
Advanced RAG 02: Unveiling PDF Parsing
Including key points, diagrams, and code

20240215 Additional content: Read more in

20240316: This article focuses on tables: Read more in

20240505: This series focuses on providing a developer’s perspective on how to create your own PDF parsing tools. Read more in

For RAG, the extraction of information from documents is an inevitable scenario. Ensuring the effectiveness of content extraction from the source is crucial in improving the quality of the final output.
It is important not to underestimate this process. When implementing RAG, poor information extraction during the parsing process can lead to limited understanding and utilization of the information contained in PDF files.
The position of the Pasing process in RAG is shown in Figure 1:
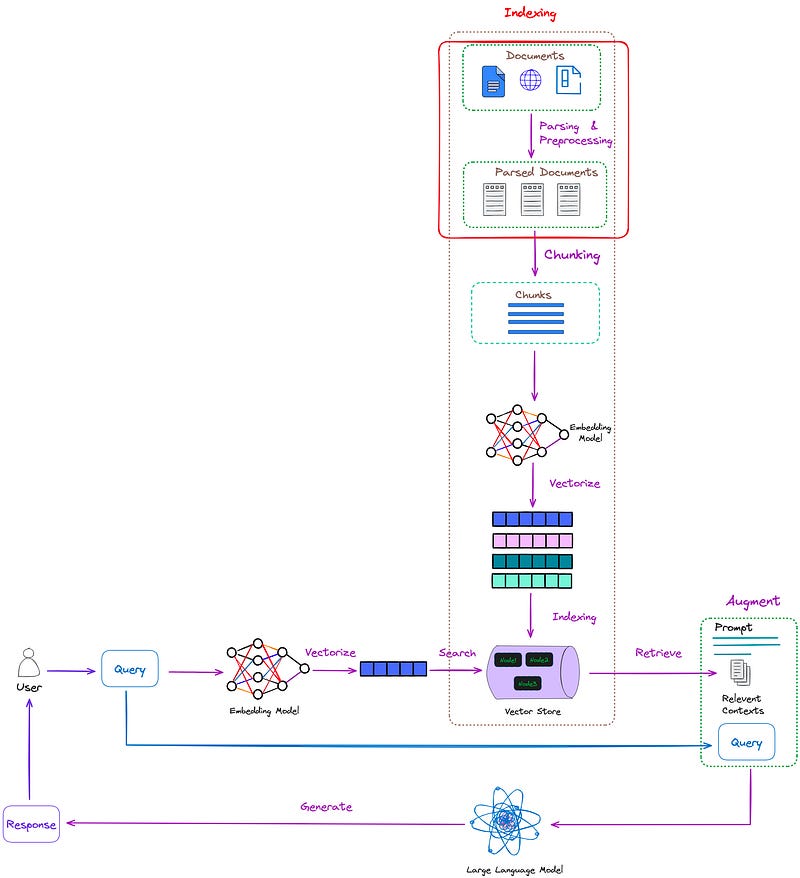
In practical work, unstructured data is much more abundant than structured data. If these massive amounts of data cannot be parsed, their tremendous value will not be realized.
In unstructured data, PDF documents account for the majority. Effectively handling PDF documents can also greatly assist in managing other types of unstructured documents.
This article primarily introduces methods for parsing PDF files. It provides algorithms and suggestions for effectively parsing PDF documents and extracting as much useful information as possible.
The Challenges of Parsing PDF
PDF documents are representative of unstructured documents, however, extracting information from PDF documents is a challenging process.
Instead of being a data format, it is more accurate to describe PDF as a collection of printing instructions. A PDF file consists of a series of instructions that instruct a PDF reader or printer on where and how to display symbols on a screen or paper. This is in contrast to file formats like HTML and docx, which use tags such as <p>, <w:p>, <table> and <w:tbl> to organize different logical structures, as shown in Figure 2:

