


AI Innovations and Insights 29: EdgeRAG and MinerU
This article is the 29th in this absorbing series.
Today, we will explore two enchanting topics:
EdgeRAG: A Smart Delivery Driver for Efficient RAG on Edge Devices
MinerU: A Pipeline-Based Open-Source Framework for Document Parsing
EdgeRAG: A Smart Delivery Driver for Efficient RAG on Edge Devices
Vivid Description
A traditional delivery driver (Flat Index) checks every package in the warehouse for each delivery.
In contrast, EdgeRAG is like a smart delivery driver. It keeps the most frequently used packages on the truck (embedding cache) and plans efficient routes in advance for deliveries to remote areas (precomputing and storing tail clusters) to minimize delivery time. For less common routes, it sets off only when an order is received (online embedding generation) but adapts based on order frequency (adaptive caching strategy), ensuring every delivery is fast and efficient.
Overview
While RAG reduces the need for heavyweight LLMs in generation tasks, its core relies on a vector database for similarity search. However, retrieval remains costly, mainly due to high memory usage. For example, traditional Flat Index store and sequentially search the vector representation of each data chunk, leading to high computational overhead and memory consumption.

As a result, deploying RAG on resource-constrained edge devices is highly challenging.
EdgeRAG addresses high memory usage and improves retrieval speed by incorporating various techniques into the RAG process.
Indexing Process
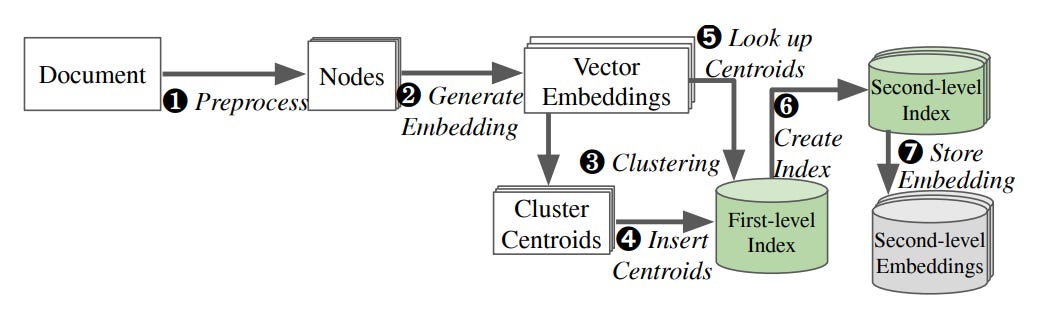
It’s well known that traditional RAG systems store embeddings for all data chunks in the index.
In contrast, as shown in Figure 2, the EdgeRAG index is based on a traditional two-level inverted file (IVF) index. The first level, which remains in memory, stores cluster centroids and references to the second-level index. The second level stores references to text chunks and manages the embedding generation latency for all data chunks.
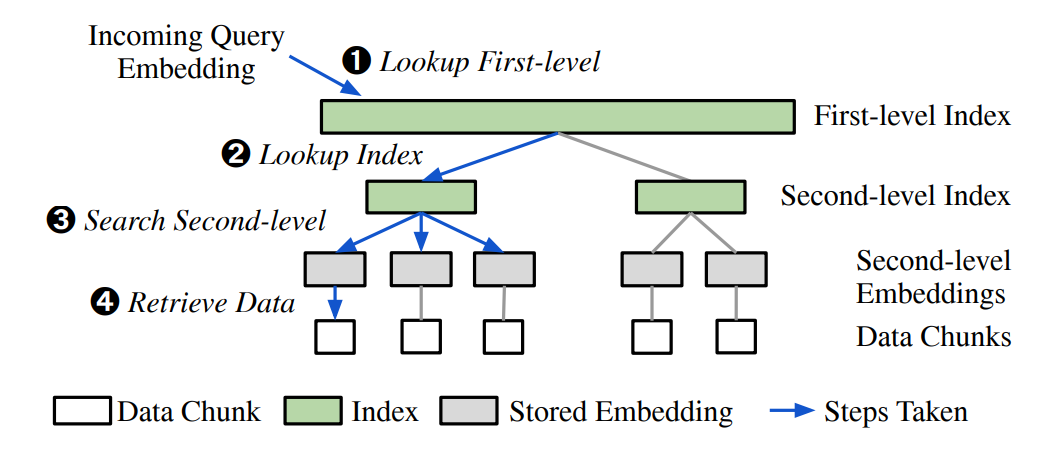
In addition, EdgeRAG reduces storage requirements by pruning unnecessary second-level embeddings and retaining only a subset. Specifically, EdgeRAG calculates the computational cost of generating embeddings for each data chunk. If the cost exceeds a predefined threshold (Service-Level Objective, SLO), the entire embedding is stored; otherwise, the embedding is discarded to optimize storage.
