


AI Innovations and Trends 04: FlexRAG, KAR, and Qwen2.5-Coder

This article is the fourth in this series. Today we will explore three advancements in AI, which are:
FlexRAG: Flexible and Efficient Context Compression for RAG
KAR: Knowledge-Aware Query Expansion with LLMs for Textual and Relational Retrieval
Qwen2.5-Coder: A State-of-the-Art Multilingual Code LLM
FlexRAG: Flexible and Efficient Context Compression for RAG
Existing RAG systems must encode lengthy retrieved contexts, which involves significant computational effort. Additionally, directly using generic LLMs often leads to sub-optimal answers, while task-specific fine-tuning may compromise the LLMs’ general capabilities.
To address these issues, FlexRAG proposes a flexible approach to context compression and adaptation, allowing efficient handling of large and varied context lengths. By compressing retrieved contexts into compact, task-optimized embeddings and enabling selective preservation of crucial information, FlexRAG aims to enhance both performance and computational efficiency in RAG systems.
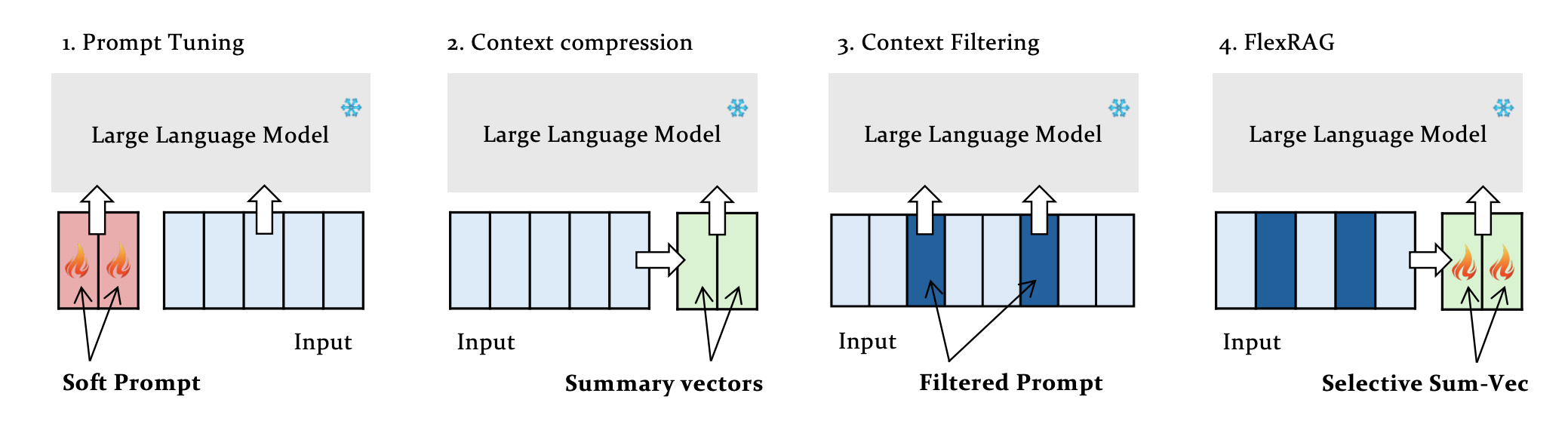
Figure 1 compares various techniques for context adaptation in RAG systems, highlighting four main approaches:
Context Compression: Token embeddings from retrieved contexts are compressed into concise summary vectors, which reduces the amount of data processed by the language model.
Context Filtering: Important tokens within the context are selectively retained while others are filtered out, enabling a more focused input for the model.
Prompt Tuning: A learned soft-prompt is incorporated to improve downstream task performance without modifying the original language model.
FlexRAG: This approach unifies the above methods by compressing contexts into embeddings that are further down-sampled based on importance, and it incorporates prompt tuning to optimize RAG performance.
Architecture

