


AI Innovations and Insights 28: CUE-M and WebWalker
This article is the 28th in this inspiring series. Today, we will explore two reflective topics:
CUE-M: An All-Round Chef for Smarter and Safer Multimodal RAG
WebWalker: AI Expedition Team for the Web’s Hidden Realms
CUE-M: An All-Round Chef for Smarter and Safer Multimodal RAG
In previous articles, we discussed multimodal RAG. In this piece, let's explore a new development.
Vivid Description
CUE-M is like an all-round chef. When you hand him an ingredient (your question + image), he doesn’t just use a single component. Instead, he:
Analyzes the ingredient first (Intention Refinement) — figuring out if you’re making a salad or a stew.
Heads to the market for fresh supplies (Image Retrieval + Text Search) to see if there’s a better match.
Checks the recipes (API Retrieval) to find the perfect cooking method.
Looks out for allergens (Safety Filtering) to make sure the dish is safe.
Finally, he presents a dish that’s as delightful in appearance, aroma, and flavor as it is satisfying (Answer Generation).
Overview
Most current RAG systems remain unimodal, which makes it hard for them to handle queries that mix text and images.
In addition, current multimodal RAG systems often struggle to fully grasp user intent, apply diverse retrieval methods, and filter out unsuitable responses, which affects their overall performance.

CUE-M (Contextual Understanding and Enhanced Search with MLLM) is a new multimodal search framework that tackles current challenges with a multi-stage process. It enriches image context, refines user intent, generates contextual queries, integrates external APIs, and filters results based on relevance.
It uses a robust filtering pipeline that combines image, text, and multimodal classifiers, adapting dynamically to specific instances and categories as defined by organizational policies.
Key Stages

Figure 2 is a high-level architecture of CUE-M pipeline, it might look complicated at first glance. I will provide an example to help clarify.
Image and Question
A user uploads a photo of a plant and asks, "What is this plant, and how should I care for it?"
Step One: Image-Enriched Retrieval
CUE-M starts by extracting key details from the image to form an initial query:
Image Captioning:
The system uses a multimodal LLM to generate a text description of the image. For example, it might say, "This is an indoor foliage plant with narrow, vibrant green leaves, possibly from the Araceae family."Similar Image Search:
CUE-M then performs a visual similarity search. It finds similar images in its database, which suggest the plant could be "Lucky Bamboo."Image Tag-Based Search:
Finally, by combining tags from these similar images—such as "Araceae," "indoor plant," and "shade-tolerant"—CUE-M refines its search to gather more detailed information.
Step Two: Intention Refinement
CUE-M combines the user's question ("What is this plant? How should I care for it?") with the image retrieval result ("Lucky Bamboo") to fully understand the request. It then refines the query to focus on two main needs: identifying the plant and providing care instructions.
Part 1: Confirm the plant type.
Part 2: Retrieve care guidelines for Lucky Bamboo, such as watering frequency, lighting needs, and fertilization methods.
Step Three: Query Generation
Based on the refined intent, CUE-M creates structured queries to gather detailed information:
"What is the scientific name of Lucky Bamboo, and where is it commonly found?"
"What are the watering and lighting requirements for Lucky Bamboo?"
"How can I prevent the leaves of Lucky Bamboo from yellowing?"
Step Four: External API Selection
CUE-M selects the right data sources to gather extra details:
Encyclopedia API: Retrieves detailed info on Lucky Bamboo (scientific name, classification, origin).
Horticulture API: Finds care guidelines for Lucky Bamboo (suitable soil, fertilization methods).
Shopping API: Recommends growing tools for Lucky Bamboo (pots, nutrient solutions).
Step Five: Answer Generation
CUE-M combines all the retrieved results to generate the final answer.
Final Answer:
"This is a Lucky Bamboo (Dracaena sanderiana), commonly found in Southeast and Northeast Asia, and it's well-suited for indoor care.
Care Guidelines:
It needs gentle, indirect light—avoid direct sunlight.
Water every 5-6 days to keep the soil moist without overwatering.
It blooms in spring with a variety of colors and a subtle fragrance.