Figure 3 is the improved indexing process of EdgeRAG.
Retrieval Process
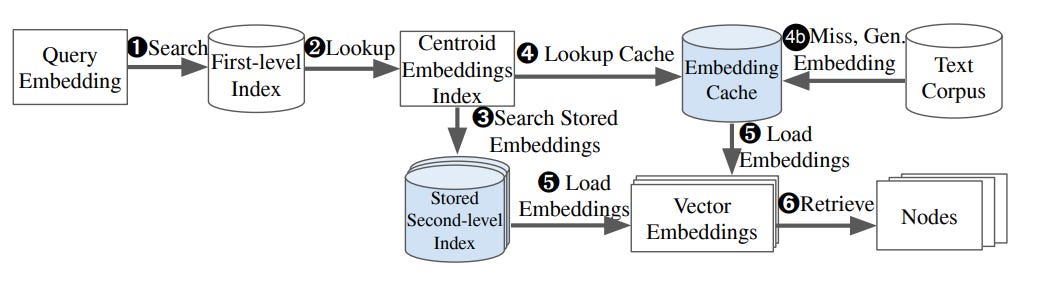
Of course, EdgeRAG's retrieval process also differs from that of traditional RAG, as shown in Figure 4.
Here’s a real-life example to illustrate EdgeRAG’s retrieval process for better understanding.
Imagine you say to your smart voice assistant at home, “Play the Seafood Paella recipe Mom mentioned last week.”
Step 1: Generate Query Embedding
The voice assistant converts your speech into text and generates a semantic vector for the query using an embedding model.
Step 2: First-Level Index Lookup
The system compares the query vector with cluster centroids in the in-memory first-level index to identify the most relevant cluster. In this example, it selects Cluster A: Food and Cooking.
Step 3: Check Stored Embeddings
The system checks whether embeddings for Cluster A are pre-stored. If stored: Skip to Step 5 to load the embeddings. If not stored: Proceed to Step 4 for a cache check.
Step 4: Embedding Cache Lookup
The system searches for Cluster A embeddings in the local cache. If cache hit: Load the embedding from the cache and continue. If cache miss: Retrieve all associated data chunks in the cluster, regenerate the embeddings, and update the cache.
Step 5: Load Embeddings and Perform Second-Level Search
The system loads the embeddings for Cluster A and performs a similarity search to find the data chunk closest to the query vector Q. In this example, the search result would be: “Mom: We could try making Seafood Paella next week.”
Step 6: Retrieve Data and Generate Response
The system extracts the complete recipe from the associated text or audio file. The voice assistant then presents the recipe either via speech or on-screen text. The final response would be: “Here’s the Seafood Paella recipe Mom mentioned last week: First, prepare short-grain rice, olive oil, tomatoes, saffron, shrimp, ...”
Commentary
Deploying RAG systems on edge devices for efficient querying, retrieval, and generation is certainly a topic worth exploring.
Overall, EdgeRAG takes an engineering-focused approach, which is often practical and beneficial for real-world applications.
That said, I have a few concerns.
The Precomputation Strategy for Long-Tail Clusters Lacks Dynamism:
EdgeRAG evaluates the generation latency (GenLatency) of each cluster during indexing. For long-tail clusters that exceed the Service-Level Objective (SLO) threshold, embeddings are precomputed and stored. However, the definition of “long-tail” is static, based solely on indexing-stage latency statistics without accounting for real-time changes in query patterns.