FlexRAG's implementation includes the following core aspects:
Compressive Encoder: This component transforms retrieved contexts into compressed embeddings, capturing essential information efficiently.
Selective Compression Mechanism: This mechanism applies down-sampling based on estimated context importance, selectively retaining critical information.
Two-Stage Training Workflow: FlexRAG utilizes a pre-training phase on general data and a fine-tuning phase on task-specific data, optimizing both general alignment and task performance.
Implementation
FlexRAG uses the first 8 layers of LLaMA-2-7B as the compressive encoder, with the full LLaMA-2-7B model as the downstream LLM, ensuring a fair comparison with baselines and economical experiment running.
Pre-training is performed on 90K data instances from RedPajama and 10K instances from LongAlpaca, while fine-tuning uses 10K instances from a blend of HotpotQA and the Natural Questions dataset. Training is conducted on a machine with 8×A800 GPUs.
By default, BGE-EN-large is used as the retriever, returning the top 5 documents during testing.
Commentary and Insights
Currently, FlexRAG is primarily designed for text data. Expanding its architecture to support multimodal data (e.g., images, audio) would broaden its application scenarios. This could be achieved by adding dedicated compression modules or designing cross-modal selective retention mechanisms to effectively extract and use key information across various modalities.
Although FlexRAG's two-stage training workflow enhances data utilization efficiency, training on large-scale datasets remains costly. Techniques like parameter-efficient fine-tuning (PEFT) or knowledge distillation could further reduce training costs. Additionally, exploring few-shot or zero-shot learning methods could enable FlexRAG to work effectively with minimal or even no labeled data.
KAR: Knowledge-Aware Query Expansion with LLMs for Textual and Relational Retrieval
In my previous article, we've explored classic query expansion methods like HyDE. However, these approaches primarily focus on enhancing textual similarity between search queries and target documents, overlooking the relationships between documents.
Real-world search queries often combine textual and structured elements. For example, "Find me a highly rated camera for wildlife photography compatible with my Nikon F-Mount lenses." includes both textual ("highly rated," "wildlife photography") and relational ("compatible with Nikon F-Mount lenses") requirements. Current methods often struggle with these "semi-structured" queries, frequently producing expansions that mishandle relational information.

While HyDE and RAR enrich the textual information, e.g., "wildlife" and "highly rated," they fabricate incorrect document relations, such as the compatibility of "Nikon Coolpix P1000" with "F-Mount lenses." In contrast, KAR utilizes document relations from a knowledge graph—for instance, customers who bought "Nikon Z7 II" and "F-Mount lenses" together—to generate query expansions that are both semantically similar and structurally related.
Overview
KAR is a knowledge-aware query expansion method that enhances query accuracy by integrating structured relationships from knowledge graphs with document text. Compared to traditional methods, KAR is better equipped to handle complex queries that include both textual and relational requirements, generating query expansions more aligned with user intent.

