


AI Innovations and Insights 19: Qwen 2.5 and Everything to Markdown
This article is the 19th in this insightful series. Today, we will explore two intriguing topics in AI, which are:
Qwen 2.5: Technical Evolution and Performance Optimization
E2M: Everything to Markdown
The video contains a mind map:
Qwen 2.5: Technical Evolution and Performance Optimization
Open-source code: https://github.com/QwenLM/Qwen2.5
In my previous article, I introduced Qwen2.5-Coder and DeepSeek-V3.
Recently, Qwen2.5's technical report has been released. Below, I'll provide a brief overview to help everyone quickly grasp its contents.
Main Features
Qwen2.5 is a series of large language models (LLMs) designed to meet diverse needs, with the following main features:
Better Size: Qwen2.5 expands model options with 3B, 14B, and 32B variants alongside existing sizes, optimizing for resource-limited scenarios. Qwen2.5-Turbo and Plus are Mixture-of-Experts (MoE) models that balance performance and efficiency.
Better Data: Training data expanded from 7T to 18T tokens, emphasizing knowledge, coding, and math. Pre-training is staged to allow transitions among different mixtures. Post-training includes 1M examples across SFT, DPO, and GRPO stages.
Better Use: Improved with 8K token generation (up from 2K), enhanced structured data handling, and simplified tool use. Qwen2.5-Turbo handles up to 1M token context.
Architecture and Tokenizer

The Qwen2.5 series includes both dense models and MoE models, based on a Transformer decoder architecture, incorporating Grouped Query Attention (GQA), SwiGLU activation function, Rotary Positional Embeddings (RoPE), QKV bias, and RMSNorm for stable training.
The MoE models replace the standard FFN layers with multi-expert FFN experts, utilizing a routing mechanism to dispatch tokens to top-K experts, improving performance on downstream tasks.
The tokenizer is based on byte-level byte pair encoding (BBPE), using a vocabulary of 151,643 regular tokens and expanding control tokens from 3 to 22, enhancing consistency and compatibility across models.
Pre-Training
Qwen2.5’s pre-training involves high-quality data filtering, enhanced math and code datasets, synthetic data generation, and strategic data mixture to create a balanced, information-rich dataset. The pre-training data has expanded from 7 trillion tokens in Qwen2 to 18 trillion tokens, resulting in improved model performance.
Hyperparameter optimization is guided by scaling laws, optimizing batch size, learning rate, and model size for both dense and MoE models.
Long-context pre-training includes an initial 4,096-token context phase followed by an extension to 32,768 tokens. ABF technique is used to increase the base frequency of RoPE from 10,000 to 1,000,000. YARN and Dual Chunk Attention (DCA) enhance the models' ability to process long sequences, up to 1 million tokens for Qwen2.5-Turbo.
Post-Training
Qwen2.5 introduces two key advancements in post-training:
Expanded supervised fine-tuning data coverage: Using millions of high-quality examples to improve long-sequence generation, math, coding, instruction-following, structured data, reasoning, and cross-lingual capabilities.
Two-stage reinforcement learning:
Offline RL: Develops complex skills like reasoning and factuality through carefully constructed and validated training data.
Online RL: Leverages the reward model’s ability to detect nuances in output quality, including truthfulness, helpfulness, conciseness, relevance, harmlessness and debiasing.
Commentary
In general, Qwen 2.5 demonstrates that innovation in token scaling, reinforcement learning, and MoE architectures can substantially improve both efficiency and performance.
While it shows impressive advances in model design and performance optimization, I believe it could be improved in these key areas:
Although it has enhanced its capabilities through multi-domain data expansion to 18 trillion tokens, this massive increase may introduce new bias issues. In low-resource languages and domains lacking high-quality data, the model risks losing its ability to generalize due to overexposure to repetitive template data.
The practical value and cost-benefit analysis of complex model architectures (like MoE) and long-context capabilities needs quantitative evaluation. After all, MoE architecture significantly increases training workload, requiring thorough validation of its benefits.
An interesting observation is that Qwen 2.5 shows slightly reduced performance in some general Chinese language tasks compared to Qwen 2. This decline may be due to the model’s improved math and coding abilities coming at the cost of its general language skills, suggesting that post-training adjustments can't simultaneously improve all aspects of the model's overall performance.
E2M: Everything to Markdown
Today’s second topic is E2M, a tool that converts multiple file formats into Markdown. Let's explore how it works.
I have written many articles on Document Intelligence and PDF Parsing before.
The architecture of E2M is shown in Figure 2:
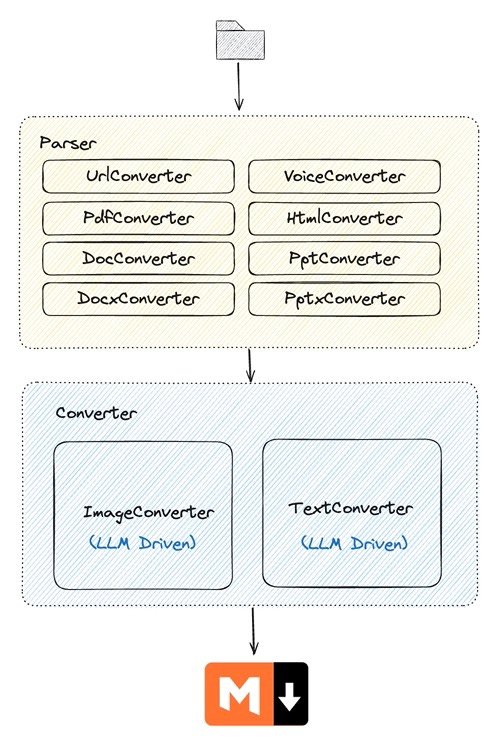
The Parser is designed to parse various file types into text or image data, while the Converter transforms that data into Markdown format.
Rather than developing its own document parsing models and pipelines, E2M leverages various open-source frameworks or closed-source services as its backend, as shown in Figure 3.

