


AI Innovations and Insights 24: rStar, SimRAG, and mR2AG
This article is the 24th in this compelling series. Today, we will explore three intriguing topics in AI, which are:
rStar: Two Minds, One Solution
SimRAG: A Self-Improving Student that Learns by Generating and Answering Its Own Questions
mR2AG: Intelligent Navigation System for Knowledge-Based VQA
rStar: Two Minds, One Solution
Open-source code: https://github.com/zhentingqi/rStar/
This article will first explore the principles of rStar.
Although the rStar series recently updated rStar-math, we will proceed step by step.
Vivid Description
rStar can be seen as a process where two students work together to solve a math problem:
The first student (Generator) explores different approaches to solving the problem, like mapping out multiple solution paths on a tree diagram (Monte Carlo Tree Search (MCTS)). The second student (Discriminator) reviews each step to ensure its correctness, much like checking a classmate’s draft. Through mutual verification, they narrow down the most likely correct solution.
It’s a collaborative approach, combining brainstorming and review, to break down complex problems and find the best solution.
Overview
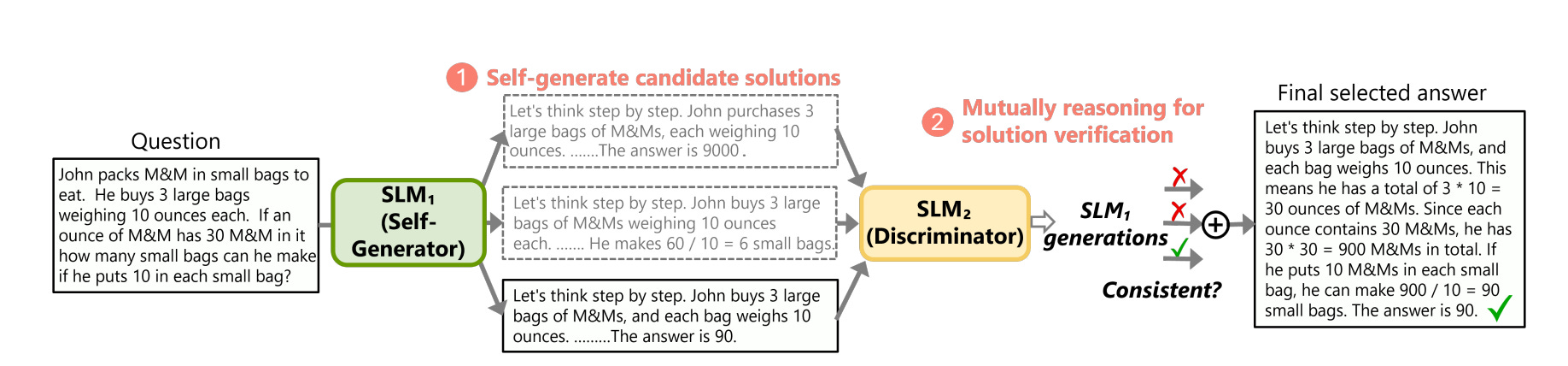
The main process of rStar is shown in Figure 1:
A self-generator enhances the target Small Language Model (SLM) to create potential reasoning paths using MCTS.
The discriminator, using another SLM, provides unsupervised feedback on each path based on partial hints.
Based on this feedback, the target SLM selects the final reasoning path as the solution.
In the MCTS process, as illustrated in Figure 2, a search tree is incrementally built by augmenting a target SLM for a given problem.