The challenge in parsing PDF documents lies in accurately extracting the layout of the entire page and translating the content, including tables, titles, paragraphs, and images, into a textual representation of the document. The process involves dealing with inaccuracies in text extraction, image recognition, and the confusion of row-column relationships in tables.
How to parse PDF documents
In general, there are three approaches to parsing PDFs:
Rule-based approach: where the style and content of each section are determined based on the organizational characteristics of the document. However, this method is not very generalizable as there are numerous types and layouts of PDFs, making it impossible to cover them all with predefined rules.
Approach based on deep learning models: such as the popular solution that combines object detection and OCR models.
Pasing complex structures or extracting key information in PDFs based on multimodal large models.
Rule-based methods
One of the most representative tools is pypdf, which is a widely-used rule-based parser. It is a standard method in LangChain and LlamaIndex for parsing PDF files.
Below is an attempt to parse the 6th page of the “Attention Is All You Need” paper using pypdf. The original page is shown in Figure 3.

The code is as follows:
import PyPDF2
filename = "/Users/Florian/Downloads/1706.03762.pdf"
pdf_file = open(filename, 'rb')
reader = PyPDF2.PdfReader(pdf_file)
page_num = 5
page = reader.pages[page_num]
text = page.extract_text()
print('--------------------------------------------------')
print(text)
pdf_file.close()The result of the execution is (omitting the rest for brevity):
(py) Florian:~ Florian$ pip list | grep pypdf
pypdf 3.17.4
pypdfium2 4.26.0
(py) Florian:~ Florian$ python /Users/Florian/Downloads/pypdf_test.py
--------------------------------------------------
Table 1: Maximum path lengths, per-layer complexity and minimum number of sequential operations
for different layer types. nis the sequence length, dis the representation dimension, kis the kernel
size of convolutions and rthe size of the neighborhood in restricted self-attention.
Layer Type Complexity per Layer Sequential Maximum Path Length
Operations
Self-Attention O(n2·d) O(1) O(1)
Recurrent O(n·d2) O(n) O(n)
Convolutional O(k·n·d2) O(1) O(logk(n))
Self-Attention (restricted) O(r·n·d) O(1) O(n/r)
3.5 Positional Encoding
Since our model contains no recurrence and no convolution, in order for the model to make use of the
order of the sequence, we must inject some information about the relative or absolute position of the
tokens in the sequence. To this end, we add "positional encodings" to the input embeddings at the
bottoms of the encoder and decoder stacks. The positional encodings have the same dimension dmodel
as the embeddings, so that the two can be summed. There are many choices of positional encodings,
learned and fixed [9].
In this work, we use sine and cosine functions of different frequencies:
PE(pos,2i)=sin(pos/100002i/d model)
PE(pos,2i+1)=cos(pos/100002i/d model)
where posis the position and iis the dimension. That is, each dimension of the positional encoding
corresponds to a sinusoid. The wavelengths form a geometric progression from 2πto10000 ·2π. We
chose this function because we hypothesized it would allow the model to easily learn to attend by
relative positions, since for any fixed offset k,PEpos+kcan be represented as a linear function of
PEpos.
...
...
...Based on the results of PyPDF detection, it is observed that it serializes the character sequences in the PDF into a single long sequence without preserving the structural information. In other words, it treats each line of the document as a sequence separated by newline characters “\n”, which prevents accurate identification of paragraphs or tables.
This limitation is an inherent characteristic of rule-based methods.
Methods based on deep learning models.
The advantage of this method is its ability to accurately identify the layout of the entire document, including tables and paragraphs. It can even understand the structure within tables. This means that it can divide the document into well-defined, complete information units while preserving the expected meaning and structure.
However, there are also some limitations. The object detection and OCR stages can be time-consuming. Therefore, it is recommended to use a GPU or other acceleration devices, and employ multiple processes and threads for processing.
This approach involves object detection and OCR models, I have tested several representative open-source frameworks:
Unstructured: It has been integrated into langchain. The table recognition effect of the
hi_resstrategy withinfer_table_structure=Trueis good. However, thefaststrategy performs poorly because it does not use object detection models and mistakenly recognizes many images and tables.Layout-parser: If you need to recognize complex structured PDFs, it is recommended to use the largest model for higher accuracy, although it may be slightly slower. Additionally, it appears that the models of Layout-parser has not been updated in the past two years.
PP-StructureV2: Various model combinations are used for document analysis, with performance above average. The architecture is shown in Figure 4:

In addition to open-source tools, there are also paid tools like ChatDOC that utilize a layout-based recognition + OCR approach to parse PDF documents.
Next, we will explain how to parse PDFs using the open-source unstructured framework, addressing three key challenges.
Challenge 1: How to extract data from tables and images
Here, we will use unstructured framework as an example. The table data that is detected can be exported directly as HTML. The code for this is as follows:
from unstructured.partition.pdf import partition_pdf
filename = "/Users/Florian/Downloads/Attention_Is_All_You_Need.pdf"
# infer_table_structure=True automatically selects hi_res strategy
elements = partition_pdf(filename=filename, infer_table_structure=True)
tables = [el for el in elements if el.category == "Table"]
print(tables[0].text)
print('--------------------------------------------------')
print(tables[0].metadata.text_as_html)I have traced the internal process of the partition_pdf function. Figure 5 is a basic flowchart.

partition_pdf function. Image by author.The running result of the code is as follows:
Layer Type Self-Attention Recurrent Convolutional Self-Attention (restricted) Complexity per Layer O(n2 · d) O(n · d2) O(k · n · d2) O(r · n · d) Sequential Maximum Path Length Operations O(1) O(n) O(1) O(1) O(1) O(n) O(logk(n)) O(n/r)
--------------------------------------------------
<table><thead><th>Layer Type</th><th>Complexity per Layer</th><th>Sequential Operations</th><th>Maximum Path Length</th></thead><tr><td>Self-Attention</td><td>O(n? - d)</td><td>O(1)</td><td>O(1)</td></tr><tr><td>Recurrent</td><td>O(n- d?)</td><td>O(n)</td><td>O(n)</td></tr><tr><td>Convolutional</td><td>O(k-n-d?)</td><td>O(1)</td><td>O(logy(n))</td></tr><tr><td>Self-Attention (restricted)</td><td>O(r-n-d)</td><td>ol)</td><td>O(n/r)</td></tr></table>Copy the HTML tags and save them as an HTML file. Then, open it using Chrome, as shown in Figure 6:

It can be observed that the algorithm of unstructured largely restores the entire table.
Challenge 2: How to rearrange the detected blocks? Especially for double-column PDFs.
When dealing with double-column PDFs, let’s use the paper “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding” as an example. The reading order is shown by the red arrows:

After identifying the layout, the unstructured framework will divide each page into several rectangular blocks, as shown in Figure 8.

