


MonkeyOCR: 3B Model Outperforms Industry Giants in Document Parsing — AI Innovations and Insights 53

Welcome back, let’s dive into Chapter 53 of this insightful series!
Document parsing (AI Exploration Journey: PDF Parsing and Document Intelligence) is a core technology that converts unstructured, multimodal content—such as text, tables, images, and mathematical formulas—into structured, machine-readable data.
Modern document parsing isn’t just about spotting text or detecting tables. It needs to understand documents the way humans do—by capturing fine-grained details while also rebuilding the layout and semantic relationships that are truly usable for downstream tasks.
Because document parsing involves so many challenges, most solutions today fall into one of two main paradigms:
Pipeline-based approaches (Demystifying PDF Parsing 02: Pipeline-Based Method) —like MinerU (AI Innovations and Insights 29: EdgeRAG and MinerU) and Marker (Demystifying PDF Parsing 02: Pipeline-Based Method) —break down document parsing into a sequence of specialized, fine-grained sub-tasks: layout analysis, region segmentation, OCR, table and formula detection, structural reconstruction, and so on. This modular setup enables the use of best-performing algorithms for each subtask as they evolve. But there’s a catch: errors tend to snowball. As shown in Figure 1, even slight inaccuracies in formula detection can result in characters from the line above being partially cut off, which in turn leads to distorted recognition outcomes.

Figure 1: Illustration of error propagation in pipeline-based document parsing toolchains. In the middle panel, the pipeline’s detection module inaccurately segments a formula region, causing part of the formula to overlap with text from the preceding line. This leads to recognition errors in the right panel, where extraneous superscript characters are mistakenly included in the formula output. [Source]. End-to-end approaches (Demystifying PDF Parsing 03: OCR-Free Small Model-Based Method, Demystifying PDF Parsing 04: OCR-Free Large Multimodal Model-Based Method, Demystifying PDF Parsing 05: Unifying Separate Tasks into a Small Model), such as Qwen2.5-VL-7B, take a different route. Instead of splitting the task into separate stages, they process full pages—or large regions of a document—in a unified neural network. The goal is to simplify the workflow and avoid the cascading errors of modular pipelines. While this approach shows promise for more holistic understanding, it comes with a tradeoff: heavy computational cost. Qwen2.5-VL-7B runs at just 18% of MinerU’s inference speed—and its overall performance still falls short.

Overview
Open-source code: https://github.com/Yuliang-Liu/MonkeyOCR
To overcome the limitations in existing document parsing methods—and achieve a better balance between accuracy and efficiency—MonkeyOCR introduces a new approach built around a Structure–Recognition–Relation (SRR) triplet paradigm.

SRR combines the interpretability and modularity of traditional pipelines with the global optimization and simplicity of end-to-end systems.
Structure detection: MonkeyOCR begins with YOLO-based block-level structure detection, enabling precise segmentation of semantic regions like text blocks, tables, formulas, and images.
Block-level content recognition: Each region is then processed by a unified large multimodal model (LMM), allowing for end-to-end recognition across diverse content types—without the error propagation of pipelines.
Relation prediction: Finally, MonkeyOCR uses a block-level reading order prediction mechanism to map out the relationships between detected regions—rebuilding the logical and semantic flow of the document to produce clean, structured output.
Dataset
Training an effective model requires large amounts of labeled data. To meet this need, MonkeyDoc was built—a large-scale dataset for document parsing.
Figure 3 highlights how it compares with other widely used datasets.
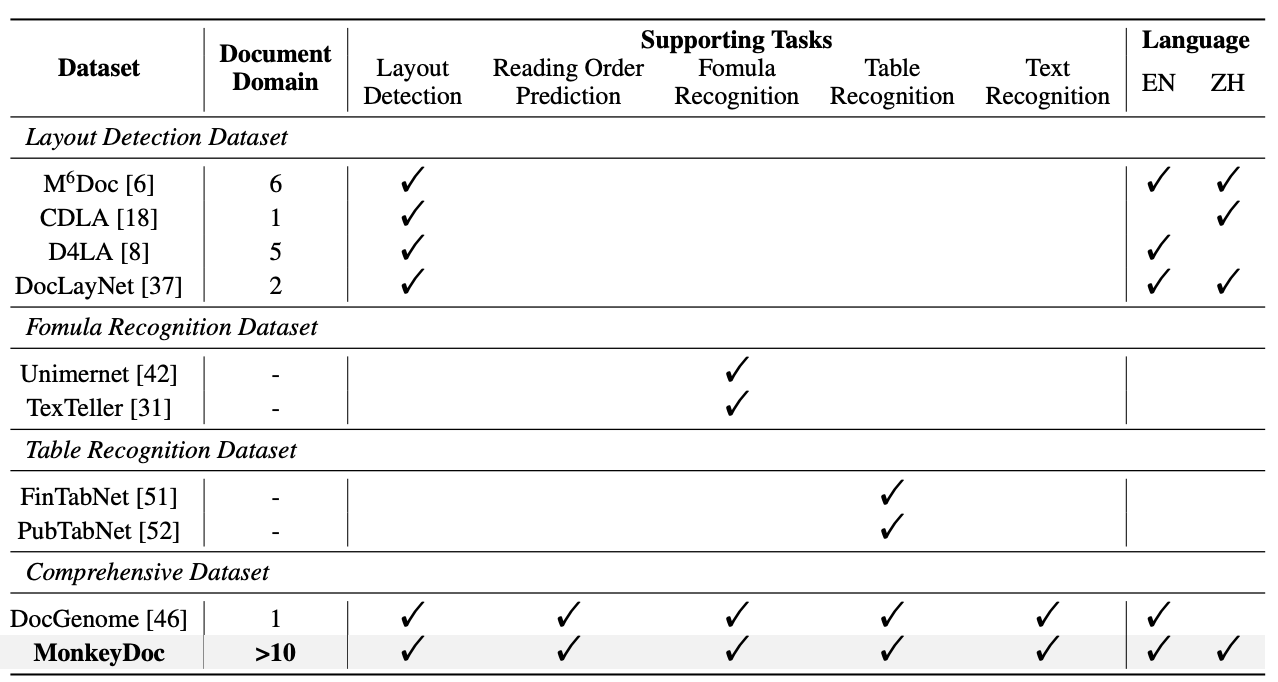
Figure 4 visualizes the MonkeyDoc dataset, which spans more than ten document types and includes specially synthesized samples for tables and formulas.

