
What Really Causes Hallucinations in LLMs? — AI Innovations and Insights 72

People have been asking why LLMs hallucinate for years. In this piece, we look at how OpenAI’s latest research approaches this question.
Language models have a strange habit: they’ll confidently make things up — even when they have no idea what they’re talking about. These kinds of false but plausible-sounding responses are often called hallucinations. And while today’s models have gotten better, this issue still lingers — though it’s worth noting that it’s quite different from how humans experience hallucinations in the real world.
Here’s a simple example. When asked an open-source model DeepSeek-V3 (600 B parameters, 11 May 2025):
What is Adam Tauman Kalai’s birthday? If you know, just respond with DD-MM.
On three separate attempts, it outputed three different (and wrong) answers: “03-07”, “15-06”, and “01-01”. None of them are correct, even though a response was requested only if known. (The real birthday is in autumn, for what it’s worth.)
And this is just a small taste. Figure 1 shows more complex — and arguably more concerning — hallucinations.

So what’s really behind LLM hallucinations?
For the first time, OpenAI’s latest research lays it out clearly: hallucinations happen because models get rewarded for guessing — even when they’re not sure — instead of saying “I don’t know.”
The Seeds of Hallucination Are Planted During Pretraining
Modern language models don’t just start hallucinating out of nowhere. The problem begins right at the pretraining stage — baked deep into how we teach these models to “guess” words based on statistics, not truth.
Let’s break this down.
Statistical Inevitability

