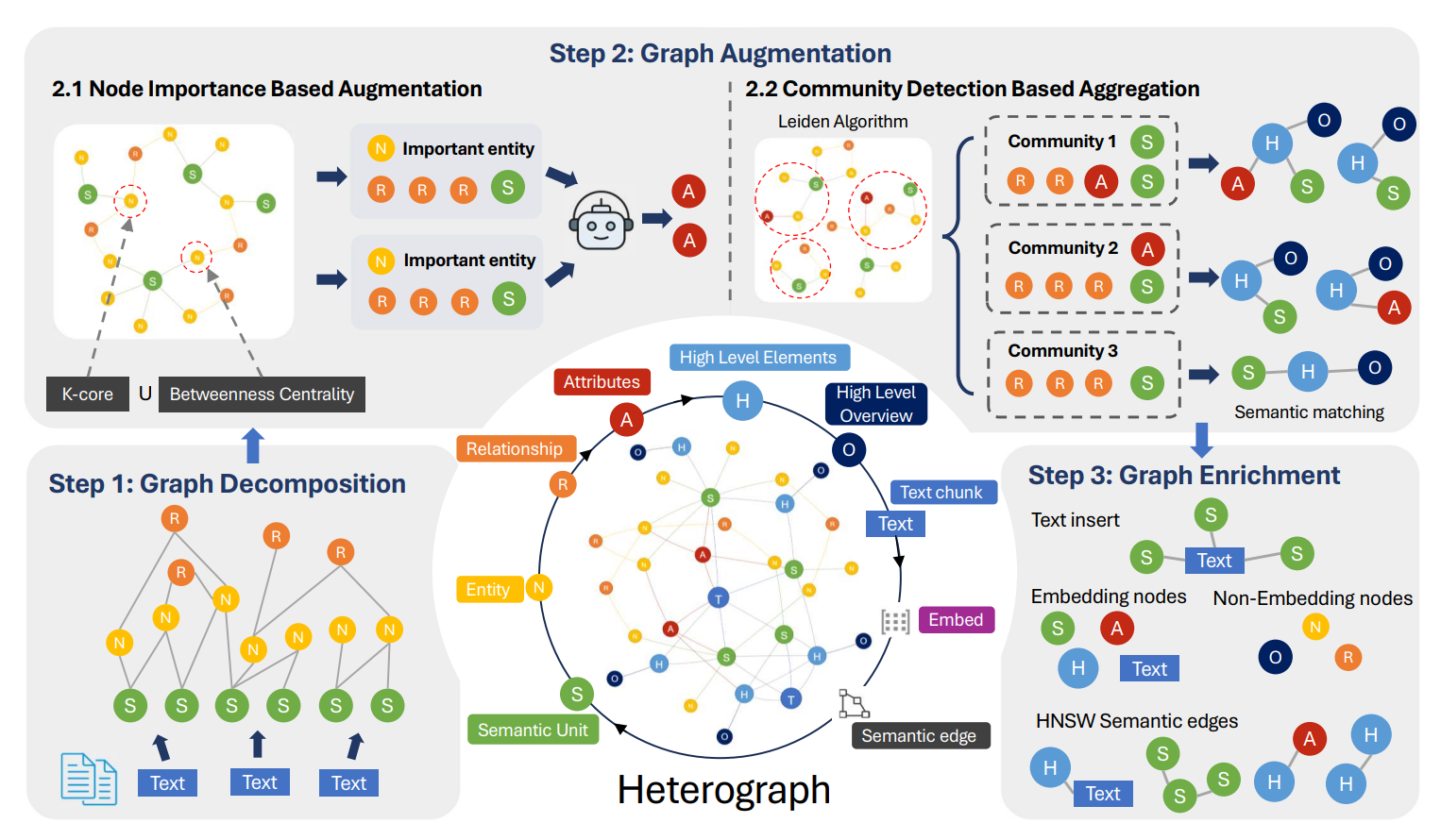
Figure 2 breaks down how NodeRAG builds its heterogeneous graph index in three clear steps:
Graph Decomposition: The process starts by using an LLM to split the text into three core node types: semantic units (S), entities (N), and relationships (R).