In real-world scenarios, certain clusters can temporarily become “hot” due to trending events (e.g., news topics), and EdgeRAG lacks the flexibility to adapt dynamically to these shifts.
To better respond to unexpected hot events, more proactive real-time monitoring and dynamic adjustment mechanisms can be considered.
Insufficient Optimization of Caching Strategies:
EdgeRAG employs a Cost-Aware Least Frequently Used (LFU) caching strategy, prioritizing replacements based on GenLatency × access frequency. The assumption here is that embeddings with high generation costs and frequent access are most worth caching. But in my view, this strategy overlooks long-term user behavior patterns common on edge devices, such as time-based preferences, recurring tasks, and context-specific access patterns.
Let's take Tom’s daily interaction with a voice assistant as an example. 7 AM: Requests news summaries. 12 PM: Searches for healthy recipes. 8 PM: Plays music playlists or family videos.
Current EdgeRAG Cache Behavior: On Tom’s first morning news request, news-related embeddings are generated on-demand and cached. By evening, these embeddings may be evicted from the cache to make room for more frequently accessed data like music or videos. The next morning, when Tom again requests the news summary, the system incurs the same embedding generation cost because it fails to recognize his daily morning routine.
Limitation: This caching strategy focuses solely on short-term access frequency, ignoring predictable, long-term user behavior patterns.
Ideal Behavior: The system should recognize Tom’s consistent morning interest in news summaries and proactively retain relevant embeddings during peak morning hours, eliminating redundant generation delays.
MinerU: A Pipeline-Based Open-Source Framework for Document Parsing
Open-source code: https://github.com/opendatalab/MinerU
We've talked quite a bit about PDF parsing and document intelligence before. Today, let's take a look at a newly emerging open-source framework that's making waves in this space.
Overview
MinerU is an open-source document parsing framework built around a pipeline architecture. It’s designed with a focus on high accuracy, support for diverse document types, and modular processing.
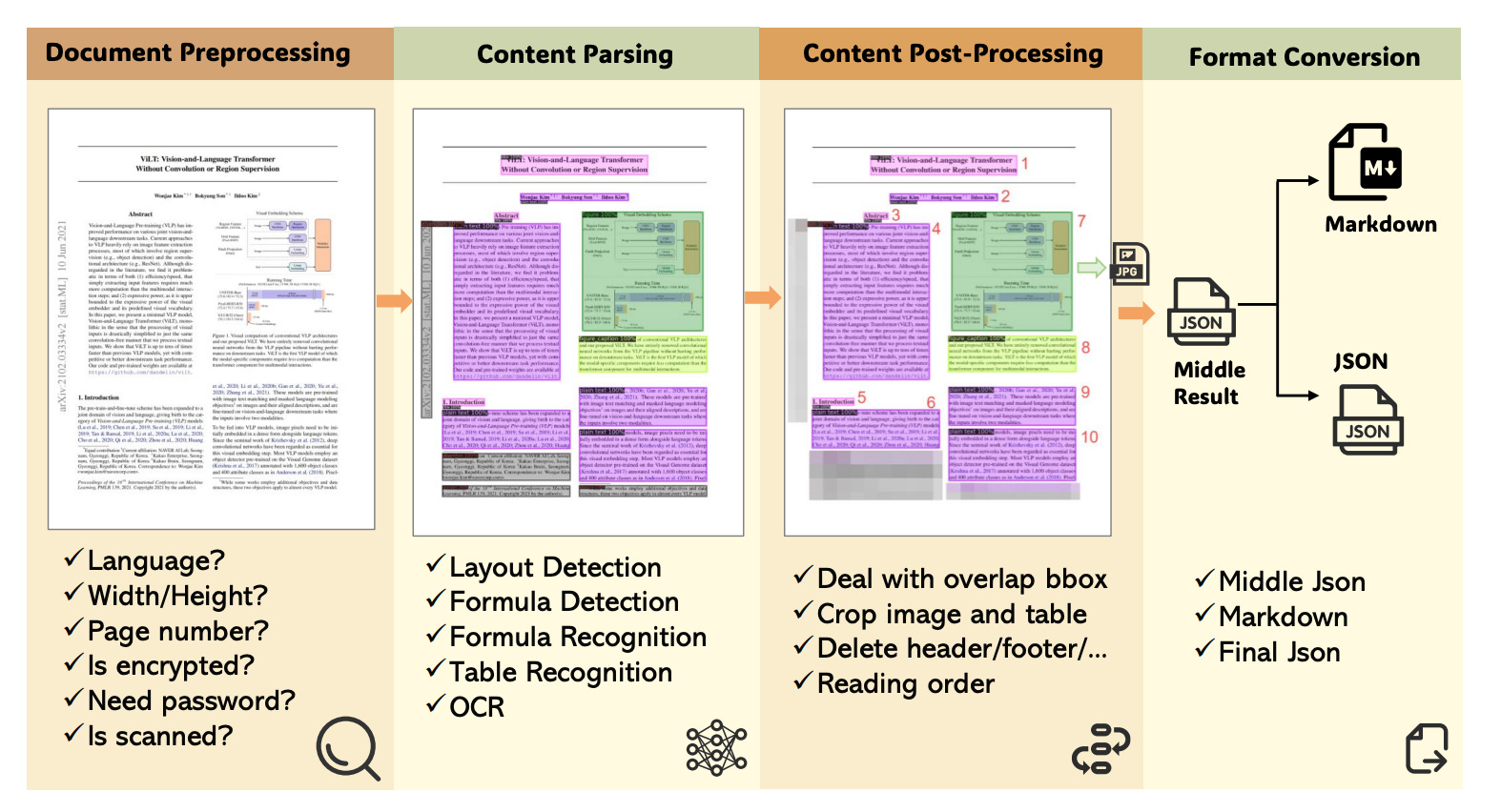
As shown in Figure 5, MinerU features a pipeline-based design, where four core components are seamlessly connected to deliver efficient and accurate document parsing.
Here’s an overview of MinerU’s workflow:
Input: PDF file containing double-column text, formulas, tables, or images.
