
Unveiling LLM-Enhanced Search Technologies

In the internet age, the explosion of information has created a growing need for efficient content retrieval.
Search engines like Google, Bing, and DuckDuckGo build on text-based keyword search to deeply analyze webpage links and assess their relevance.

In the past two years, the integration of LLMs, RAG, and Agent technologies has brought search engines into a new era. The next generation of search engines emphasizes user experience, better understands semantic context, and offers advanced features such as multi-turn conversational Q&A, personalized recommendations, and multimodal and cross-language retrieval. This shift allows search engines to provide direct, concise conversational answers rather than merely presenting a list of webpage links.
This search approach that combines LLM, RAG, and Agent technologies lacks a standardized name. Some refer to it as AI-powered Search, while others call it Conversational Search or LLM-powered Search. From a technical perspective, this article terms it LLM-enhanced search.
Traditional Search Engine
As shown in Figure 2, the traditional search engine workflow consists of three main steps:
Collecting and processing vast amounts of internet data;
Creating indexes and developing retrieval algorithms for quick information discovery;
Processing user queries by breaking them down and using retrieval algorithms to find core information, then displaying the most relevant results.

However, traditional approach has several drawbacks, including redundant content, missing key information, and poor efficiency. For example, when users seek answers to questions, they want complete and accurate information. Instead, traditional search engines provide multiple webpage links (with some even mixing in advertisements), forcing users to click through various pages and mentally compile and summarize the information they need.
LLM-Enhanced Search
LLM-enhanced search engines effectively solve traditional search limitations by using LLMs to understand user intent, retrieve relevant content efficiently, and generate precise answers.

The modules shown in Figure 3 are optional and can be customized based on specific requirements.
For example, Search with Lepton does not include internal knowledge bases.

As shown in Figure 4, Search with Lepton follows a RAG-like workflow: it searches external data, caches the results, expands queries by suggesting related questions, and generates responses using LLMs.
In the RAG module of Figure 3, reranking functionality can be added, the typical one is OpenPerPlex.