The detailed information of each rectangular block can be obtained in the following format:
[
LayoutElement(bbox=Rectangle(x1=851.1539916992188, y1=181.15073777777613, x2=1467.844970703125, y2=587.8204599999975), text='These approaches have been generalized to coarser granularities, such as sentence embed- dings (Kiros et al., 2015; Logeswaran and Lee, 2018) or paragraph embeddings (Le and Mikolov, 2014). To train sentence representations, prior work has used objectives to rank candidate next sentences (Jernite et al., 2017; Logeswaran and Lee, 2018), left-to-right generation of next sen- tence words given a representation of the previous sentence (Kiros et al., 2015), or denoising auto- encoder derived objectives (Hill et al., 2016). ', source=<Source.YOLOX: 'yolox'>, type='Text', prob=0.9519357085227966, image_path=None, parent=None),
LayoutElement(bbox=Rectangle(x1=196.5296173095703, y1=181.1507377777777, x2=815.468994140625, y2=512.548237777777), text='word based only on its context. Unlike left-to- right language model pre-training, the MLM ob- jective enables the representation to fuse the left and the right context, which allows us to pre- In addi- train a deep bidirectional Transformer. tion to the masked language model, we also use a “next sentence prediction” task that jointly pre- trains text-pair representations. The contributions of our paper are as follows: ', source=<Source.YOLOX: 'yolox'>, type='Text', prob=0.9517233967781067, image_path=None, parent=None),
LayoutElement(bbox=Rectangle(x1=200.22352600097656, y1=539.1451822222216, x2=825.0242919921875, y2=870.542682222221), text='• We demonstrate the importance of bidirectional pre-training for language representations. Un- like Radford et al. (2018), which uses unidirec- tional language models for pre-training, BERT uses masked language models to enable pre- trained deep bidirectional representations. This is also in contrast to Peters et al. (2018a), which uses a shallow concatenation of independently trained left-to-right and right-to-left LMs. ', source=<Source.YOLOX: 'yolox'>, type='List-item', prob=0.9414362907409668, image_path=None, parent=None),
LayoutElement(bbox=Rectangle(x1=851.8727416992188, y1=599.8257377777753, x2=1468.0499267578125, y2=1420.4982377777742), text='ELMo and its predecessor (Peters et al., 2017, 2018a) generalize traditional word embedding re- search along a different dimension. They extract context-sensitive features from a left-to-right and a right-to-left language model. The contextual rep- resentation of each token is the concatenation of the left-to-right and right-to-left representations. When integrating contextual word embeddings with existing task-specific architectures, ELMo advances the state of the art for several major NLP benchmarks (Peters et al., 2018a) including ques- tion answering (Rajpurkar et al., 2016), sentiment analysis (Socher et al., 2013), and named entity recognition (Tjong Kim Sang and De Meulder, 2003). Melamud et al. (2016) proposed learning contextual representations through a task to pre- dict a single word from both left and right context using LSTMs. Similar to ELMo, their model is feature-based and not deeply bidirectional. Fedus et al. (2018) shows that the cloze task can be used to improve the robustness of text generation mod- els. ', source=<Source.YOLOX: 'yolox'>, type='Text', prob=0.938507616519928, image_path=None, parent=None),
LayoutElement(bbox=Rectangle(x1=199.3734130859375, y1=900.5257377777765, x2=824.69873046875, y2=1156.648237777776), text='• We show that pre-trained representations reduce the need for many heavily-engineered task- specific architectures. BERT is the first fine- tuning based representation model that achieves state-of-the-art performance on a large suite of sentence-level and token-level tasks, outper- forming many task-specific architectures. ', source=<Source.YOLOX: 'yolox'>, type='List-item', prob=0.9461237788200378, image_path=None, parent=None),
LayoutElement(bbox=Rectangle(x1=195.5695343017578, y1=1185.526123046875, x2=815.9393920898438, y2=1330.3272705078125), text='• BERT advances the state of the art for eleven NLP tasks. The code and pre-trained mod- els are available at https://github.com/ google-research/bert. ', source=<Source.YOLOX: 'yolox'>, type='List-item', prob=0.9213815927505493, image_path=None, parent=None),
