


AI Innovations and Insights 15: Text2SQL and Extractous

You can watch the video (which contains a mind map):
This article is the 15th in this promising series. Today, we will explore two exciting topics in AI, which are:
Text-to-SQL: A Brief Guide
Extractous: Rust-based Fast Document Parsing
Text-to-SQL: A Brief Guide
What is Text-to-SQL
Text-to-SQL is a long-standing task in NLP research and is currently a research hotspot in the LLM era. Its goal is to transform natural language questions into executable SQL queries for databases.
Figure 1 provides an overview of an LLM-based text-to-SQL system.
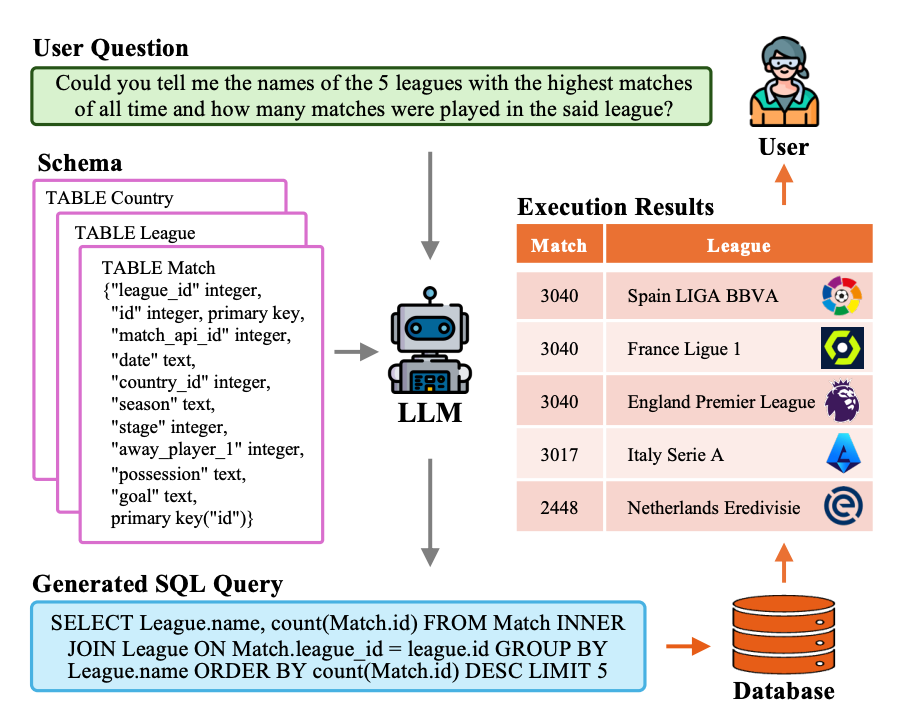
When a user asks a question about football leagues, the LLM processes both the question and the database schema as input. It then generates an SQL query, which can be executed in the database to retrieve information about "The 5 leagues with the highest matches," providing the answer to the user's question.
The Evolution of Text-to-SQL
In fact, the development of Text-to-SQL has evolved over nearly a decade—starting from rule-based methods, progressing to deep learning-based approaches, and more recently, incorporating pre-trained language models (PLMs) and large language models (LLMs).
Figure 2 shows a sketch of this evolutionary process.

What is Text-to-SQL Used For
Text2SQL simplifies database access. It allows non-technical users to directly query data using natural language without needing to know SQL syntax, lowering the technical barrier. For technical professionals, it can also improve their data query efficiency.
It is well-suited for applications in Business Intelligence (BI), intelligent customer service, and analytics platforms.
Extractous: Rust-based Fast Document Parsing
Document and PDF parsing has always been one of my main focuses, and I've introduced many methods and open source projects in my previous articles.
Today I discovered Extractous, an open-source tool written in Rust that offers a fast and efficient solution.
The demo below shows that Extractous is 25x faster than the popular unstructured-io library.

