


AI Innovations and Trends 08: Llama Series, KDD Cup’ 24 Winning Solution, and SFR-RAG

You can watch the video:
This article is the 8th in this promising series. Today, we will explore three exciting topics in AI:
Llama Series: A summary
KDD Cup’ 24 Winning Solution: Advancing RAG with Web Search, Knowledge Graphs, and Fine-Tuning
SFR-RAG: Fight Against Hallucinations
Llama Series: A summary
LLaMA is an influential open-source LLM, each version has different characteristics.
Below, I provide a table summarizing its key features.
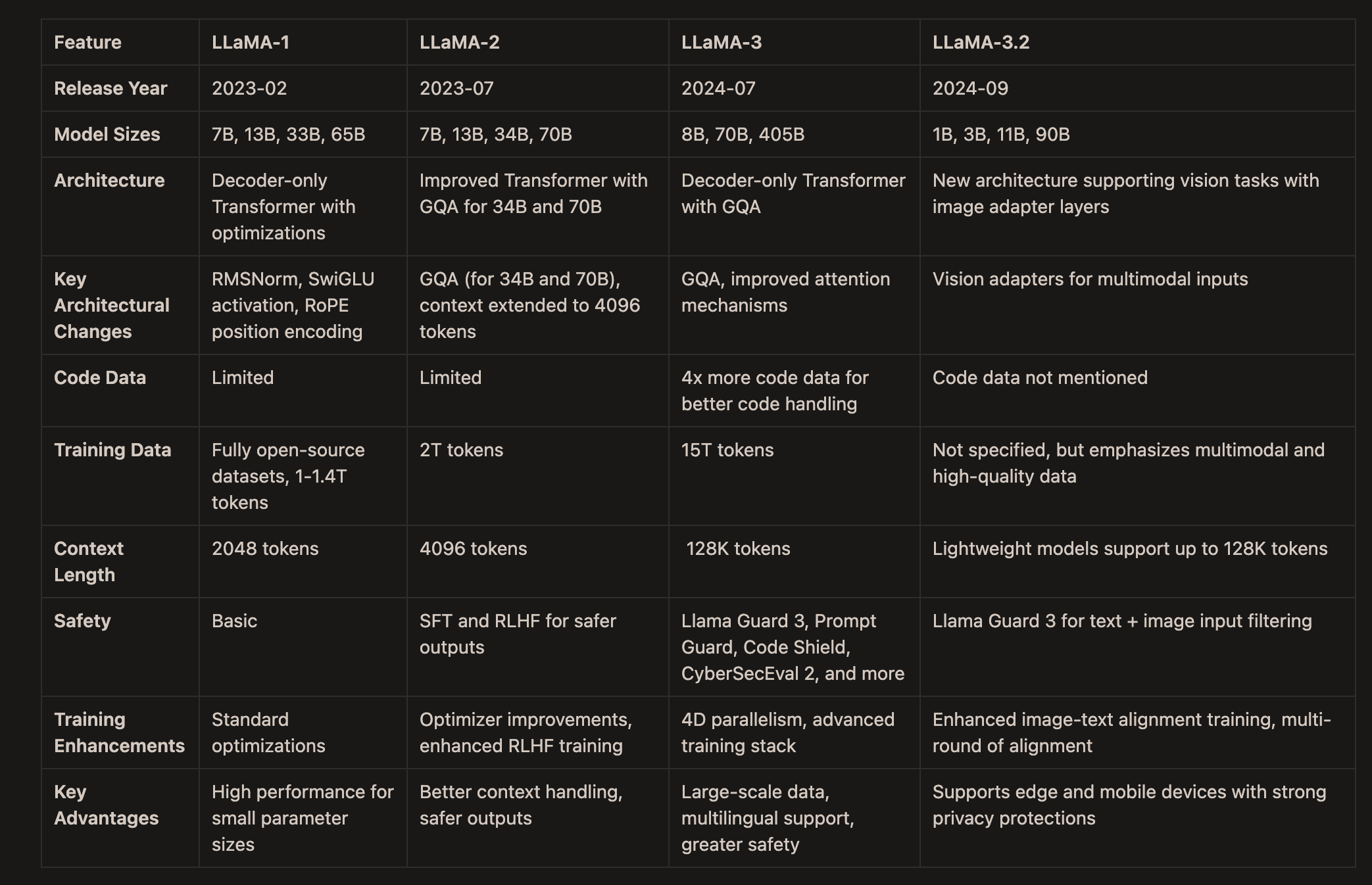
For a deeper understanding, I recommend reading the original papers, since they offer valuable insights into both LLM pre-training and fine-tuning.
Since LLaMA-3.2 has not yet published a paper, this article references this webpage.
KDD Cup’ 24 Winning Solution: Advancing RAG with Web Search, Knowledge Graphs, and Fine-Tuning
Meta has launched the Meta Comprehensive RAG Challenge (CRAG) for KDD Cup 2024, which aims to benchmark RAG systems using clear metrics and evaluation protocols to foster innovation and advance solutions in this field.
The CRAG challenge consists of three tasks:
Task #1: Web-based Retrieval Summarization. There are five web pages per question to identify and condense relevant information into accurate answers.
Task #2: Knowledge Graph and Web Augmentation. Mock APIs are provided to access structured data from mock knowledge graphs to integrate information into comprehensive answers.
Task #3: End-to-End RAG. 50 web pages and Mock APIs access per question are provided to select and integrate the most important data, reflecting real-world information retrieval challenges.
In my previous article, I introduced some of the top-ranking solutions. This post describes the winning solution to the three tasks.
Task 1