LayoutElement(bbox=Rectangle(x1=195.33956909179688, y1=1360.7886962890625, x2=447.47264000000007, y2=1397.038330078125), text='2 Related Work ', source=<Source.YOLOX: 'yolox'>, type='Section-header', prob=0.8663332462310791, image_path=None, parent=None),
LayoutElement(bbox=Rectangle(x1=197.7477264404297, y1=1419.3353271484375, x2=817.3308715820312, y2=1527.54443359375), text='There is a long history of pre-training general lan- guage representations, and we briefly review the most widely-used approaches in this section. ', source=<Source.YOLOX: 'yolox'>, type='Text', prob=0.928022563457489, image_path=None, parent=None),
LayoutElement(bbox=Rectangle(x1=851.0028686523438, y1=1468.341394166663, x2=1420.4693603515625, y2=1498.6444497222187), text='2.2 Unsupervised Fine-tuning Approaches ', source=<Source.YOLOX: 'yolox'>, type='Section-header', prob=0.8346447348594666, image_path=None, parent=None),
LayoutElement(bbox=Rectangle(x1=853.5444444444446, y1=1526.3701822222185, x2=1470.989990234375, y2=1669.5843488888852), text='As with the feature-based approaches, the first works in this direction only pre-trained word em- (Col- bedding parameters from unlabeled text lobert and Weston, 2008). ', source=<Source.YOLOX: 'yolox'>, type='Text', prob=0.9344717860221863, image_path=None, parent=None),
LayoutElement(bbox=Rectangle(x1=200.00000000000009, y1=1556.2037353515625, x2=799.1743774414062, y2=1588.031982421875), text='2.1 Unsupervised Feature-based Approaches ', source=<Source.YOLOX: 'yolox'>, type='Section-header', prob=0.8317819237709045, image_path=None, parent=None),
LayoutElement(bbox=Rectangle(x1=198.64227294921875, y1=1606.3146266666645, x2=815.2886352539062, y2=2125.895459999998), text='Learning widely applicable representations of words has been an active area of research for decades, including non-neural (Brown et al., 1992; Ando and Zhang, 2005; Blitzer et al., 2006) and neural (Mikolov et al., 2013; Pennington et al., 2014) methods. Pre-trained word embeddings are an integral part of modern NLP systems, of- fering significant improvements over embeddings learned from scratch (Turian et al., 2010). To pre- train word embedding vectors, left-to-right lan- guage modeling objectives have been used (Mnih and Hinton, 2009), as well as objectives to dis- criminate correct from incorrect words in left and right context (Mikolov et al., 2013). ', source=<Source.YOLOX: 'yolox'>, type='Text', prob=0.9450697302818298, image_path=None, parent=None),
LayoutElement(bbox=Rectangle(x1=853.4905395507812, y1=1681.5868488888855, x2=1467.8729248046875, y2=2125.8954599999965), text='More recently, sentence or document encoders which produce contextual token representations have been pre-trained from unlabeled text and fine-tuned for a supervised downstream task (Dai and Le, 2015; Howard and Ruder, 2018; Radford et al., 2018). The advantage of these approaches is that few parameters need to be learned from scratch. At least partly due to this advantage, OpenAI GPT (Radford et al., 2018) achieved pre- viously state-of-the-art results on many sentence- level tasks from the GLUE benchmark (Wang language model- Left-to-right et al., 2018a). ', source=<Source.YOLOX: 'yolox'>, type='Text', prob=0.9476840496063232, image_path=None, parent=None)
]where (x1, y1) is the coordinate of the top-left vertex, and (x2, y2) is the coordinate of the bottom-right vertex:
(x_1, y_1) --------
| |
| |
| |
---------- (x_2, y_2)At this time, you have the option to reshape the reading order of the page. Unstructured comes with a built-in sorting algorithm, but I found that the sorted result is not very satisfactory when dealing with double-column situation.
Therefore, it is necessary to design an algorithm. The simplest way is to sort by the horizontal coordinate of the top-left vertex first, and then sort by the vertical coordinate if the horizontal coordinates are the same. The pseudocode for this is as follows:
layout.sort(key=lambda z: (z.bbox.x1, z.bbox.y1, z.bbox.x2, z.bbox.y2))However, we discovered that even blocks in the same column may have variations in their horizontal coordinates. As shown in Figure 9, the purple line block’s horizontal coordinate bbox.x1 is actually more to the left. When sorted, it will be positioned before the green line block, which clearly violates the reading order.