As shown in Figure 5, when the server receives a user query, OpenPerPlex first calls the Serper API to get initial search results. It then optimizes and reranks these results before using an LLM to generate responses based on the query and the refined results. Finally, it finds similar related questions to help guide users toward further exploration.
Unlike OpenPerPlex which relies on closed-source reranking services, Perplexica implements its own reranking logic.
private async rerankDocs(
query: string,
docs: Document[],
fileIds: string[],
embeddings: Embeddings,
optimizationMode: 'speed' | 'balanced' | 'quality',
) {
...
...
if (optimizationMode === 'speed' || this.config.rerank === false) {
if (filesData.length > 0) {
const [queryEmbedding] = await Promise.all([
embeddings.embedQuery(query),
]);
const fileDocs = filesData.map((fileData) => {
return new Document({
pageContent: fileData.content,
metadata: {
title: fileData.fileName,
url: `File`,
},
});
});
const similarity = filesData.map((fileData, i) => {
const sim = computeSimilarity(queryEmbedding, fileData.embeddings);
return {
index: i,
similarity: sim,
};
});
let sortedDocs = similarity
.filter(
(sim) => sim.similarity > (this.config.rerankThreshold ?? 0.3),
)
.sort((a, b) => b.similarity - a.similarity)
.slice(0, 15)
.map((sim) => fileDocs[sim.index]);
sortedDocs =
docsWithContent.length > 0 ? sortedDocs.slice(0, 8) : sortedDocs;
return [
...sortedDocs,
...docsWithContent.slice(0, 15 - sortedDocs.length),
];
} else {
return docsWithContent.slice(0, 15);
}
} else if (optimizationMode === 'balanced') {
const [docEmbeddings, queryEmbedding] = await Promise.all([
embeddings.embedDocuments(
docsWithContent.map((doc) => doc.pageContent),
),
embeddings.embedQuery(query),
]);
docsWithContent.push(
...filesData.map((fileData) => {
return new Document({
pageContent: fileData.content,
metadata: {
title: fileData.fileName,
url: `File`,
},
});
}),
);
docEmbeddings.push(...filesData.map((fileData) => fileData.embeddings));
const similarity = docEmbeddings.map((docEmbedding, i) => {
const sim = computeSimilarity(queryEmbedding, docEmbedding);
return {
index: i,
similarity: sim,
};
});
const sortedDocs = similarity
.filter((sim) => sim.similarity > (this.config.rerankThreshold ?? 0.3))
.sort((a, b) => b.similarity - a.similarity)
.slice(0, 15)
.map((sim) => docsWithContent[sim.index]);
return sortedDocs;
}
}
The main idea of rerankDocs function is to use query and docs to search through both documents and locally uploaded files (extracting text fragments and embeddings from files specified by fileIds). In speed mode or when reranking is disabled, it performs only basic similarity calculations on file text fragments. In balanced mode, however, it combines both web search results and file content for comprehensive similarity calculations. The system uses embeddings to calculate similarity scores between user queries and documents, then reranks the results. Finally, it returns up to 15 of the most relevant documents.
In addition to the reranking features, graph theory and multi-agent architecture can be incorporated into LLM-enhanced search workflow. MindSearch is a typical example.
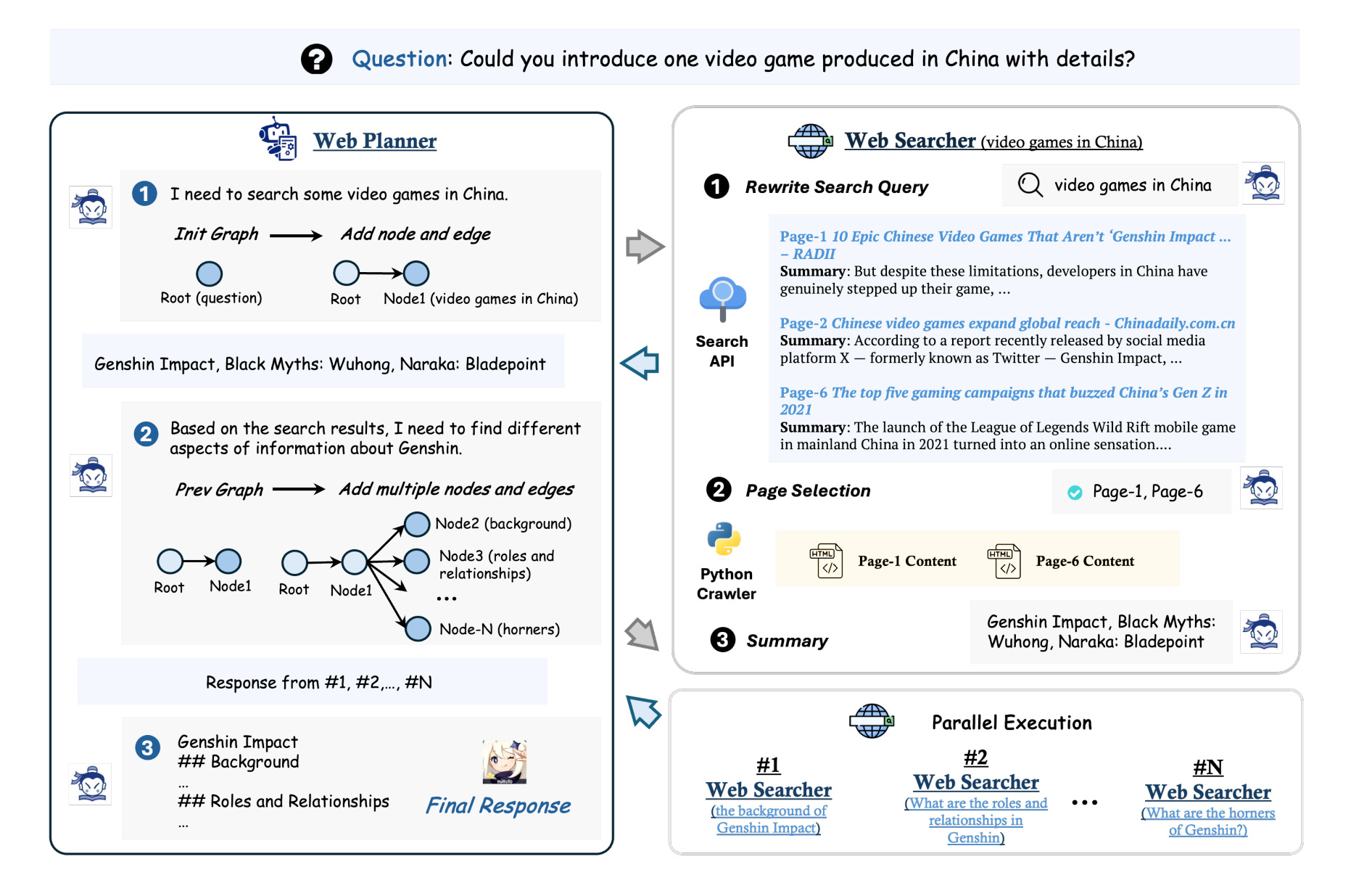
As shown in Figure 6, MindSearch framework consists of two main components: WebPlanner and WebSearcher.

