


AI Innovations and Insights 31: olmOCR , HippoRAG 2, and RAG Web UI
This is the 31st article in this insightful series, continuing our deep dive into compelling ideas.
In this edition, we explore two intriguing topics that promise to spark curiosity and inspire new perspectives.
olmOCR: Open-Source Multimodal LLM for Document Parsing
HippoRAG 2: A Seasoned Driver That Keeps RAG on Track
RAG Web UI: An Intelligent Dialogue System Based on RAG
olmOCR: Open-Source Multimodal LLM for Document Parsing
Code: https://github.com/allenai/olmocr
olmOCR is a newly released PDF parsing tool (My PDF parsing articles). I took a quick look at how it works and ran a simple test. Here are my thoughts.
olmOCR belongs to the OCR-free category. For OCR-free PDF parsing methods, I’ve introduced it in two articles:
Demystifying PDF Parsing 03: OCR-Free Small Model-Based Method
Demystifying PDF Parsing 04: OCR-Free Large Multimodal Model-Based Method
When you input a PDF or a document image, olmOCR utilizes document anchoring technology to extract text and metadata while incorporating visual information. This enables it to convert documents more accurately into plain text, formatted in Markdown.
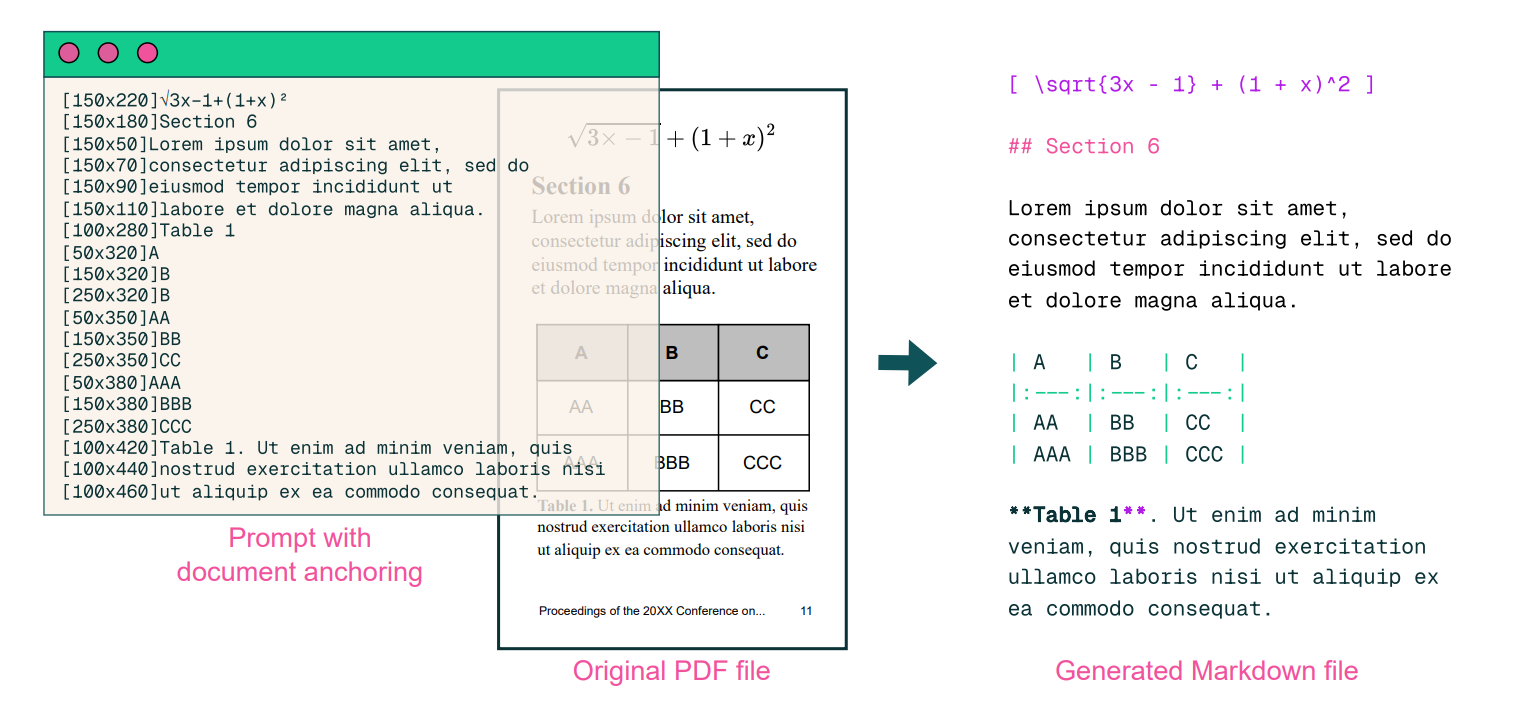
olmOCR is fine-tuned by a single model—a 7B visual language model (VLM) called Qwen2-VL-7B-Instruct.
Its training data comes from over 100,000 web-scraped PDFs and books from the Internet Archive, with annotations generated by GPT-4o. It also leverages document-anchoring technology to combine text and visual information, improving data quality.
Compared to commercial OCR solutions like GPT-4o, olmOCR can process a million pages of PDFs for just $190—32 times cheaper.
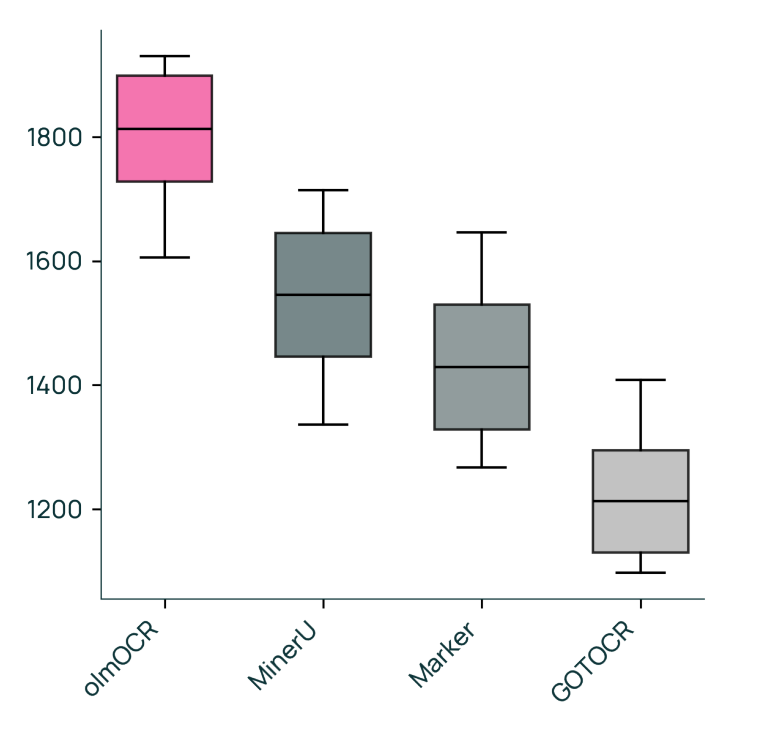
As shown in Figure 2, olmOCR outperforms other mainstream OCR tools such as Marker, MinerU, and GOT-OCR 2.0. We've covered these tools in detail before:
Keep reading with a 7-day free trial
Subscribe to AI Exploration Journey to keep reading this post and get 7 days of free access to the full post archives.