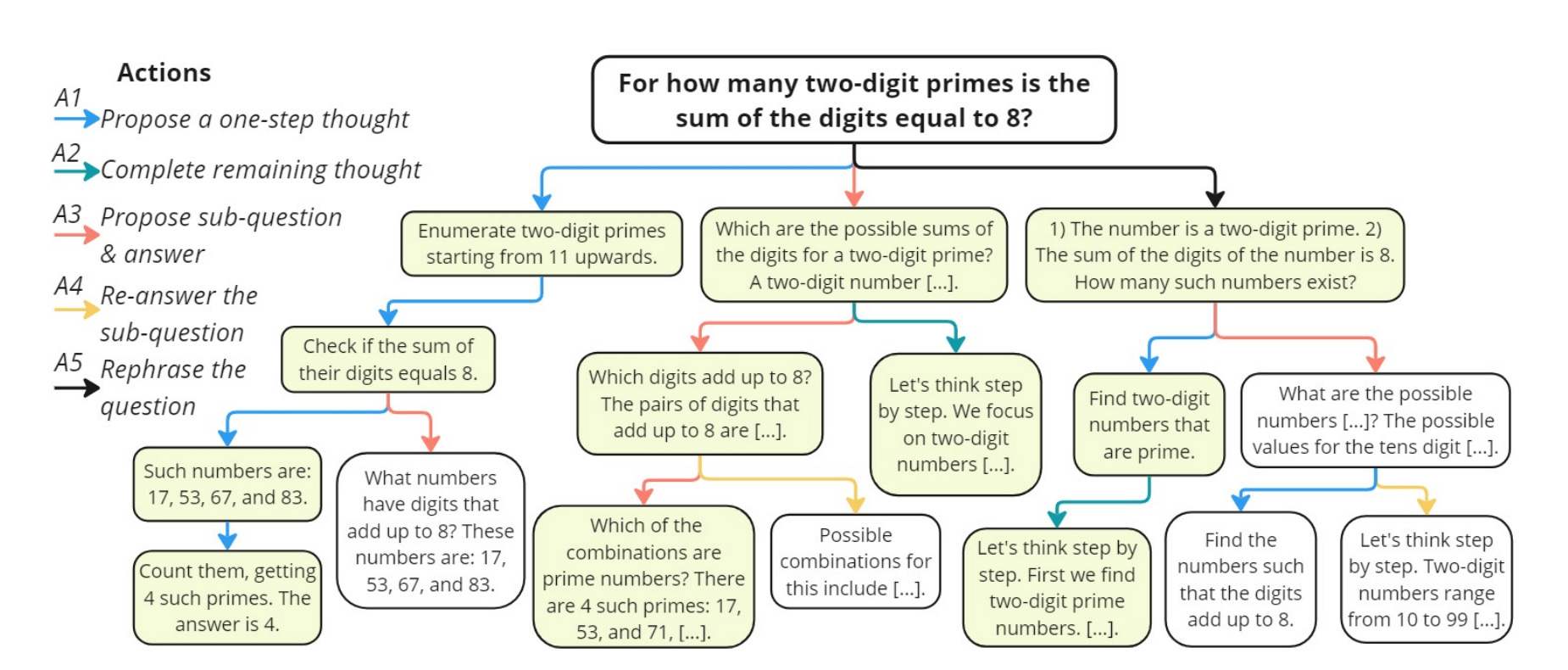
The root node represents the question x, while each edge represents an action a. Each child node is an intermediate step s that the target SLM generates under the corresponding action. A path from the root node to a leaf node (denoted as sd, also called a terminal node) forms a candidate solution trajectory t = x ⊕ s1 ⊕ s2 ⊕ ... ⊕ sd.
From the search tree, a set of solution trajectories can be extracted. The goal is to find trajectories that can reach the correct answer for the given question.
MCTS: Reward
The reward function guides tree expansion by evaluating actions. To keep it simple and effective for SLMs, self-rewarding intermediate nodes and external supervision are avoided. Inspired by AlphaGo, nodes are scored based on their contribution to the final correct answer, with frequently successful actions receiving higher rewards.
Initially, all unexplored nodes have Q(si,ai)=0, leading to random expansions. When a terminal node nd is reached, its reward Q(sd,ad) is determined by whether it produces the correct answer. This reward is then backpropagated along the trajectory, updating intermediate nodes. The final reward is based on self-consistency majority voting confidence.
MCTS: Selection
Starting from the root node, MCTS searches through selection, expansion, simulation, and backpropagation. Simulations use a default rollout policy, with multiple rollouts improving reward estimation. To balance exploration and exploitation, UCT (Upper Confidence Bounds applied to Trees) guides node selection, mathematically represented as:
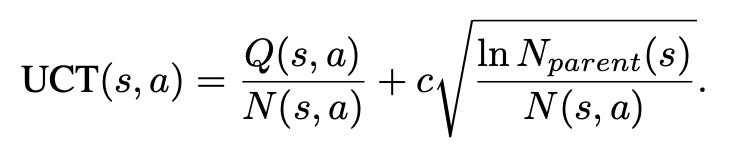
Commentary
rStar stands out for its innovative approach, combining a small language model with no need for fine-tuning, making it cost-effective. I can sense the idea of AlphaGo Zero's self-play in this.
