
Advanced RAG 08: Self-RAG
Intuitive Example, Priciples, Code Explanation and Insights about Self-RAG

This article begins with a common scenario: taking an open-book exam. We usually have two strategies:
Method 1: For familiar topics, answer quickly; for unfamiliar ones, open the reference book to look them up, quickly find the relevant parts, sort and summarize them in your mind, then answer on the exam paper.
Method 2: For every topic, refer to the book. Locate the pertinent sections, mentally collate and summarize them, then write your response on the exam paper.
Evidently, method 1 is the preferred approach. Method 2 can consume time and potentially introduce irrelevant or erroneous information, this may lead to confusion and mistakes, even in areas you originally understood.
However, method 2 exemplifies the classic RAG process, while method 1 represents the self-RAG process, which this article will further discuss.
Overview
Figure 1 illustrates a comparison between the main processes of RAG and self-RAG:

Self-RAG consists of three steps:
Retrieval as Needed: When the model requires retrieval, such as the query “How did US states get their names?” (the top right of Figure 1), the model’s output will contain a
[Retrieve]token. This indicates that content related to the query needs to be retrieved. Conversely, when asked to write “Write an essay on your best summer vacation” (the bottom right of Figure 1), the model opts to generate the answer directly, without retrieval.Parallel Generation: The model uses both the prompt and the retrieved content to generate outputs. Throughout this process, three types of reflection tokens indicate the relevance of the retrieved content.
Evaluation and Selection: The content generated in step 2 is evaluated and the best segment is chosen as the output.
Note that the model mentioned above is a specially trained model. Its training process will be discussed later in this article.
Reflection Tokens
Compared to RAG, the difference of the self-RAG framework is that it uses reflection tokens for more precise control during generation, as shown in Figure 2.

