


AI Innovations and Insights 13: Semantic Chunking and Late Chunking
You can watch the video:
This article is the 13th in this promising series. Today, we will explore two new discoveries about chunking, which are:
Is Semantic Chunking Worth the Computational Cost
Late Chunking: A Smarter Way to Preserve Context
Is Semantic Chunking Worth the Computational Cost
I have written many articles about chunking before. But a new study investigated whether semantic chunking is actually unnecessary. Let’s look at what’s going on.

As shown in Figure 1, three types of chunking strategies were tested in "Is Semantic Chunking Worth the Computational Cost?"
(a) Fixed-size Chunker: Sequentially splits a document into fixed-size chunks with optional overlapping sentences for contextual continuity.
(b) Breakpoint-based Semantic Chunker: Inserts breakpoints where semantic distance between consecutive sentences exceeds a threshold, capturing topic changes but prone to local greediness.
(c) Clustering-based Semantic Chunker: Groups sentences semantically using clustering algorithms with a combined positional and semantic distance measure for global coherence.
Three experiments were conducted to evaluate the quality of each strategy. Let's get straight to the findings:
Semantic chunking showing occasional improvements on datasets with high topic diversity. These improvements were highly context-dependent and did not consistently justify the additional computational cost.
Fixed-size chunking often performed better on non-synthetic datasets closer to real-world documents.
Fixed-size chunking is more efficient and reliable for practical RAG applications.
The impact of chunking often overshadowed by factors like embedding quality.
Commentary
The experimental results of this study are somewhat unexpected.
It indicates that the usefulness of semantic chunking is highly dependent on the task. Moreover, the high computational demands of semantic chunking make it less viable for resource-limited scenarios. It might be more practical to use fixed-size chunking or simpler methods in such cases.
From my perspective, looking ahead, it would be worthwhile to develop methods that can dynamically adjust chunk granularity to better match the context and distribution of topics.
Additionally, there is a clear need to improve the datasets used in these experiments. Synthetic data often fails to capture the complexity of real-world scenarios. Future work should focus on using more representative data that include longer documents and a wider variety of queries. Investigating specialized fields such as medical or legal texts could also uncover further advantages of semantic chunking.
Late Chunking: A Smarter Way to Preserve Context
The previous sections of this article discussed whether semantic chunking is necessary. Now, let's look at the timing of chunking.
Traditional chunking splits documents before embedding, losing context between chunks. This results in embeddings that miss key meaning across multiple chunks. For example, in a text about Berlin, pronouns like "Its" and "The city" lose their connection to "Berlin" when chunked separately, leading to poor embeddings.

Late chunking is a mitigation to this problem. It delays the chunking process until after the embedding model has processed the entire text, preserving the context across chunks and resulting in higher-quality embeddings.
I have detailed this method, and now I have some new insights.
Solution
Figure 3 compares naive chunking versus late chunking. The key difference lies in the order of operations when processing long texts for embedding.
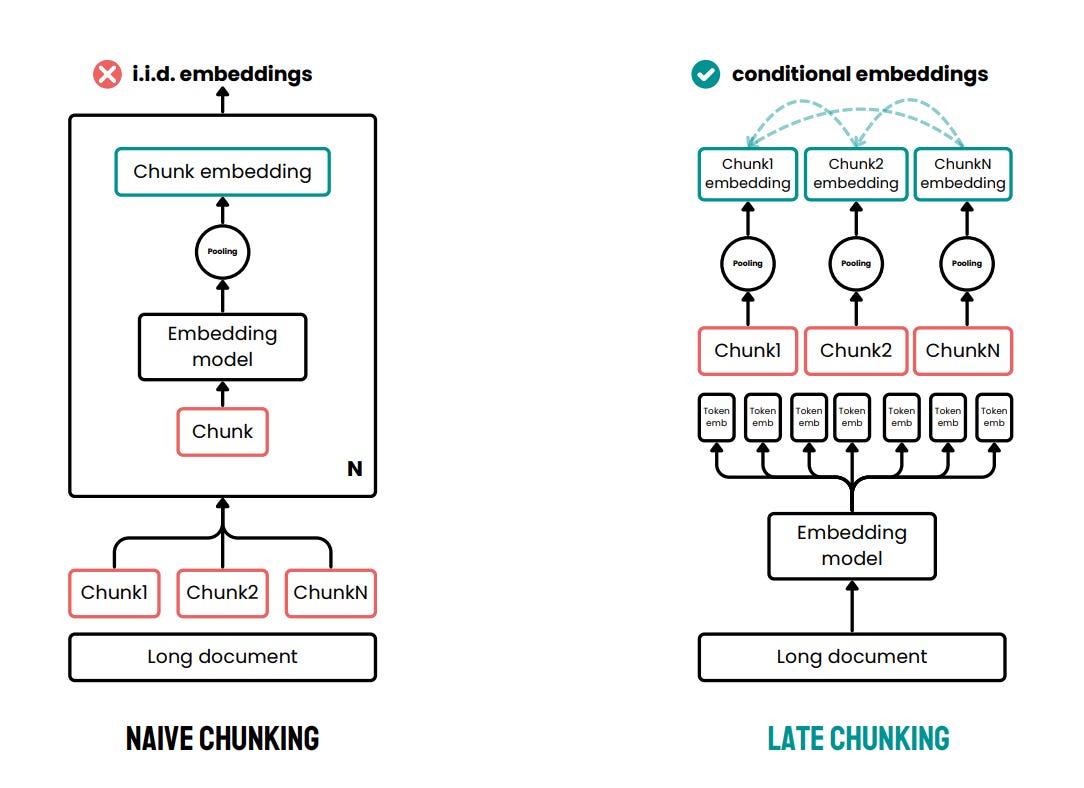
Naive chunking splits documents before embedding, creating isolated chunk representations. Late chunking processes the full document first, preserving context across chunks for better embeddings.
The process of late chunking involves several steps:
Tokenization: The entire document is tokenized into individual tokens, and their corresponding character lengths are recorded.
Embedding Generation: The embedding model processes the full document and generates token-level embeddings for each token.
Chunk Positioning: Iterates through the token embeddings, calculating the cumulative character length to determine where each chunk starts and ends.
Mean Pooling: Once chunk boundaries are established, the token embeddings for each chunk are pooled using mean pooling to generate a single embedding for each chunk.
Output: The final output is a set of chunk embeddings, each capturing both the chunk-specific information and the broader context of the full document.
A variation called "long late chunking" is introduced for documents that exceed the model's token limit. This method uses overlapping tokens from adjacent "macro chunks" to maintain context across larger portions of text.
Commentary
Late chunking is a relatively simple trick but shows strong performance. It impressed me that preserving context in RAG is very critical.
In my view, late chunking requires a long-context model as a prerequisite, which comes at a considerable cost. Further improvements may be necessary to handle large-scale applications more effectively.
In the future, I envision enhancements like dynamic chunking strategies that adapt to the semantic density of the text.
Finally, if you’re interested in the series, feel free to check out my other articles.