If the leaves turn yellow, it might be due to water quality or too much sunlight. Consider using filtered water and reducing sun exposure."
Safety Filtering
In the CUE-M process, safety filtering is applied both before and after generating the answer, creating a robust, multi-stage safety net.
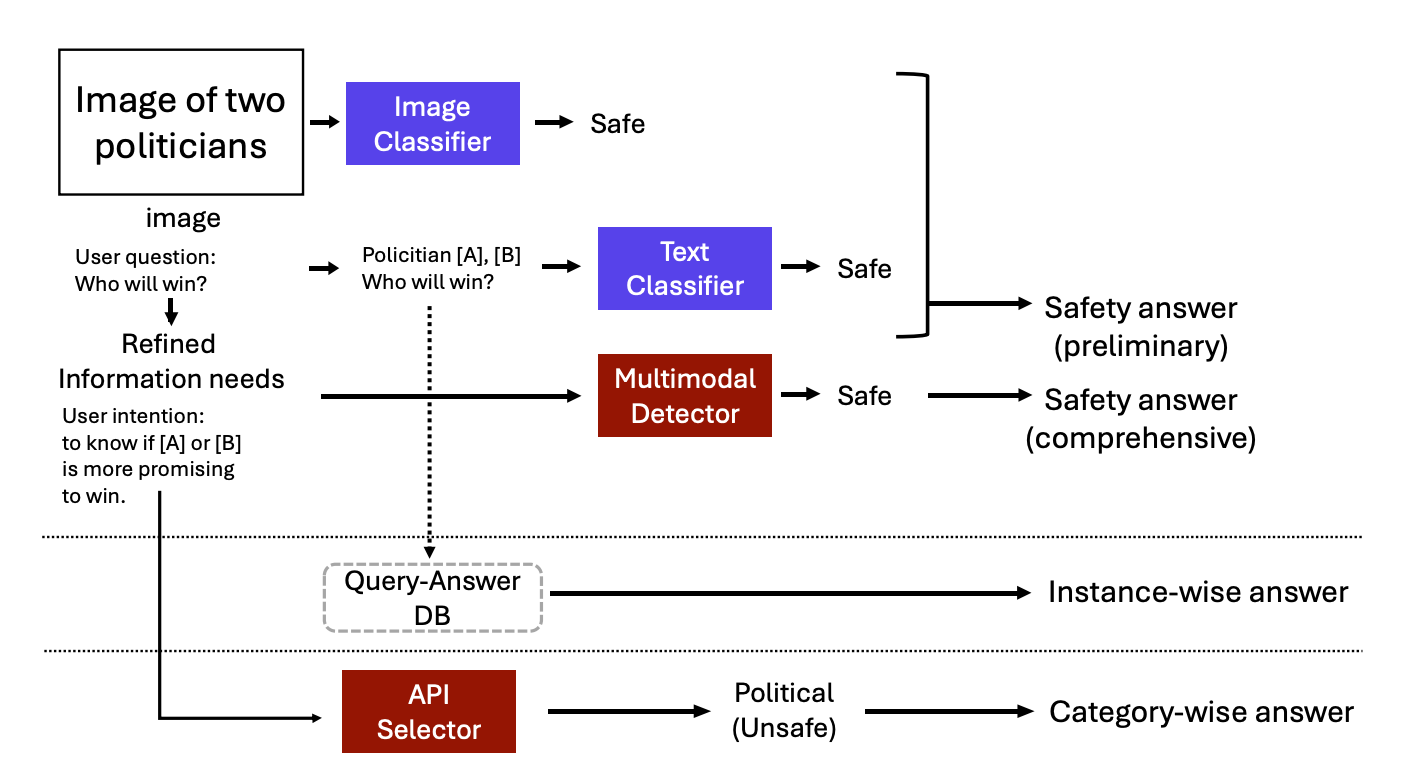
It starts with quick, lightweight text and image classifiers for preliminary filtering. For complex cases, a few-shot prompted LLM refines the intent instead of using the original query directly. Two dynamic, training-free methods are then applied:
Instance-wise filtering: Matches user queries against a database of predefined unsafe query-response pairs using text embeddings.
Category-wise filtering: Provides predefined safe responses for broader topics governed by organizational policies, like political or medical advice.