In addition, its open-source code is comprehensive and well-documented.
However, I have two concerns.
rStar provides a rich action space (such as A1, A3, etc.) to generate reasoning paths, allowing the generator to try different reasoning approaches. Although the action space is rich, its selection and execution are still manually designed and lack dynamic adjustment for different tasks and scenarios. This may limit the algorithm's generality and adaptability.
In rStar's reasoning algorithm, there are no clearly detailed termination conditions, and the stopping of the reasoning process seems to depend on external configurations, such as simulation count or computation time limits. To optimize its efficiency in practical applications, clear and flexible termination conditions are essential, especially in cases where the reasoning space is large or computational resources are limited.
SimRAG: A Self-Improving Student that Learns by Generating and Answering Its Own Questions
Vivid Description
Imagine a student who doesn't just read books while studying but actively creates questions to test their understanding. This "self-questioning" approach helps students understand the book more deeply.
SimRAG works just like such a student, using unlabeled data to generate questions and answers, then using these self-created "questions" and "answers" to further improve its learning effectiveness.
Overview
When adapting from general domains to specialized fields like science or medicine, existing RAG systems face challenges such as distribution shift and data scarcity.
SimRAG is a self-improving method that enables models to generate high-quality question-answer pairs in specialized domains while enhancing model performance.
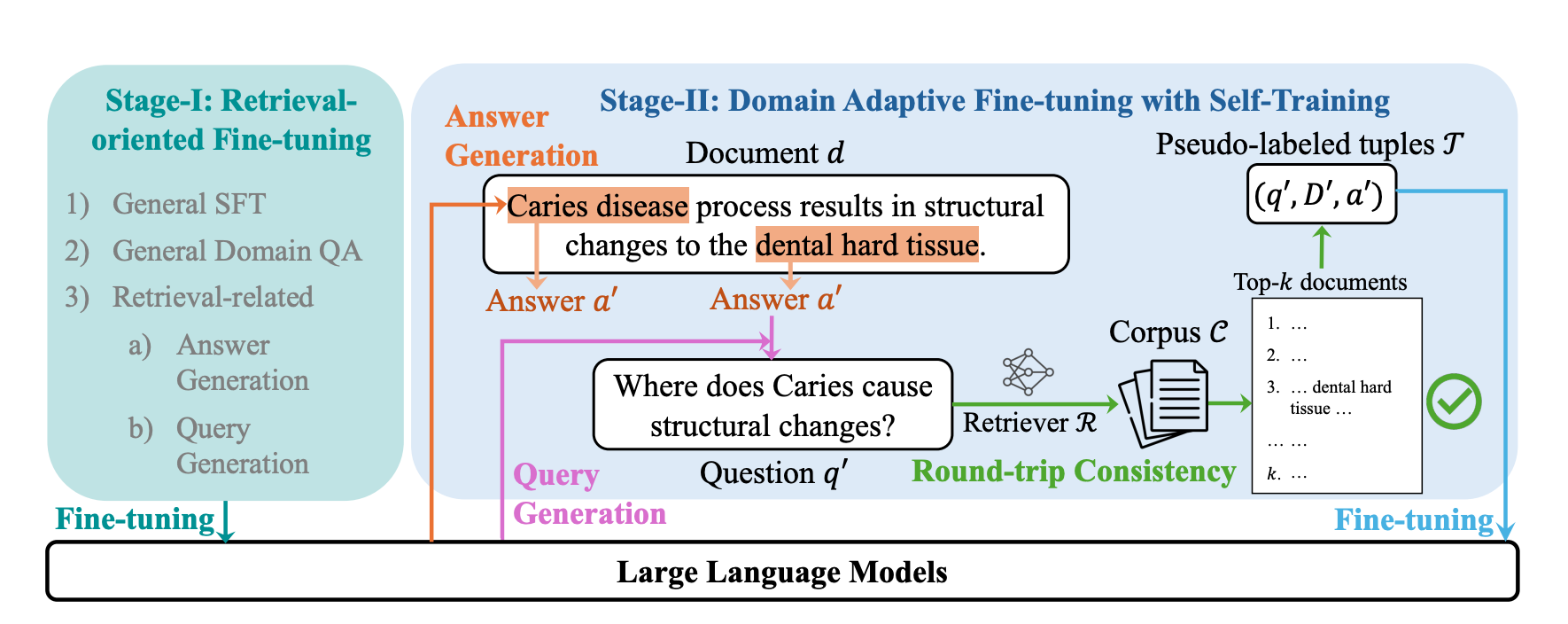
As shown in Figure 3, SimRAG consists of two stages:
Fine-tuning the model on retrieval-related data, including instruction-following, question-answering, and search-related tasks.