Let's focus on handling PDF files, which are the most intricate and difficult to process. Here's how to use it.
from wisup_e2m import PdfParser
pdf_path = "./test.pdf"
parser = PdfParser(engine="marker") # pdf engines: marker, unstructured, surya_layout
pdf_data = parser.parse(pdf_path)
print(pdf_data.text)The implementation is located in the class PdfParser. It supports three parsing engines:
Unstructured: Based on the unstructured framework, handles general PDF text and image extraction.
Surya Layout: Uses image processing and layout analysis for scenarios needing precise layout information.
Marker: Based on marker framework, specializes in specific text and image extraction tasks.
class PdfParser(BaseParser):
SUPPORTED_ENGINES = ["unstructured", "surya_layout", "marker"]
SUPPORTED_FILE_TYPES = ["pdf"]
...
...
def get_parsed_data(
self,
file_name: str,
start_page: int = None,
end_page: int = None,
extract_images: bool = True,
include_image_link_in_text: bool = True,
work_dir: str = "./",
image_dir: str = "./figures",
relative_path: bool = True,
layout_ignore_label_types: List[str] = [
"Page-header",
"Page-footer",
"Footnote",
],
**kwargs,
) -> E2MParsedData:
...
...
if file_name:
PdfParser._validate_input_file(file_name)
if self.config.engine == "surya_layout":
return self._parse_by_surya_layout(
file_name,
start_page,
end_page,
work_dir=work_dir,
image_dir=image_dir,
relative_path=relative_path,
proc_count=kwargs.get("proc_count", 1),
batch_size=kwargs.get("batch_size", None),
dpi=kwargs.get("dpi", 180),
ignore_label_types=layout_ignore_label_types,
)
elif self.config.engine == "marker":
return self._parse_by_marker(
file_name=file_name,
start_page=start_page,
end_page=end_page,
include_image_link_in_text=include_image_link_in_text,
work_dir=work_dir,
image_dir=image_dir,
relative_path=relative_path,
batch_multiplier=kwargs.get("batch_multiplier", 1),
)
else:
return self._parse_by_unstructured(
file_name,
start_page,
end_page,
extract_images=extract_images,
include_image_link_in_text=include_image_link_in_text,
work_dir=work_dir,
image_dir=image_dir,
relative_path=relative_path,
)
def parse(
self,
file_name: str,
start_page: int = None,
end_page: int = None,
extract_images: bool = True,
include_image_link_in_text: bool = True,
work_dir: str = "./",
image_dir: str = "./figures",
relative_path: bool = True,
layout_ignore_label_types: List[str] = [
"Page-header",
"Page-footer",
"Footnote",
],
batch_multiplier: int = 1, # for marker
**kwargs,
) -> E2MParsedData:
...
...
for k, v in locals().items():
if k in _pdf_parser_params:
kwargs[k] = v
return self.get_parsed_data(**kwargs)Based on the parsed information, the converter is then called to transform the data into Markdown format. For images, the class ImageConverter is used.
class E2MConverter:
...
...
def convert_to_md(
self,
text: Optional[str] = None,
images: Optional[List[str]] = None,
strategy: str = "default",
image_batch_size: int = 5,
conver_helpful_info: Optional[ConvertHelpfulInfo] = None,
verbose: bool = True,
**kwargs,
) -> str:
...
...
self._validate_input(text, images)
if text:
return self.text_converter.convert_to_md(
text=text, verbose=verbose, strategy=strategy, **kwargs
)
else:
return self.image_converter.convert_to_md(
images=images,
strategy=strategy,
image_batch_size=image_batch_size,
conver_helpful_info=conver_helpful_info,
verbose=verbose,
**kwargs,
)Commentary
E2M first parses the information and then relies on LLMs to convert images into Markdown.
This differs from Nougat we discussed earlier, as it uses a specialized trained small model to output Markdown directly.
Finally, if you’re interested in the series, feel free to check out my other articles.