If you reframe text generation as a binary classification problem — “Is this a valid continuation?” — then hallucinations become unavoidable.
Even the best classifiers make mistakes. And every time the model has to pick a next word, it's essentially running that binary check.
In other words, if your classifier makes errors, your generator will too. Simple as that.
Data Scarcity
When the training data only contains a fact once — like a rare, niche piece of knowledge — the model has no chance of memorizing it correctly.
These one-off facts, often called singletons, are especially vulnerable to distortion or fabrication in generation.
In other words, the minimum hallucination rate is at least as high as the proportion of singletons in the data.
Model Limitations
Sometimes, the model architecture just isn’t capable of learning certain patterns — no matter how clean the data is.
If the model can’t even tell that some trigrams (like letter sequences) are impossible, it’s hopeless to expect factual consistency.
In other words, when a model class can’t express the right rules, hallucinations become inevitable — and frequent.
Post-training Fails to Suppress Hallucination and Instead Reinforces It
While pre-training quietly plants the seeds of hallucination, post-training tends to water them — especially when reward signals are misaligned with uncertainty.
In fact, when researchers ran a meta-evaluation of 10 major LLM benchmarks (see Table 2), they found something striking: every single one penalizes uncertainty.
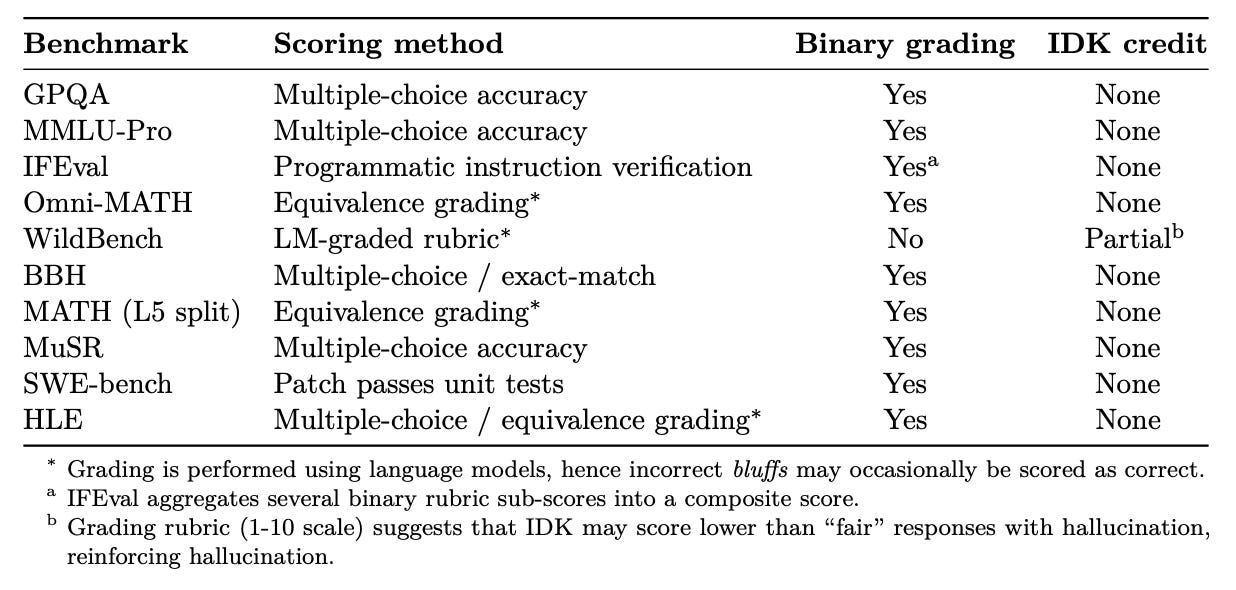
How Each Training Phase Contributes
Pretraining: Even if the data is 100% accurate, the objective (density estimation) forces the model to make confident guesses. The teacher only shows you correct answers, but on the final test, you still have to fill in the blanks — even the ones you never learned.
Post-training (e.g. RLHF): Binary scoring — 1 for correct, 0 for wrong — punishes models for “saying nothing.” It’s like a multiple-choice test where guessing is better than leaving it blank, because blanks get zero points.
How to Improve
Instead of creating yet another benchmark for hallucination, it proposes something smarter — change how we evaluate models in the first place. The idea is to reshape the incentives baked into current benchmarks, so models are rewarded for being accurate, not just confident.
Here’s the approach:
1. Score Based on Confidence Threshold t
It proposes a simple scoring rule:
Correct answer → +1 point
Wrong answer → penalty of
t / (1 - t)Saying “I don’t know” → 0 points
Under this setup, a model should only answer if it’s confident above the threshold t. Otherwise, it's better off saying “IDK.” In other words, guessing becomes suboptimal — exactly what we want.
2. Make the Threshold Explicit
Instead of hiding the penalty in the scoring logic, the proposed method makes the confidence threshold t explicit in the instructions. This makes evaluations transparent, reproducible, and fair, especially across tasks where different levels of uncertainty are acceptable.
3. Integrate This Scoring into Existing Benchmarks
Rather than designing a whole new “hallucination benchmark,” it suggests embedding this scoring logic directly into existing ones — like SWE-bench.
This subtly shifts the landscape: current binary scoring schemes (right = 1, wrong = 0) reward confident guessing. The new setup flips that incentive on its head.
4. Use Behavioral Calibration as an Evaluation Metric
To audit how well a model follows the rules, it proposes behavioral calibration:
Does the model actually answer only when its confidence ≥ t, and otherwise say “IDK”?
You can evaluate this by measuring accuracy and error rates at different thresholds.
5. Provide Concrete, Usable Thresholds
It even gives practical examples:
t = 0.5→ guessing penalty = 1t = 0.75→ penalty = 3t = 0.9→ penalty = 9
The higher the risk in a real-world setting, the higher the threshold you’d want. It’s a simple but powerful way to tune the system.
Bottom Line
The core idea is elegant: make “guessing when unsure” an actively worse strategy.
And in doing so, finally give models a reason to say “I don’t know” — not just as a novelty, but as a rational choice.
Thoughts
The question of why LLMs hallucinate has been floating around for years. This study finally brings a crisp, statistical lens to the problem — reframing hallucination not as a mysterious glitch, but as the inevitable result of two forces: binary classification errors and evaluation incentives that reward guessing.
What’s elegant is how they tackle this: by introducing an explicit confidence threshold t, and penalizing incorrect answers using a simple formula — t / (1 - t). Suddenly, “don’t guess unless you’re sure” becomes the optimal strategy in a mathematical sense. It’s a clean and powerful correction to the dominant 0/1 scoring approach.
One suggestion I’d add — and I believe this will matter more as models get closer to deployment — is to standardize around a metric like coverage@target precision t. In other words, how many questions can your model answer correctly without dropping below a precision threshold?
To make this practical and transparent, we should publish Pareto curves across different values of t, so that models are encouraged to compete on how much ground they can safely cover — not just how much they’re willing to guess.
Of course, once confidence thresholds are baked into the rules, models might start “gaming” them — either by inflating their confidence to cross the bar, or by optimizing specifically for the scoring function rather than real-world usefulness.
We also have to watch out for evaluator bias. Many current benchmarks use LLMs themselves to grade outputs, and these auto-graders often let mistakes slip through as correct. That means we’re rewarding hallucinations — just dressed up more nicely.
To avoid this, any new scoring method needs to be paired with:
Independent calibration audits (e.g., does the model’s confidence actually reflect reality?)
Distribution shift stress tests (does the behavior hold up outside the benchmark sandbox?)
The goal isn’t just to reduce hallucinations on paper, but to make sure models are truly more trustworthy in the wild — not just putting on a better show for the test.
References: Why Language Models Hallucinate.