Generating pseudo-labeled tuples by extracting candidate answers from the corpus, followed by generating candidate questions conditioned on both the document and the answer. The LLM is further fine-tuned on pseudo-labeled examples filtered through round-trip consistency.
Commentary
SimRAG's implementation approach is actually fine-tuning. The key idea is that the fine-tuning data in the second phase is obtained through a self-supervised process and round-trip consistency filtering.
In my view, it's important to note that the generated pseudo-labels may be inaccurate, inconsistent, or unable to fully match the true answers. It is necessary to introduce more quality control mechanisms.
mR2AG: Intelligent Navigation System for Knowledge-Based VQA
Vivid Description
mR2AG works like an intelligent navigation system with two innovations:
Retrieval-Reflection is like the system asking, "Do you want to drive or take a walk?" If you're just exploring nearby, you don’t need directions to far-off places.
Relevance-Reflection is like the system selects the best route for your needs, highlighting the key landmarks without overwhelming you with unnecessary details.
In short, mR2AG helps you get to your destination (the answer) quickly and efficiently by planning the route and cutting out the noise.
Overview
As shown in Figure 4, current methods for Visual-dependent and Knowledge-based VQA tasks are as follows:
Multimodal LLMs: Use image and question inputs, but struggle with recent knowledge-based VQA tasks
Multimodal RAG: Unnecessary retrieval; Poor evidence identification; Complex filtering mechanisms
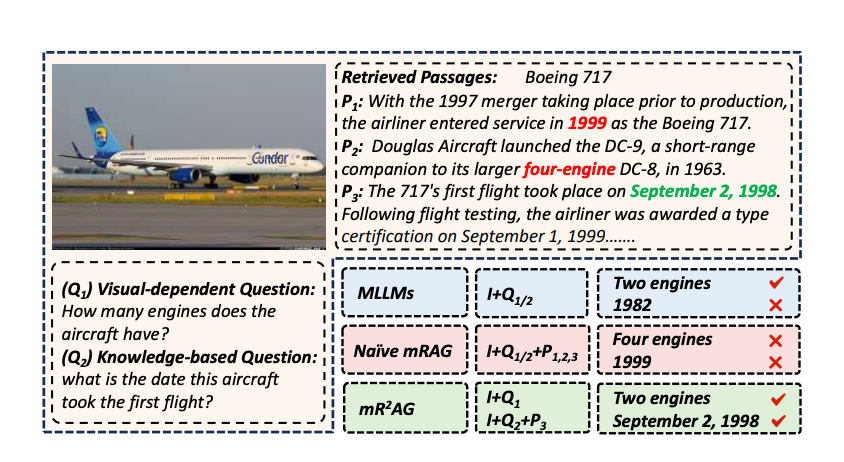
Therefore, a natural idea is whether we can adaptively determine the necessity of retrieval and effectively locate the useful context, just like P3 for Q2 in Figure 4, which is exactly the concept behind mR2AG.