One possible algorithm to use in this situation is as follows:
First, sort all the top-left x-coordinates
x1, we can getx1_minThen, sort all the bottom-right x-coordinates
x2, we can getx2_maxNext, determine the x-coordinate of the central line of the page as:
x1_min = min([el.bbox.x1 for el in layout])
x2_max = max([el.bbox.x2 for el in layout])
mid_line_x_coordinate = (x2_max + x1_min) / 2Next, if bbox.x1 < mid_line_x_coordinate, the block is classified as part of the left column. Otherwise, it is considered part of the right column.
Once the classification is complete, sort each block within the columns based on their y-coordinate. Finally, concatenate the right column to the right of the left column.
left_column = []
right_column = []
for el in layout:
if el.bbox.x1 < mid_line_x_coordinate:
left_column.append(el)
else:
right_column.append(el)
left_column.sort(key = lambda z: z.bbox.y1)
right_column.sort(key = lambda z: z.bbox.y1)
sorted_layout = left_column + right_columnIt is worth mentioning that this improvement is also compatible with single-column PDFs.
It is also worth mentioning that, the LayoutElement in the article is the intermediate information during debugging, we can also sort the return value for function partition_pdf, which is elements, the principle is the same.
Challenge 3: How to extract multiple-level headings
The purpose of extracting titles, including multi-level titles, is to enhance the accuracy of LLM’s answers.
For instance, if a user wants to know the main idea of section 2.1 in Figure 9, by accurately extracting the title of section 2.1, and send it to LLM along with the relevant content as contexts, the accuracy of final answers will significantly increase.
The algorithm still relies on the layout blocks shown in Figure 9. We can extract blocks with type=’Section-header’ and calculate the height difference (bbox.y2 — bbox.y1). The block with the largest height difference corresponds to the first-level title, followed by the second-level title, and then the third-level title.
Pasing complex structures in PDFs based on multimodal large model
After the explosion of multimodal models, it is also possible to use multimodal models to parse tables. There are several options for this:
Retrieving relevant images (PDF pages) and sending them to GPT4-V to respond to queries.
Regarding every PDF page as an image, let GPT4-V do the image reasoning for each page. Build Text Vector Store index for the image reasonings. Query the answer against the Image Reasoning Vectore Store.
Using Table Transformer to crop the table information from the retrieved images and then sending these cropped images to GPT4-V for query responses.
Applying OCR on cropped table images and send the data to GPT4/ GPT-3.5 to answer the query.
After conducting tests, it was determined that the third method is the most effective.
In addition, we can use multimodal models to extract or summarize key information from images (PDF files can be easily converted to images), as shown in Figure 10.
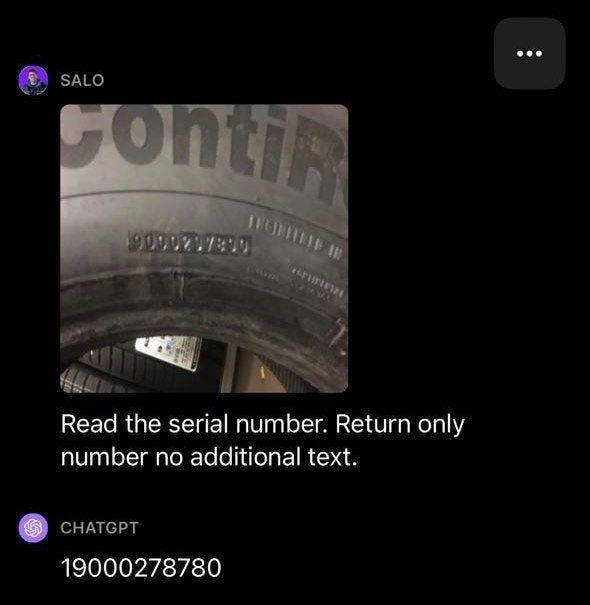
Conclusion
In general, unstructured documents offer a high degree of flexibility and require various parsing techniques. However, there is currently no consensus on the optimal method to use.
In this case, it is recommended to choose a method that best suits your project’s needs. It is advisable to apply specific treatments according to different types of PDFs. For example, papers, books, and financial statements may have unique designs based on their characteristics.
Nevertheless, if circumstances allow, it is still advisable to opt for deep learning-based or multimodal-based methods. These methods can effectively segment documents into well-defined and complete information units, thus maximizing the preservation of the intended meaning and structure of the document.
Additionally, if you’re interested in RAG , feel free to check out my other articles.
Lastly, if you have any questions, feel free to discuss them in the comments section.