The main steps or components of KAR (Knowledge-Aware Retrieval) are as follows:
Entity Parsing: First, an LLM is used to extract explicitly mentioned entities from the original query. This identifies the key entities within the query, forming the basis for further retrieval.
Entity Document Retrieval: For each identified entity, KAR retrieves related documents from a document collection. These documents contain rich textual information that helps to build the context for query expansion.
KG Relation Propagation: Each document is linked to its corresponding entity node in the knowledge graph (KG), where relevant relationships and neighboring nodes are identified. This step gathers contextual relationship information, such as citations and co-authors, around the entities.
Document-Based Relation Filtering: Document-based relation filtering embeds both the associated documents of neighboring nodes and the query to compute their semantic similarity, selecting the most relevant neighbors for the query. This method does not rely on entity names, retaining richer textual information, and it doesn’t require re-training the model when new nodes are added to the knowledge graph.
Document Triples Construction: Document-based knowledge triples are constructed using filtered neighboring nodes and relations, including source document, relation type, and target document, to retain detailed information and structured KG relations for improved accuracy.
Knowledge-Aware Expansion: Finally, the original query, along with the relational information obtained from the KG, is input into the LLM to generate a knowledge-aware query expansion. The expanded query contains richer textual and relational information, used for the final document retrieval.
Implementation
LLM and Embedding Models: The main experiments use Azure’s GPT-4o (2024-02-01) or LLaMA-3.1-8B-Instruct as the backbone LLM. Additionally, dense embeddings from OpenAI’s text-embedding-ada-002 model are employed for calculating similarity in both query expansion and document retrieval. Some experiments also use sparse retrieval with BM25.
Knowledge Graph (KG) Parameters: 2-hop neighbors are selected to avoid computational complexity. The top-10 query-focused neighbors are filtered to optimize relation relevance without introducing excessive noise.
Commentary and Insights
“Semi-structured retrieval” is common in many real-world applications, such as product search, academic paper retrieval, and precision medicine. KAR introduces knowledge graphs (KG) to supplement structured relational information, providing a solution to this challenge.
One limitation of KAR is the issue of retrieval efficiency, especially when handling large knowledge graphs where relationship propagation and filtering can be computationally expensive.
In my opinion, to improve efficiency, consider:
Parallel Computing: Utilize distributed or parallel processing frameworks (such as Spark or Dask) to accelerate relationship propagation and filtering.
Optimized Relationship Selection: Design a more efficient filtering mechanism to minimize unnecessary computations on nodes and edges while maintaining relevant results.
Pre-computation and Caching: For frequently used relationships or queries, pre-compute and cache results to reduce the burden of real-time computation.
Qwen2.5-Coder: A State-of-the-Art Multilingual Code LLM
Open source code: https://github.com/QwenLM/Qwen2.5-Coder
The Qwen2.5-Coder series comprises six models: Qwen2.5-Coder-(0.5B/1.5B/3B/7B/14B/32B). Built on the Qwen2.5 architecture, this series underwent further pretraining on an extensive corpus exceeding 5.5 trillion tokens.
Qwen2.5-Coder demonstrates state-of-the-art (SOTA) performance across over 10 benchmarks, including code generation, completion, reasoning, and repair. Notably, it consistently outperforms LLMs within the same size category.
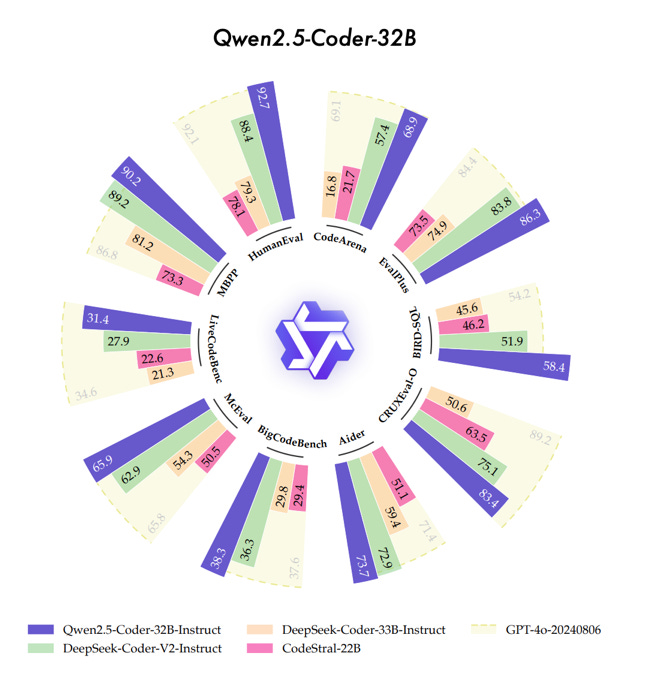
Pretraining Data
The data processing for Qwen2.5 mainly includes the following steps:
Data Composition:
Source Code Data: Collected data on 92 programming languages from GitHub and other platforms, rigorously filtered through specific rules.
Text-Code Grounding Data: Sourced code-related documents from Common Crawl, ensuring data quality through hierarchical filtering.
Synthetic Data: Generated large-scale executable synthetic data using CodeQwen1.5.
Math and General Text Data: Extracted from Qwen2.5-Math and Qwen2.5 pre-training data to enhance the model’s mathematical capabilities and natural language understanding.
Data Mixing Strategy: Employed a mix of 70% code, 20% text, and 10% math data, totaling 5.2 trillion tokens, providing a solid foundation for the model’s multi-task capabilities.
Training Policy

The training strategy for Qwen2.5-Coder consists of four key steps:
File-Level Pretraining: Focuses on individual files with sequences up to 8,192 tokens. Training objectives include next-token prediction and "Fill-in-the-Middle" (FIM), which improves code completion capabilities.