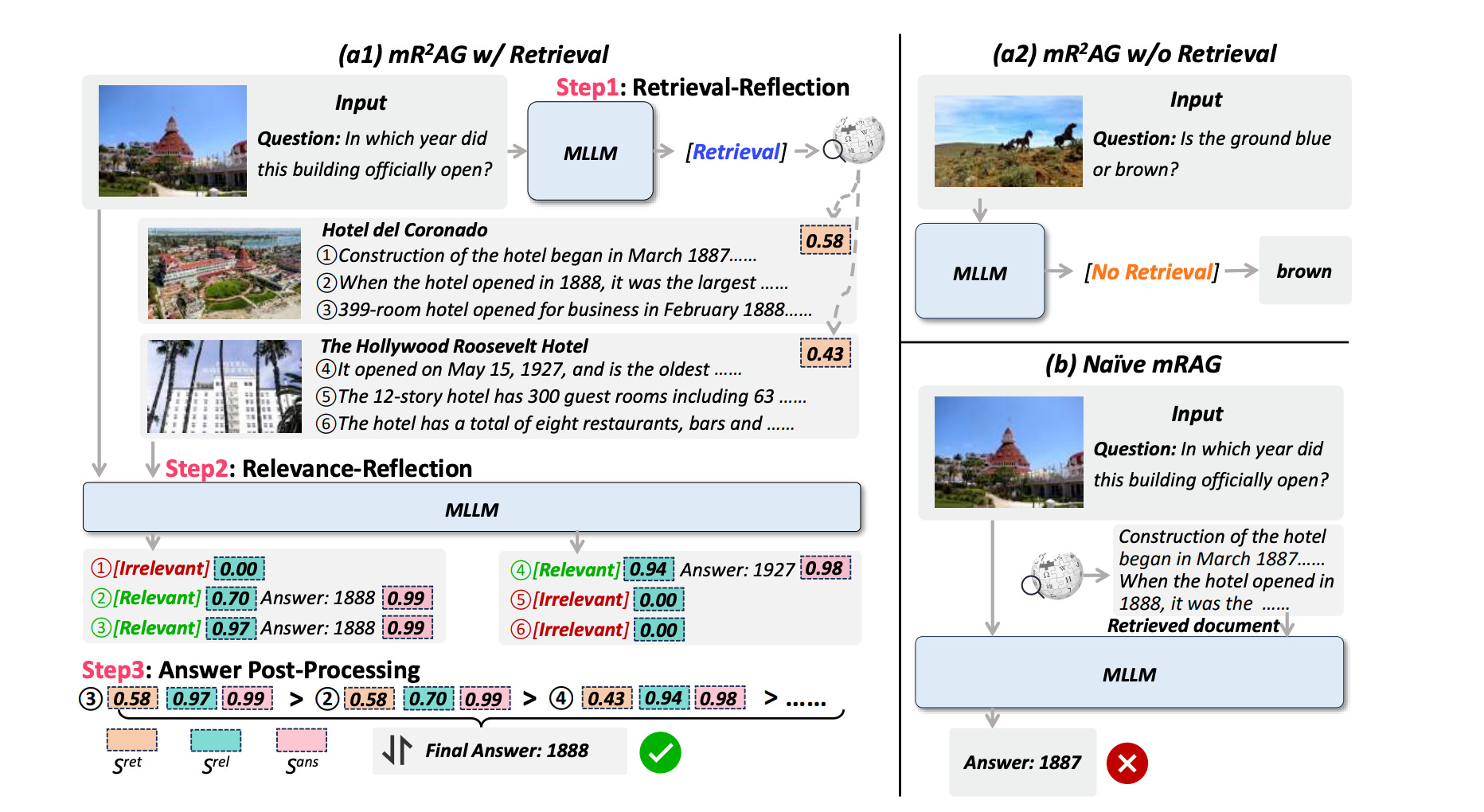
As shown in Figure 5, mR2AG pipeline is divided into three stages:
Retrieval-Reflection: Determines whether external knowledge retrieval is necessary based on the nature of the query, this idea is similar to self-RAG.
Relevance-Reflection: Filters retrieved passages to locate the most relevant evidence for answer generation.
Answer Post-Processing: Answers from multiple passages are ranked based on combined retrieval, relevance, and confidence scores.
Commentary
Like self-RAG, mR2AG uses model fine-tuning to incorporate simple decision-making and reflection mechanisms into its workflow.
While mR2AG shows strong results, in my view, the following concerns still remain:
Some questions may require both visual information and knowledge retrieval (such as "What is the natural habitat of the animal in this image?"). Can mR2AG accurately judge these blurred boundaries?
The scoring system multiplies Entry-Level, Passage-Level, and Answer-Level scores, but questions remain about weight optimization and potential ranking biases from low individual scores. How are the relative weights between these scores determined? Are these weights universally applicable across different tasks?
Finally, if you’re interested in the series, feel free to check out my other articles.