Essentially, self-RAG makes four distinct judgments:
[Retrieve]: A decision process that determines whether to retrieve information from a resourceR.[IsREL]: A relevancy check to determine whether the given datadcontains the information required to solve problemx.[IsSUP]: A verification process that checks if the statements in the provided responseyare supported by datad.[IsUSE]: An evaluation process that assesses the usefulness of responseyfor problemx. The output is a score ranging from 1 to 5, where 5 represents the highest usefulness.
In RAG, retrieval is a fixed process, always conducted initially, regardless of the condition. In contrast, self-RAG introduces reflective tokens, making LLM more adaptable and intelligent. When LLM generates text and encounters an area of uncertainty, it pauses at the reflective token, performs a quick and precise retrieval, and then resumes generation using the newly acquired information.
Code Explanation
To intuitively understand the self-RAG process, we will first examine the code, and then discuss the model’s training process.
Self-RAG is open-source, and both Langchain and LlamaIndex have their respective implementations. We’ll use LlamaIndex’s implementation as a reference for our explanation.
Environment Configuration
First, configure the environment.
(base) Florian@instance-1:~$ conda create -n llamaindex python=3.11
(base) Florian@instance-1:~$ conda activate llamaindex
(llamaindex) Florian@instance-1:~$ pip install llama-index
(llamaindex) Florian@instance-1:~$ pip install huggingface-hub
(llamaindex) Florian@instance-1:~$ huggingface-cli loginAfter the installation, the corresponding version of LlamaIndex are as follows:
llama-index 0.10.20
llama-index-core 0.10.20.post2Download the Llama2–7B model provided by the paper, approximately 4.08G.
(llamaindex) Florian@instance-1:~$ huggingface-cli download m4r1/selfrag_llama2_7b-GGUF selfrag_llama2_7b.q4_k_m.gguf --local-dir "YOUR_DOWNLOAD_MODEL_DIR" --local-dir-use-symlinks False
(llamaindex) Florian@instance-1:~$ ls "YOUR_DOWNLOAD_MODEL_DIR"
selfrag_llama2_7b.q4_k_m.ggufTest Code
The test code is as follows. The first execution requires the download of SelfRAGPack.
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"
from llama_index.core import Document, VectorStoreIndex
from llama_index.core.retrievers import VectorIndexRetriever
from llama_index.core.readers import SimpleDirectoryReader
from pathlib import Path
# Option: download SelfRAGPack
# The first execution requires the download of SelfRAGPack.
# Subsequent executions can comment this out.
from llama_index.core.llama_pack import download_llama_pack
download_llama_pack(
"SelfRAGPack",
"./self_rag_pack")
from llama_index.packs.self_rag import SelfRAGQueryEngine
# The directory where the Llama2 model was previously downloaded and saved.
download_dir = "YOUR_DOWNLOAD_MODEL_DIR"
# Create testing documents
documents = [
Document(
text="A group of penguins, known as a 'waddle' on land, shuffled across the Antarctic ice, their tuxedo-like plumage standing out against the snow."
),
Document(
text="Emperor penguins, the tallest of all penguin species, can dive deeper than any other bird, reaching depths of over 500 meters."
),
Document(
text="Penguins' black and white coloring is a form of camouflage called countershading; from above, their black back blends with the ocean depths, and from below, their white belly matches the bright surface."
),
Document(
text="Despite their upright stance, penguins are birds that cannot fly; their wings have evolved into flippers, making them expert swimmers."
),
Document(
text="The fastest species, the Gentoo penguin, can swim up to 36 kilometers per hour, using their flippers and streamlined bodies to slice through the water."
),
Document(
text="Penguins are social birds; many species form large colonies for breeding, which can number in the tens of thousands."
),
Document(
text="Intriguingly, penguins have excellent hearing and rely on distinct calls to identify their mates and chicks amidst the noisy colonies."
),
Document(
text="The smallest penguin species, the Little Blue Penguin, stands just about 40 cm tall and is found along the coastlines of southern Australia and New Zealand."
),
Document(
text="During the breeding season, male Emperor penguins endure the harsh Antarctic winter for months, fasting and incubating their eggs, while females hunt at sea."
),
Document(
text="Penguins consume a variety of seafood; their diet mainly consists of fish, squid, and krill, which they catch on their diving expeditions."
),
]
index = VectorStoreIndex.from_documents(documents)
# Setup a simple retriever
retriever = VectorIndexRetriever(
index=index,
similarity_top_k=10,
)
model_path = Path(download_dir) / "selfrag_llama2_7b.q4_k_m.gguf"
query_engine = SelfRAGQueryEngine(str(model_path), retriever, verbose=True)
# No retreival example
response = query_engine.query("Which genre the book pride and prejudice?")
# Retreival example
response = query_engine.query("How tall is the smallest penguins?")The test code produced the following result(most of the llama_cpp debugging information has been removed.):
...
...
Model metadata: {'tokenizer.ggml.add_eos_token': 'false', 'tokenizer.ggml.eos_token_id': '2', 'general.architecture': 'llama', 'llama.rope.freq_base': '10000.000000', 'llama.context_length': '4096', 'general.name': 'LLaMA v2', 'tokenizer.ggml.add_bos_token': 'true', 'llama.embedding_length': '4096', 'llama.feed_forward_length': '11008', 'llama.attention.layer_norm_rms_epsilon': '0.000010', 'llama.rope.dimension_count': '128', 'tokenizer.ggml.bos_token_id': '1', 'llama.attention.head_count': '32', 'llama.block_count': '32', 'llama.attention.head_count_kv': '32', 'general.quantization_version': '2', 'tokenizer.ggml.model': 'llama', 'general.file_type': '15'}
Using fallback chat format: None
llama_print_timings: load time = 4887.53 ms
llama_print_timings: sample time = 11.29 ms / 22 runs ( 0.51 ms per token, 1947.76 tokens per second)
llama_print_timings: prompt eval time = 4887.46 ms / 24 tokens ( 203.64 ms per token, 4.91 tokens per second)
llama_print_timings: eval time = 5883.27 ms / 21 runs ( 280.16 ms per token, 3.57 tokens per second)
llama_print_timings: total time = 10901.84 ms / 45 tokens
Final answer: The book "Pride and Prejudice" is a romantic novel by Jane Austen.
...
...
llama_print_timings: load time = 4887.53 ms
llama_print_timings: sample time = 11.74 ms / 20 runs ( 0.59 ms per token, 1703.29 tokens per second)
llama_print_timings: prompt eval time = 7473.66 ms / 37 tokens ( 201.99 ms per token, 4.95 tokens per second)
llama_print_timings: eval time = 5414.34 ms / 19 runs ( 284.96 ms per token, 3.51 tokens per second)
llama_print_timings: total time = 13076.88 ms / 56 tokens
Input: ### Instruction:
How tall is the smallest penguins?
### Response:
[Retrieval]<paragraph>Penguins consume a variety of seafood; their diet mainly consists of fish, squid, and krill, which they catch on their diving expeditions.</paragraph>
Prediction: [Relevant]The height of the smallest penguin species can vary depending on the species.[No support / Contradictory][Utility:5]
Score: 1.4213598342974367
10/10 paragraphs done
End evaluation
Selected the best answer: [Relevant]The smallest penguin species is the Little Blue Penguin (also known as the Fairy Penguin), which can grow to be around 40 centimeters (16 inches) in height.[Fully supported][Utility:5]
Final answer: The smallest penguin species is the Little Blue Penguin (also known as the Fairy Penguin), which can grow to be around 40 centimeters (16 inches) in height.We can observe that the first query does not require retrieval, whereas the second query has been retrieved and evaluated.
The key to understanding the test code lies in the implementation of class SelfRAGQueryEngine, let’s delve into the class.
class SelfRAGQueryEngine
First is the constructor, which is mainly used to load Llama2–7B model using llama_cpp.
class SelfRAGQueryEngine(CustomQueryEngine):
"""Simple short form self RAG query engine."""
llm: Any = Field(default=None, description="llm")
retriever: BaseRetriever = Field(default=None, description="retriever")
generate_kwargs: Dict = Field(default=None, description="llm generation arguments")
verbose: bool = Field(default=True, description="Verbose.")
def __init__(
self,
model_path: str,
retriever: BaseRetriever,
verbose: bool = False,
model_kwargs: Dict = None,
generate_kwargs: Dict = None,
**kwargs: Any,
) -> None:
"""Init params."""
super().__init__(verbose=verbose, **kwargs)
model_kwargs = model_kwargs or _MODEL_KWARGS
self.generate_kwargs = generate_kwargs or _GENERATE_KWARGS
try:
from llama_cpp import Llama
except ImportError:
raise ImportError(_IMPORT_ERROR_MSG)
self.llm = Llama(model_path=model_path, verbose=verbose, **model_kwargs)
self.retriever = retrieverNext, we will explain the query function. Its main process is shown in Figure 3:

Key parts have been commented for better understanding.
def custom_query(self, query_str: str) -> Response:
"""Run self-RAG."""
# Obtain responses using the Llama2 model.
response = self.llm(prompt=_format_prompt(query_str), **_GENERATE_KWARGS)
answer = response["choices"][0]["text"]
source_nodes = []
# Determine if a retrieval is necessary.
if "[Retrieval]" in answer:
if self.verbose:
print_text("Retrieval required\n", color="blue")
# The step 1 of Figure 1, retrieve as needed.
documents = self.retriever.retrieve(query_str)
if self.verbose:
print_text(f"Received: {len(documents)} documents\n", color="blue")
paragraphs = [
_format_prompt(query_str, document.node.text) for document in documents
]
if self.verbose:
print_text("Start evaluation\n", color="blue")
# Step 2 and 3 in Figure 1, generate in parallel and evaluate
# (the code does not implement parallelism)
critic_output = self._run_critic(paragraphs)
paragraphs_final_score = critic_output.paragraphs_final_score
llm_response_per_paragraph = critic_output.llm_response_per_paragraph
source_nodes = critic_output.source_nodes
if self.verbose:
print_text("End evaluation\n", color="blue")
# Select the paragraph with the highest score and return it.
best_paragraph_id = max(
paragraphs_final_score, key=paragraphs_final_score.get
)
answer = llm_response_per_paragraph[best_paragraph_id]
if self.verbose:
print_text(f"Selected the best answer: {answer}\n", color="blue")
answer = _postprocess_answer(answer)
if self.verbose:
print_text(f"Final answer: {answer}\n", color="green")
return Response(response=str(answer), source_nodes=source_nodes)From the code, we see that all three steps in Figure 1 are represented. However, the LlamaIndex’s code does not implement parallelization. For further information, interested readers can examine the self._run_critic function, it also handles the scores corresponding to various reflection tokens.
How to train the Llama2–7B model
We have used the Llama2–7B model many times before, let’s explore how to get it.
Training Goals
Enable language model to generate text that includes reflection tokens.
Two Models
During the training process, two models are needed: an critic model C and a generator model M. The critic model C generates the supervision data required by model M.
However, during the inference process, only model M is used and model C is not required.
Critic model C
The critic model is trained to generate reflection tokens. The purpose of using this model is to enable the insertion of reflection tokens into the task output offline, which updates the training corpus.
Manual annotation of reflection tokens for each segment is expensive. Self-RAG utilizes GPT-4 to assign unique instruction for each reflection token due to their varying definitions, inputs, and outputs, thereby efficiently completing the data annotation task. For instance, the [retrieval] token’s instruction prompts the GPT-4 to assess whether incorporating external documents will enhance the results.
Once we’ve obtained the training data D_critic, we can construct training objectives based on the standard conditional language model as follows:
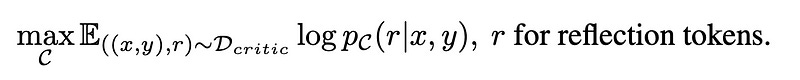
The critic model C can be initialized with any language model. For instance, it can be initialized with the same model as the generator, such as Llama2–7B.
Generator model M
Figure 4 displays the specific process of collecting training data. Given an input-output pair (x, y), self-RAG augment the original output y using the retrieval and critic models to create supervised data. For each segment yt ∈ y:

Note that every condition judgment in Figure 4 is executed via the critic model C. The training data obtained is depicted in Figure 5:

After obtaining the training data D_gen, we can construct the standard next-token prediction objective function as follows:

The generator M is required to predict not only the output but also the reflection tokens.
My Insights and Thoughts on self-RAG
Generally, self-RAG offers a new perspective for enhancing the RAG process. However, it demands a more intricate training procedure and multiple label generation and judgments during the generation phase, inevitably increasing the inference cost. This could significantly affect projects that require real-time performance.
Furthermore, there’s ample room for optimization within this framework. To spark further discussion and innovation, here are a few points:
How to optimize reflection tokens. Self-RAG has designed four reflection tokens. Aside from the
[Retrieve]token, the other three([IsREL],[IsSUP],[IsUSE]) have certain similarities. Considering the use of fewer reflection tokens or reflection tokens that represent other semantics is a viable direction.Why does the critic model use LLM? I think it might be due to tokens like
[IsUSE], which rely heavily on common knowledge. Judging the usefulness of an answer to a query is a task that smaller models could potentially accomplish. However, these models usually only learn from their specific training data and lack the comprehensive knowledge. Therefore, it makes sense to use LLM as the critic model.Choice of Critic Model Size. Self-RAG has been tested with the 7B and 13B models, yielding excellent results. However, what differences could we observe if we switched to a smaller LLM, like 3B? Similarly, how much enhancement could we anticipate if we transitioned to a larger LLM, like 33B?
Why not use reinforcement learning from human feedback (RLHF)? The paper suggests training a target language model on task examples. These examples are augmented with reflection tokens from a critic model offline, which results in a much lower training cost compared to RLHF. Furthermore, the reflection tokens in self-RAG make generation controllable during inference, while RLHF focuses on human preference alignment during training. However, the paper does not contain any comparative experiments related to RLHF.
Conclusion
This article begins with an intuitive example, and presents the fundamental process of self-RAG, complemented with code explanations. It also shares my insights and thoughts.
If you’re interested in RAG technologies, feel free to check out my other articles.
Lastly, if there are any errors or omissions, or if you have any questions, please feel free to discuss in the comments section.