Graph Augmentation: Next, it identifies key nodes—like core entities—and creates attribute nodes (A) to highlight their importance. It also runs community detection to surface high-level insights, generating summary nodes (H) and title nodes (O).
Graph Enrichment: Finally, it brings in the original text (T) to preserve detail, and adds semantic similarity edges using HNSW, making the graph more powerful and precise for retrieval.
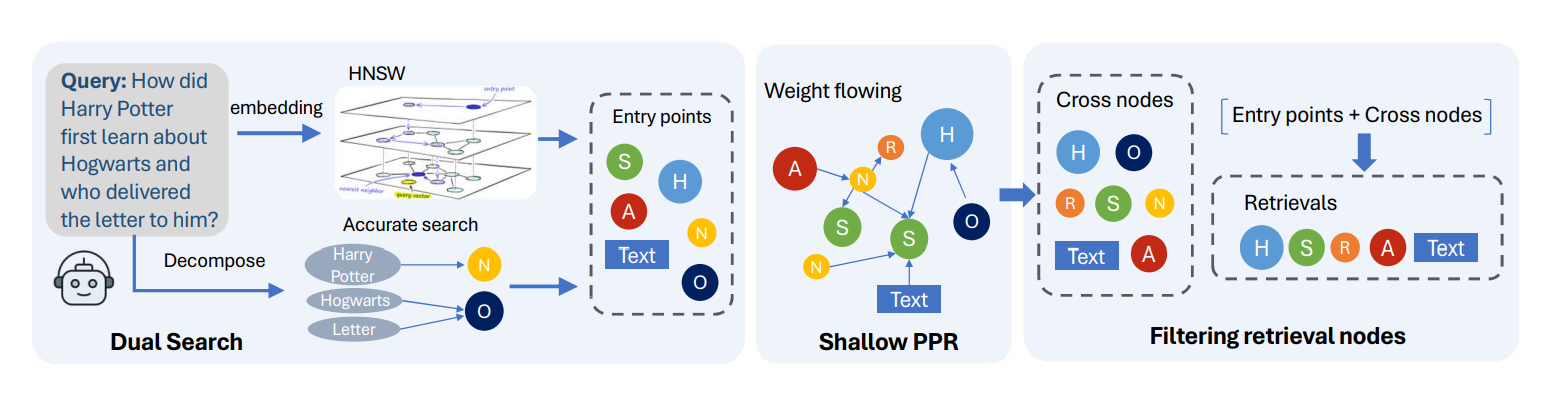
Figure 3 illustrates how NodeRAG handles queries through a streamlined three-step process:
Dual Search: It starts by extracting entities and semantic cues from the query. Then, it combines exact matches (on N/O nodes) with vector similarity search (on S/A/H nodes) to pinpoint the most relevant entry nodes.
Shallow Personalized PageRank (PPR): From these entry points, NodeRAG performs a lightweight graph diffusion to uncover semantically related nodes across the graph.
Filtering Retrieval Nodes: In the final step, it filters out irrelevant nodes and keeps only the meaningful ones—T, S, A, H, and R nodes—to form the final result set.
This process blends structure-aware and semantic search, delivering results that are more relevant, fine-grained, and less noisy.
Thoughts and Insights
We’ve covered a number of Graph RAG improvements in the past, but NodeRAG takes a different path. Its focus is on building more detailed graph structures and integrating classic graph algorithms like PPR and K-core. In other words, NodeRAG puts the graph itself at the center of the system—treating structure not just as a storage format, but as a key to understanding knowledge.
Of course, since NodeRAG builds on traditional RAG with a much deeper use of graph algorithms, it naturally brings added complexity and new challenges—especially around structure and robustness. Two areas, in particular, still need tighter control and validation: how semantic structures are built with LLMs, and how well the graph diffusion algorithms hold up semantically.
These aren’t just technical details—they’re real hurdles that will need to be addressed as graph-enhanced RAG moves closer to real-world applications.