Document Preprocessing: Checks language, page size, whether the file is scanned, and encryption status.
Content Parsing:
Layout Analysis: Distinguishes text, tables, and images.
Formula Detection and Recognition: Identifies formula types—inline, displayed, or ignored—and converts them into LaTeX format.
Table Recognition: Outputs tables in HTML/LaTeX format.
OCR: Performs text recognition for scanned PDFs.
Content Post-Processing: Fixes any sequence issues that may arise after document parsing. It ensures the final output follows a natural reading order by resolving overlaps between text, images, tables, and formula blocks, and reordering content based on human reading patterns.
Format Conversion: Generates output in Markdown or JSON format.
Output: High-quality, well-structured parsed document.
I also summarize the main models and algorithms used by MinerU, as shown in Figure 6.

Commentary
MinerU is a typical pipeline-based solution, a popular approach in the field of document parsing. It offers strong customizability, fast processing, and solid performance.
But it faces the challenge of error propagation, where mistakes in upstream modules affect downstream performance. For example, if the layout detection module fails to correctly separate text from tables, the OCR module may struggle to restore the correct text order or content. In addition, its effectiveness largely depends on the performance of each model or algorithm used in the process. Therefore, the training data and the structure of each model must be carefully designed.
Currently, MinerU supports only English and Chinese documents. In the future, adding multilingual support—such as Spanish, Arabic, and French—will be key to achieving global adoption. This goes beyond adapting OCR technology for multiple languages, it also requires recognizing document layouts and symbol systems specific to different cultures.
While MinerU provides a basic top-to-bottom, left-to-right reading order, real-world documents often involve cross-references, nested structures, and cross-page logic. Developing a more intelligent reasoning module for truly "semantic-driven" content parsing would offer significant benefits—but it also comes with considerable challenges.
Finally, if you’re interested in the series, feel free to check out my other articles.
MinerU works really well with commonly available PDFS and I'm using it for our document processing scenarios, looking forward to providing code block identification and additional processing in the future.