Commentary
In my previous article, I explained how typical multimodal RAG is implemented. CUE-M, in my view, builds on that by adding several new modules. It also stands out in how it tackles safety in multimodal RAG.
In addition, I have some reservations:
CUE-M mainly focuses on explicit safety filtering for content like pornography and violence but doesn't address covert adversarial attacks. For example, a malicious user could use image splicing or suggestive text to bypass the filters. Current multimodal systems are vulnerable to adversarial examples, where even minor tweaks, like subtle adversarial noise, can mislead classifiers into misidentifying, say, animal species.
Another challenge is handling ambiguous intentions. For example, if a user uploads a photo of a watch and asks, "How is this watch?" is the goal to check its price, read reviews, or find similar models? CUE-M doesn't explain how it would parse multiple intentions, which might lead to search results that don't really match what the user needs.
WebWalker: AI Expedition Team for the Web’s Hidden Realms
Open-source code: https://github.com/Alibaba-NLP/WebWalker
Vivid Description
Traditional RAG is like a horizontal search—a fishing net cast wide to grab as much related information as possible in one go.
In contrast, WebWalker works like a two-person expedition team, diving deep into a treasure trove (a website) layer by layer to uncover valuable information hidden within. The Explorer (Explorer Agent) searches for clues, while the Critic (Critic Agent) takes notes and determines when enough information has been gathered to answer the query.
Combining both approaches provides both breadth and depth, leading to a more comprehensive and effective solution for complex information retrieval tasks.
Overview
Traditional RAG methods depend on search engines for information but often only scratch the surface, making it hard to handle tasks that require digging into deeper, multi-layered content.
WebWalker is a multi-agent system designed for interacting with web environments to answer queries. As shown in Figure 4, it mimics human-like web navigation through vertical exploration. The framework consists of two main agents:
Explorer Agent, built on the ReAct framework, follows a "thought-action-observation" cycle to traverse pages via HTML buttons.
Critic Agent keeps track of information and provides answers once there's enough data.
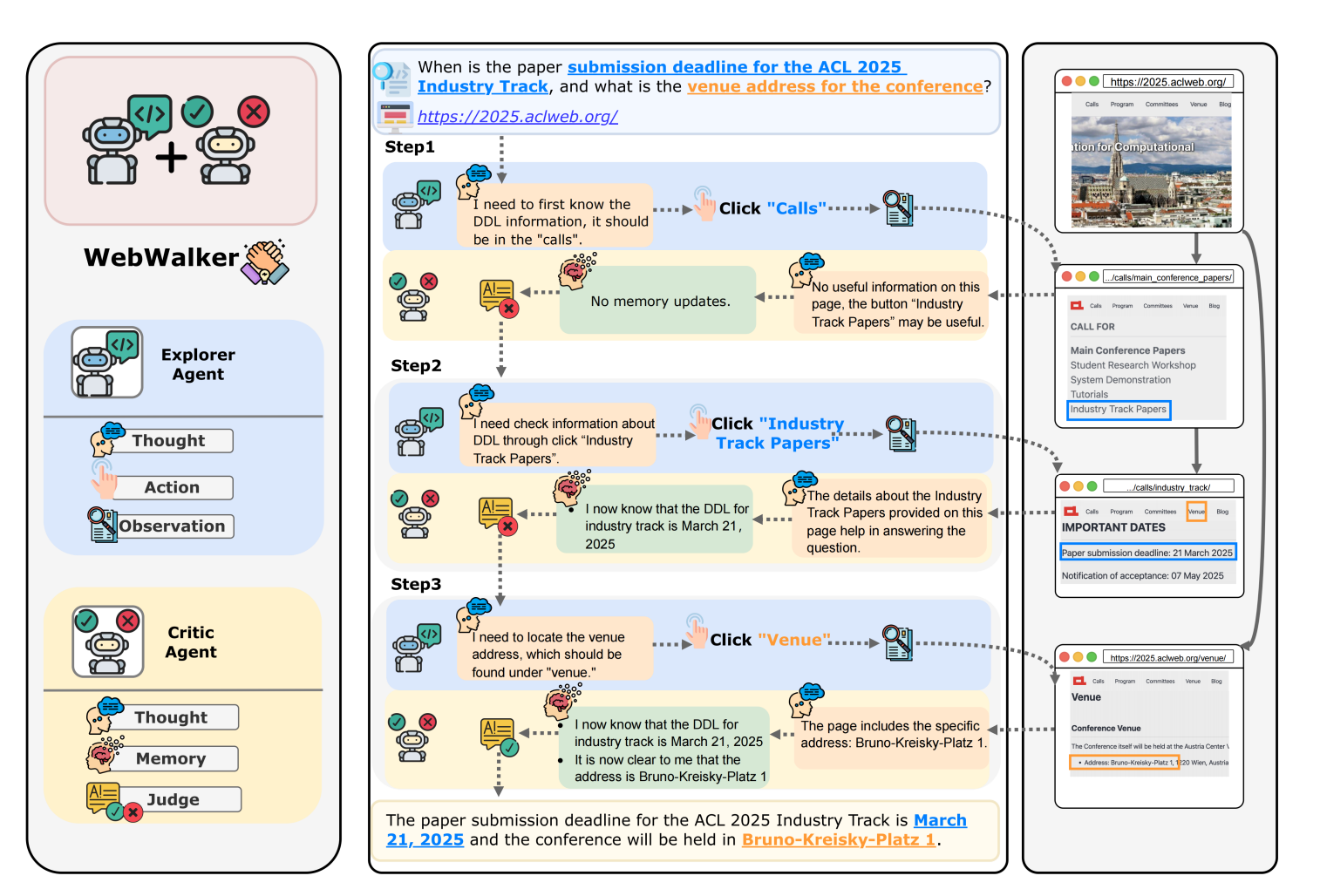
To better understand how WebWalker works, let's consider a practical example:
Query: "What is the paper submission deadline for the ACL 2025 Industry Track, and what is the venue address for the conference?"
