
Late Chunking: A Smarter Way to Preserve Context

Today we'll look at an improvement in chunking, a relatively simple trick.
Traditional chunking methods break documents into smaller text chunks before embedding, which can lead to a loss of contextual information between chunks. This "over-compression" results in embeddings that fail to capture the full meaning of the text, especially when critical information is spread across multiple chunks.
As shown in Figure 1, if a document contains the sentence "Berlin is the capital and largest city of Germany, both by area and by population," the "Its" and "The city" in the following sentences will lose context when chunked separately. Because embedding models struggle to relate "It" and "The city" to "Berlin," leading to inaccurate or suboptimal embeddings.

Late chunking is a mitigation to this problem. This method delays the chunking process until after the embedding model has processed the entire text, preserving the context across chunks and resulting in higher-quality embeddings.
Overview
Figure 2 provides a visual comparison between naive chunking and late chunking strategies. The key difference lies in the order of operations when processing long texts for embedding.
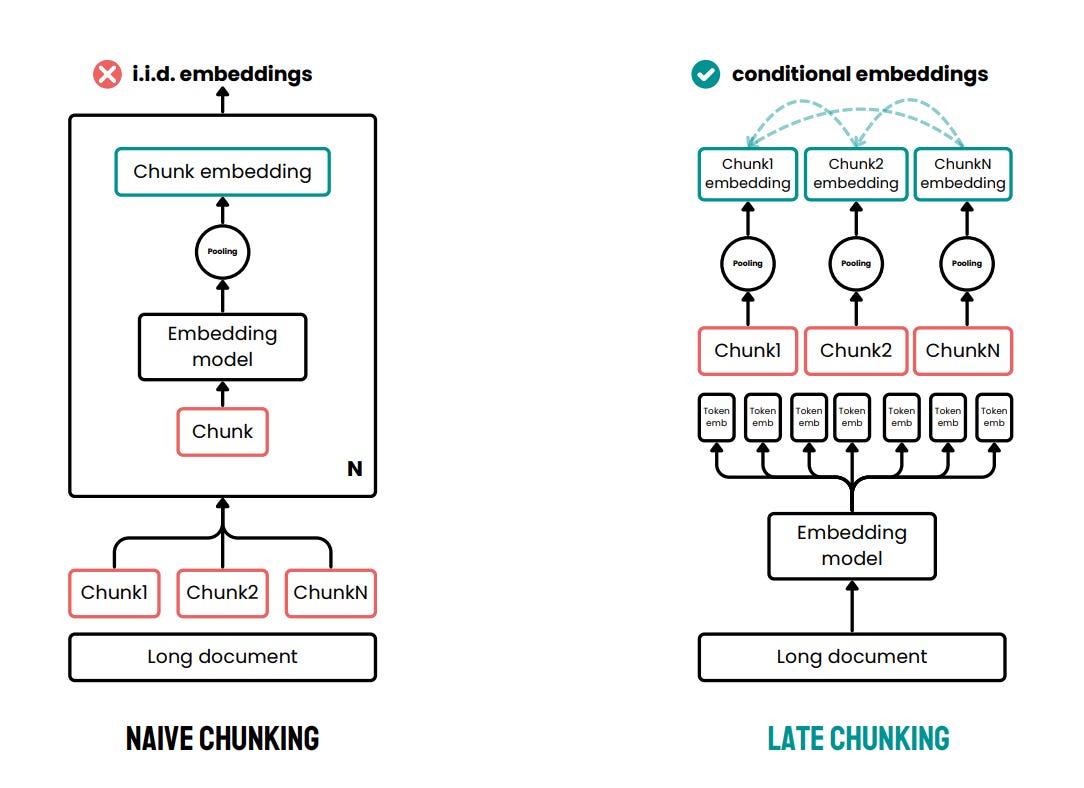
In naive chunking, the document is split into chunks before embedding, leading to independent, context-limited embeddings.
In late chunking, the entire document is processed first, allowing chunk embeddings to retain context from the whole text, resulting in richer and more accurate representations.
Detailed Process
The process of late chunking involves several steps:
Tokenization: The entire document is tokenized into individual tokens, and their corresponding character lengths are recorded.
Embedding Generation: The embedding model processes the full document and generates token-level embeddings for each token.
Chunk Positioning: Iterates through the token embeddings, calculating the cumulative character length to determine where each chunk starts and ends.
Mean Pooling: Once chunk boundaries are established, the token embeddings for each chunk are pooled using mean pooling to generate a single embedding for each chunk.
Output: The final output is a set of chunk embeddings, each capturing both the chunk-specific information and the broader context of the full document.
By late chunking, each chunk embedding retains information from the entire document, improving the semantic relevance of the embeddings.
A variation called "long late chunking" is introduced for documents that exceed the model's token limit. This method uses overlapping tokens from adjacent chunks to maintain context across larger portions of text.
Conclusion and Insights
This article presented the innovative late chunking technique, which improves the contextual integrity of chunk embeddings by postponing chunking until after the entire text is processed by an embedding model.
In my view, late chunking requires a long-context model as a prerequisite, which comes at a considerable cost. Further improvements may be necessary to handle large-scale applications more effectively.
In the future, I envision enhancements like dynamic chunking strategies that adapt to the semantic density of the text.