Principles
Let's take a look at its principles from a code perspective.
The usage of Extractous is shown below. OCR is configured.
use extractous::Extractor;
fn main() {
let file_path = "../test_files/documents/deu-ocr.pdf";
let extractor = Extractor::new()
.set_ocr_config(TesseractOcrConfig::new().set_language("deu")) .set_pdf_config(PdfParserConfig::new().set_ocr_strategy(PdfOcrStrategy::OCR_ONLY));
// extract file with extractor
let (content, metadata) = extractor.extract_file_to_string(file_path).unwrap();
println!("{}", content);
println!("{:?}", metadata);
}The core function is extract_file_to_string.
/// Extracts text from a file path. Returns a tuple with string that is of maximum length
/// of the extractor's `extract_string_max_length` and metadata.
pub fn extract_file_to_string(&self, file_path: &str) -> ExtractResult<(String, Metadata)> {
tika::parse_file_to_string(
file_path,
self.extract_string_max_length,
&self.pdf_config,
&self.office_config,
&self.ocr_config,
self.xml_output,
)
}The parse_file_to_string function is designed to parse the contents of a specified file into string form using the Apache Tika library via the Java Native Interface (JNI) and extract metadata from the file.
/// Parses a file to a JStringResult using the Apache Tika library.
pub fn parse_to_string(
mut env: AttachGuard,
data_source_val: JValue,
max_length: i32,
pdf_conf: &PdfParserConfig,
office_conf: &OfficeParserConfig,
ocr_conf: &TesseractOcrConfig,
as_xml: bool,
method_name: &str,
signature: &str,
) -> ExtractResult<(String, Metadata)> {
let j_pdf_conf = JPDFParserConfig::new(&mut env, pdf_conf)?;
let j_office_conf = JOfficeParserConfig::new(&mut env, office_conf)?;
let j_ocr_conf = JTesseractOcrConfig::new(&mut env, ocr_conf)?;
let call_result = jni_call_static_method(
&mut env,
"ai/yobix/TikaNativeMain",
method_name,
signature,
&[
data_source_val,
JValue::Int(max_length),
(&j_pdf_conf.internal).into(),
(&j_office_conf.internal).into(),
(&j_ocr_conf.internal).into(),
JValue::Bool(if as_xml { 1 } else { 0 }),
],
);
let call_result_obj = call_result?.l()?;
// Create and process the JStringResult
let result = JStringResult::new(&mut env, call_result_obj)?;
Ok((result.content, result.metadata))
}
/// Parses a file to a string using the Apache Tika library.
pub fn parse_file_to_string(
file_path: &str,
max_length: i32,
pdf_conf: &PdfParserConfig,
office_conf: &OfficeParserConfig,
ocr_conf: &TesseractOcrConfig,
as_xml: bool,
) -> ExtractResult<(String, Metadata)> {
let mut env = get_vm_attach_current_thread()?;
let file_path_val = jni_new_string_as_jvalue(&mut env, file_path)?;
parse_to_string(
env,
(&file_path_val).into(),
max_length,
pdf_conf,
office_conf,
ocr_conf,
as_xml,
"parseFileToString",
"(Ljava/lang/String;\
I\
Lorg/apache/tika/parser/pdf/PDFParserConfig;\
Lorg/apache/tika/parser/microsoft/OfficeParserConfig;\
Lorg/apache/tika/parser/ocr/TesseractOCRConfig;\
Z\
)Lai/yobix/StringResult;",
)
}Commentary
Apache Tika is a content analysis toolkit that can detect thousands of file types and extract their metadata and text. I hadn't paid attention to this framework before, but it seems we should focus more on non-Python projects to broaden our perspective.
While Extractous experiments demonstrate superior performance compared to unstructured, its use of JNI calls introduces context switching between Java and Rust. This switching may affect performance and may introduce extra overhead, especially in highly concurrent environments.
In addition, for broader usability, Extractous also provides a Python interface.
Finally, if you’re interested in the series, feel free to check out my other articles.