

Welcome to the 38th installment of this elegant series.
Imagine this: when the model that creates the data and the model that judges it come from the same "family," the LLM acting as the judge might quietly give one of their own a higher score.
It’s like having a football or basketball referee who's related to one of the teams — how could the match possibly be fair?
"Preference Leakage: A Contamination Problem in LLM-as-a-Judge" pulls back the curtain on this hidden problem in the world of AI evaluations — preference leakage.
Overview
On the left side of Figure 1, we see two issues:
Traditional data leakage happens when there’s overlap between the training corpus and the evaluation set, which can compromise the fairness of a model’s evaluation.
Preference leakage, however, is a different kind of contamination. It occurs when the LLM used to generate synthetic data (the "data generator") is somehow linked to the LLM used for evaluation (the "judge"). The hidden connection can cause the judging model to develop a systematic bias — subtly favoring models it shares ties with.
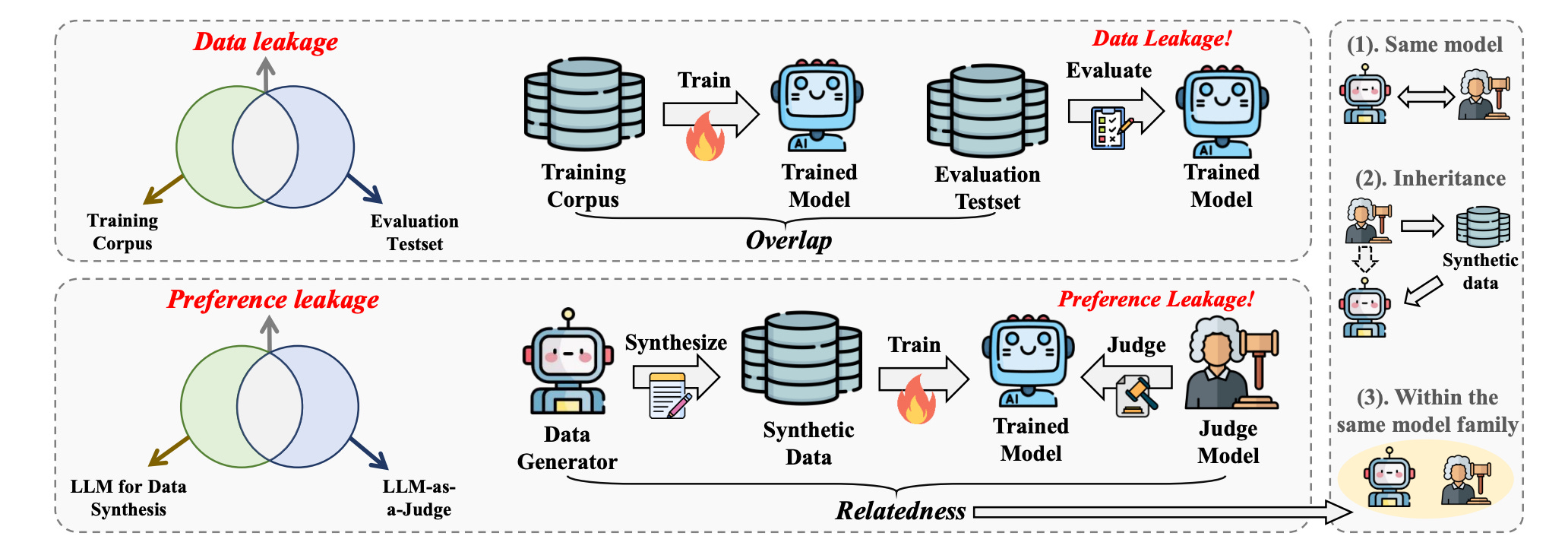
On the right side of Figure 1, three common types of connections between the data generator LLM and the judging LLM are shown:
Same model: The data generator and the evaluator are literally the same model.
Inheritance: One model is trained on synthetic data produced by another model.
Same model family: The data generator and the evaluator belong to the same family of models — for example, different versions within the GPT or Gemini families.
Evaluation
To measure preference leakage, a new metric called the Preference Leakage Score (PLS) is introduced.

PLS is calculated based on the win rates (WR) that the judging model assigns to different student models. So, what is Win-Rate, Exactly?
Win-Rate measures how often one model wins in head-to-head comparisons.
Here’s how it works: for each question, two models — say, Model A and Model B — generate their own answers. Then a judge model (an LLM acting as the evaluator) compares the two responses and picks the one it thinks is better.
After running this comparison across a large set of questions, Model A’s Win-Rate is simply calculated as:
Win-Rate (Model A) = (Number of wins by Model A) / (Total number of comparisons)
Rather than directly measuring the absolute quality of the responses, PLS captures the judging LLM’s systematic bias toward models it’s connected to. A higher PLS indicates a stronger bias caused by preference leakage.
To back up the claims of bias among LLM judges, a comprehensive set of experiments was conducted. And there were some interesting findings.
Caught in the Act: LLMs Playing Favorites


Figures 2 and 3 drive home the central point about preference leakage: judging LLMs consistently favor student models that share a training lineage or architectural similarities with themselves — and this trend holds across different datasets.
Take GPT-4o, for example. It gives Mistral-GPT4o a much higher win rate compared to student models from Gemini or LLaMA. The bias isn’t subtle — it’s loud and clear.
Tighter Ties, Bigger Bias
It means the stronger the connection between models, the worse the preference leakage gets.

Figure 4 breaks it down clearly: when the data generator and the judge are either the same model or have a direct inheritance relationship, the preference leakage score is noticeably higher. Within the same model family, the bias still exists but is significantly weaker, especially between different series where it becomes almost negligible.
LLM Judges Struggle to Recognize Their Own Students
As shown in Figure 5, their ability to tell apart their own students’ outputs hovers around random chance.
It suggests that preference leakage isn’t happening because the judges consciously "recognize" familiar work — it's more about subtle influences in style or preference quietly skewing the scores.

Thoughts and Insights
First, let me share a concern.
While the PLS score does a good job of quantifying how much preference leakage exists between two student models — especially when they're trained by the same or related data generators under a specific judge — I'm not sure it fully captures all forms of leakage across different scenarios.
The metric is designed around pairwise win-rate comparisons, but what happens in more complex evaluation setups, like multi-model comparisons or absolute scoring for a single model?
In other words, it doesn't really dive into the theoretical limits of PLS, or whether it remains reliable across different evaluation frameworks. That feels like an important gap worth exploring.
Now, looking ahead.
Preference leakage is an incredibly important but largely hidden issue.
In my view, the real challenge isn’t just spotting leakage. It’s building a system that stays clean, a system immune to contamination.
That’s the next battleground the AI industry has no choice but to face. In the end, whoever controls a fair and unbiased evaluation system might just end up steering the future of AI itself.