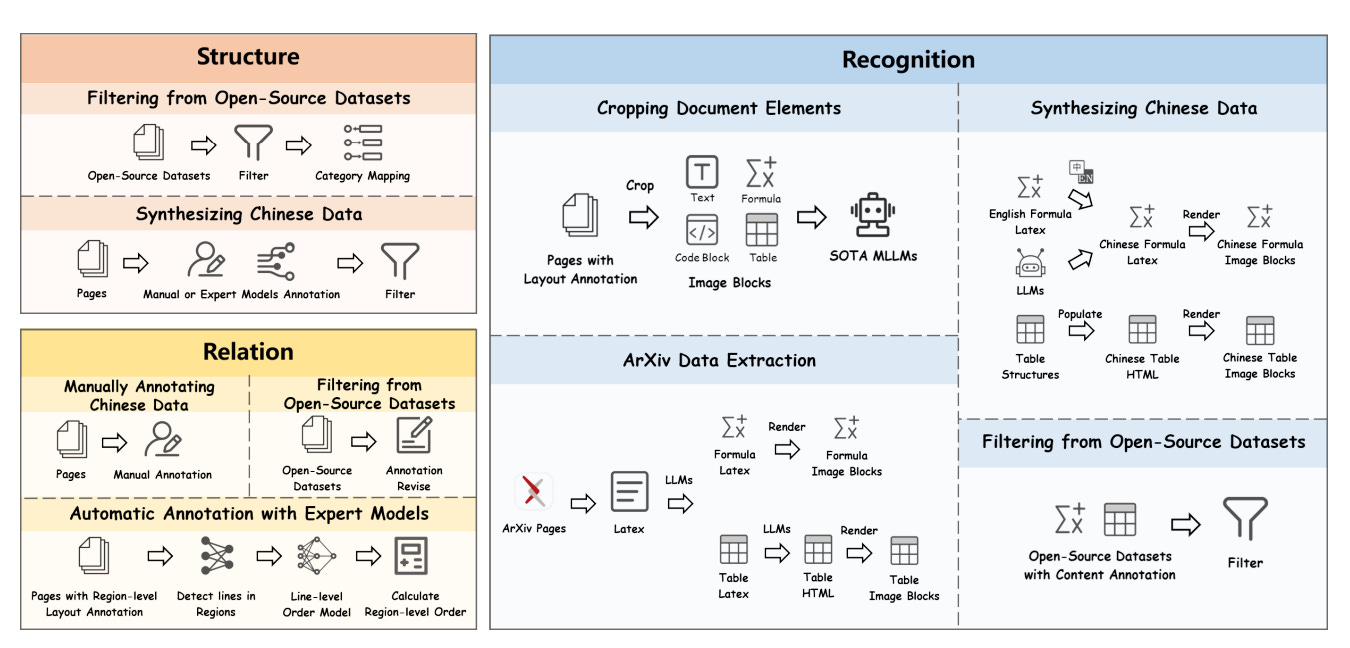
Figure 5 provides an overview of the three core stages in the MonkeyDoc data generation pipeline:
Structure Detection brings together multiple open-source datasets and enhances them with high-quality synthetic Chinese samples.
Content Recognition relies on a mix of manual labeling and automated methods, including synthetic data generation and element extraction.
Relation Prediction uses a hybrid approach, combining human annotation with model-assisted strategies to define reading order and region relationships.
Thoughts and Insights
Document parsing isn’t a new problem. The real blockers to deployment are still the same: efficiency, compatibility, and stability. MonkeyOCR’s SRR paradigm offers a fresh rethink of how we approach this problem.
It’s worth mentioning that MonkeyOCR, with just a 3B-parameter model, outperforms flagship giants like Qwen2.5-VL-72B and Gemini 2.5 Pro on English tasks—showcasing both the strength of the paradigm and the efficiency of the model.
That said, I have one concern. For relation prediction—particularly reading order—MonkeyOCR relies on a block-level sorting model. But in real-world documents with complex layouts (think multi-column formats, nested structures, mixed headers and footnotes), simple sorting may not be enough. When content flows naturally across pages, spatial cues alone often fail to capture the true logical sequence.
In my own quick tests, MonkeyOCR held up quite well. In summary, for anyone working on document parsing—whether in research or in production—MonkeyOCR is definitely worth a look.