Initial State: WebWalker starts from the ACL 2025 official website (https://2025.aclweb.org/).
Explorer Agent:
The explorer agent analyzes the current page and identifies potential links containing the answer, such as "Call for Papers" or "Venue". This process follows the Thought-Action-Observation paradigm.
Thought: The agent thinks about which action to take to find relevant information.
Action: The explorer agent clicks the "Calls" link. The action involves selecting a URL of a subpage to explore.
Observation: The agent observes the content of the "Call for Papers" page but doesn't find the specific deadline information.
Thought: The agent realizes it needs to find information specific to the Industry Track.
Action: The explorer agent clicks the "Industry Track Papers" link.
Observation: The agent finds the paper submission deadline: "21 March 2025".
Thought: The explorer agent returns to the initial page and want to visit the "Venue" link.
Action: Clicks the "Venue" link.
Observation: The agent finds the conference venue: "Bruno-Kreisky-Platz".
Critic Agent:
After each action by the explorer agent, the critic agent evaluates whether the current page contains useful information for answering the query.
The critic agent maintains a memory to accumulate relevant information from various pages.
When the critic agent determines that enough information has been collected, it generates an answer.
Answer: The critic agent synthesizes the information to generate the final answer: "The paper submission deadline for the ACL 2025 Industry Track is March 21, 2025, and the conference will be held in Bruno-Kreisky-Platz."
Commentary
Overall, while traditional RAG remains the mainstream approach for information retrieval, WebWalker’s deep-diving capability helps address its limitations in handling complex, multi-step web searches—especially when it comes to exploring specific websites in depth or integrating information from multiple pages.
That said, I have a few concerns:
Efficiency Issues: The explorer agent’s crawling approach may lead to unnecessary visits to irrelevant pages, increasing API costs. In enterprise applications, factors like webpage latency and bandwidth consumption are real concerns. Optimizing the exploration strategy to minimize wasted clicks and improve traversal efficiency is a key challenge.
Unclear Information Criteria: The critic agent determines when enough information has been gathered, but WebWalker doesn’t provide clear, quantifiable standards for making that judgment. A more transparent approach to defining sufficiency could improve reliability.
Finally, if you’re interested in the series, feel free to check out my other articles.