Figure 7: File-Level FIM format. Source: Qwen2.5-Coder. Repo-Level Pretraining: Extends to repository-level data, supporting context lengths up to 32,768 tokens and, through the RoPE and YaRN mechanism, processing sequences as long as 131,072 tokens. Emphasizes cross-file dependencies using a "Repo-Level FIM" format, integrating information from multiple files and paths.

Figure 8: Repo-Level FIM format. Source: Qwen2.5-Coder. Fine-Tuning Policy:
Coarse-to-Fine Fine-Tuning: Initial training with a large quantity of lower-quality samples is refined with high-quality instruction data, leveraging rejection sampling for optimal fine-tuning outcomes.
Mixed Tuning for Long Contexts: Instruction pairs are structured to maintain long-context capabilities, using abstract syntax trees (ASTs) to format code snippets for middle code insertion tasks.
Direct Preference Optimization (DPO) with Execution-Based Feedback: The model incorporates multilingual sandbox environments to validate code execution. It uses both automated testing and LLM-based judgment for complex snippets, ensuring code accuracy and alignment with user expectations.


Instruction Data
In addition, let's discuss the construction of instruction-tuning data for Qwen2.5-Coder.
Multilingual Code Identification: Uses the CodeBERT model to recognize around 100 programming languages, prioritizing major languages and filtering out low-quality samples.
Instruction Generation from GitHub: Utilizes an LLM to create instruction-response pairs from GitHub snippets, with scoring to retain high-quality data. McEval-Instruct and similar datasets are included.
Multilingual Instruction Generation: A multi-agent framework facilitates collaboration and knowledge sharing across languages, enhancing diversity and coverage of instruction data.
Checklist-Based Scoring: Instruction data is scored on multiple dimensions, such as consistency, code accuracy, and educational value.
Example
Below is an example on how to chat with Qwen2.5-Coder-32B:
from transformers import AutoTokenizer, AutoModelForCausalLM
device = "cuda" # the device to load the model onto
# Now you do not need to add "trust_remote_code=True"
TOKENIZER = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-Coder-32B")
MODEL = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2.5-Coder-32B", device_map="auto").eval()
# tokenize the input into tokens
input_text = "#write a quick sort algorithm"
model_inputs = TOKENIZER([input_text], return_tensors="pt").to(device)
# Use `max_new_tokens` to control the maximum output length.
generated_ids = MODEL.generate(model_inputs.input_ids, max_new_tokens=512, do_sample=False)[0]
# The generated_ids include prompt_ids, so we only need to decode the tokens after prompt_ids.
output_text = TOKENIZER.decode(generated_ids[len(model_inputs.input_ids[0]):], skip_special_tokens=True)
print(f"Prompt: {input_text}\n\nGenerated text: {output_text}")Commentary and Insights
Overall, Qwen2.5-Coder presents several notable advancements, making it a powerful and flexible tool in the code model landscape.
While Qwen2.5-Coder shows impressive performance, there are areas for potential improvement:
Long-Context Efficiency: Incorporating more efficient context compression or hierarchical encoding methods could enable it to handle larger codebases while reducing computational demands.
Domain-Specific Tailoring: Enhance relevance in professional domains by fine-tuning on field-specific datasets for areas like machine learning and fintech.
Conclusion
This exploration of FlexRAG, KAR, and Qwen2.5-Coder underlines how rapid advancements in AI are increasingly offering specialized solutions that can be customized to meet the diverse and nuanced demands of applications.
As the field progresses, we can anticipate further innovations that enhance usability, efficiency, and performance across a widening array of complex tasks.
Finally, if you’re interested in the series, feel free to check out my other articles.