The solution for Task 1 is based on a dual-pathway framework, integrating information from web retrieval and public data pathways, with a tuned LLM providing the answers.
Web retrieval Pathway:
Text Extraction: BeautifulSoup is used to extract text from HTML pages, and the LangChain’s CharacterTextSplitter splits the text into chunks to optimize retrieval efficiency.
Parent-Child Chunk Retriever: Ranks chunks by calculating similarity between queries and chunks. Smaller child chunks are used for retrieval, while larger parent chunks maintain contextual information.
Re-ranking: Reorders chunks returned by the retriever to select the most valuable information using re-ranking models (e.g., bge-reranker-v2-m3) .
Public Data Pathway:
Enhances retrieval by preprocessing stable domain-specific facts, such as Oscar and Grammy information for movies and music, and financial stats for stocks, into a natural language format.
These preprocessed data are stored with entity-based keys and integrated with web search results to assist LLMs in answering queries accurately through in-context learning.
Domain-specific prompts guide the LLM to classify queries and match entities using varying criteria, from strict character matches to semantic similarity.
LLM Inference Module:
The Llama-3-8B-instruct model was used as the base model.
Basic query prompts (𝑝𝑏𝑎𝑠𝑖𝑐) and controlled prompts (𝑝𝑐𝑡𝑟𝑙) were designed, with the latter improving answer quality by outputting "invalid question" or "I don't know" to address questions based on incorrect premises.
Through supervised fine-tuning (SFT) with LoRA, further reductions in hallucinations were achieved in the base model, optimizing the answer style to be shorter and more direct, thus reducing incorrect judgments.
The vLLM was used to accelerate the inference process.
Task 2 and 3

Tasks #2 and #3 prioritize handling Mock API data to avoid noise from web data, with web retrieval optimized through re-ranking to save time.
Key ideas:
Regularized API: A simplified API format was designed to convert complex database queries into standardized templates, enabling efficient LLM operations.
Advanced Features: The framework supports conditional queries, sorting, and multi-hop queries, though some complex operations remain partially implemented.
Parser and Output: A custom parser was developed to convert query results into natural language, with mechanisms allowing the LLM to reject irrelevant information.
API Generation Optimization: Prompt templates, in-context learning examples, and fine-tuned models enhance the accuracy and efficiency of API generation.
Model Fine-Tuning: Using GPT-4 and LoRA techniques, the local model was fine-tuned for high-quality, fast generation while improving multi-domain adaptability.
Commentary
The system demonstrates innovative solutions in RAG scenarios, particularly in optimizing LLMs and integrating multi-source data.
However, in my opinion, it still faces certain limitations.
Generalization Capability: While the regularized API design simplifies the generation task, a more intelligent automated API generation mechanism may be needed for dynamic, cross-domain scenarios.
Operational Efficiency: Large-scale deployments require further optimization of the retrieval, re-ranking, and generation processes, particularly for handling over 50 web pages efficiently.
SFR-RAG: Fight Against Hallucinations
SFR-RAG is a novel model optimized for minimizing hallucination and faithfully generating responses based on the context retrieved.
I have detailed this method in my previous article, and now I have some new insights.
The SFR-RAG model is a 9-billion-parameter LLM instruction-tuned that minimizes hallucinations through context-grounded generation. It handles conflicting information or gaps in retrieved knowledge and offers function-calling to interact with external tools while citing sources.

The SFR-RAG model is built upon a specialized chat template and a fine-tuned process to ensure high fidelity in its responses by making full use of retrieved contextual information.
SFR-RAG Chat Template: The model enhances chat structure with new Thought and Observation roles beyond standard roles. Thought shows the model's reasoning process. Observation contains retrieved information, keeping it separate from internal logic to improve response clarity.
Fine-Tuning Process: The model is trained on real-world retrieval tasks to handle complex contexts with minimal hallucinations.
Contextual Comprehension: Extracts key information from long contexts and identifies data conflicts.
Hallucination Reduction: Fine-tuned to only generate responses grounded in retrieved context.
Agentic and Function-Calling Abilities: SFR-RAG can search proactively and call functions to access external tools and information dynamically, enabling multi-hop reasoning across contexts.
Commentary
What impresses me is its compact size compared to competitors, achieving better results with fewer parameters. SFR-RAG shows the value of “lightweight + high performance,” inspiring a shift toward task-oriented optimization in model development.
While SFR-RAG performs well on several benchmarks, it does not emphasize performance in open-domain, non-contextual tasks.
In addition, as models grow in size, there is potential for further improving reasoning and contextual comprehension in larger datasets, which would be an interesting direction for future work.
Finally, if you’re interested in the series, feel free to check out my other articles.