WebPlanner breaks down complex user queries by building a directed acyclic graph (DAG). It places the initial question and final answer as the start and end nodes, then gradually adds and links intermediate search nodes to map out the dependencies between search steps (Step 1 and 2 in Figure 7). Once nodes are added to graph, it calls WebSearcher to perform the search process and summarize information.
Using LLM's code generation capabilities, particularly Python function calls, it dynamically constructs and runs the planning graph, allowing for flexible, step-by-step breakdown of search tasks (Step 3 in Figure 7).
class WebSearchGraph provides the details of graph-related actions.
class WebSearchGraph:
is_async = False
SEARCHER_CONFIG = {}
_SEARCHER_LOOP = []
_SEARCHER_THREAD = []
def __init__(self):
self.nodes: Dict[str, Dict[str, str]] = {}
self.adjacency_list: Dict[str, List[dict]] = defaultdict(list)
self.future_to_query = dict()
self.searcher_resp_queue = queue.Queue()
self.executor = ThreadPoolExecutor(max_workers=10)
self.n_active_tasks = 0
def add_root_node(
self,
node_content: str,
node_name: str = "root",
):
...
...As shown in Figure 8, WebSearcher is a RAG agent that handles specific sub-queries through web access. It works in three steps: first, it broadens the search scope by generating multiple similar queries; second, it retrieves result summaries from search engines like Google and Bing; and third, it selects the most valuable webpages for detailed reading and summarization.

Of course, to implement standard RAG functionality, we need a PDF parser component. We can either train our own models, use closed-source services, or like MemFree, use the open-source Langchain PDFLoader.
import { PDFLoader } from "@langchain/community/document_loaders/fs/pdf";
import { DocxLoader } from "@langchain/community/document_loaders/fs/docx";
import { PPTXLoader } from "@langchain/community/document_loaders/fs/pptx";
export async function getFileContent(file: File) {
switch (file.type) {
case "text/markdown": {
if (file.name.endsWith(".md")) {
const arrayBuffer = await file.arrayBuffer();
return {
type: "md",
url: `local-md-${file.name}`,
markdown: new TextDecoder("utf-8").decode(arrayBuffer),
};
} else {
throw new Error("Unsupported file type");
}
}
case "application/pdf": {
const loader = new PDFLoader(file, {
splitPages: false,
});
const docs = await loader.load();
return {
type: "pdf",
url: `local-pdf-${file.name}`,
markdown: docs[0].pageContent,
};
}
case "application/vnd.openxmlformats-officedocument.wordprocessingml.document": {
const loader = new DocxLoader(file);
const docs = await loader.load();
return {
type: "docx",
url: `local-docx-${file.name}`,
markdown: docs[0].pageContent,
};
}
case "application/vnd.openxmlformats-officedocument.presentationml.presentation": {
const loader = new PPTXLoader(file);
const docs = await loader.load();
return {
type: "pptx",
url: `local-pptx-${file.name}`,
markdown: docs[0].pageContent,
};
}
default:
throw new Error("Unsupported file type");
}
}Other frameworks like gerev uses the open-source PyPDF2 library.
from PyPDF2 import PdfReader
from typing import List
from langchain.document_loaders import PyPDFLoader
from langchain.schema import Document
from langchain.text_splitter import CharacterTextSplitter
def pdf_to_text(input_filename: str) -> str:
pdf_file = PdfReader(input_filename)
text=''
for page in pdf_file.pages:
text = text + page.extract_text()
return text
def pdf_to_textV2(input_filename: str) -> str:
loader = PyPDFLoader(input_filename)
documents = loader.load()
text_split = CharacterTextSplitter(chunk_size=256, chunk_overlap=0)
texts = text_split.split_documents(documents)
current_paragraph = ''
for text in texts:
paragraph = text.page_content
if len(current_paragraph) > 0:
current_paragraph += '\n\n'
current_paragraph += paragraph.strip()
return current_paragraphAs for chunking, like the PDF parser, there are also the same three options. MemFree uses Langchain's RecursiveCharacterTextSplitter.
import { RecursiveCharacterTextSplitter } from "@langchain/textsplitters";
import { Document } from "@langchain/core/documents";
import { append } from "./db";
import { getMd, readFromJsonlFile } from "./util";
import { getEmbedding } from "./embedding/embedding";
import { processTweet } from "./tweet";
const mdSplitter = RecursiveCharacterTextSplitter.fromLanguage("markdown", {
chunkSize: 400,
chunkOverlap: 40,
});
const textSplitter = new RecursiveCharacterTextSplitter({
chunkSize: 400,
chunkOverlap: 40,
});
function extractImage(markdown: string) {
const imageRegex = /!\[.*?\]\((.*?)\)/;
const match = imageRegex.exec(markdown);
return match ? match[1] : null;
}
export async function ingest_jsonl(url: string, userId: string) {
const data = await readFromJsonlFile(url);
const table = await append(userId, data);
}
export async function ingest_text_content(
url: string,
userId: string,
content: string,
title: string
) {
const documents = await textSplitter.createDocuments([content]);
const data = await addVectors("", title, url, documents);
const table = await append(userId, data);
}Commentary
This article introduces the core architecture, workflow, and implementation methods of LLM-enhanced search.
However, in my view, LLM-enhanced search faces several limitations.
It performs worse than traditional search engines when handling location-specific queries—for example, when asking "what's the weather like today."
The RAG functionality remains rudimentary, requiring developers to implement advanced RAG modules for specific needs like query refinement and prompt compression.
This field currently lacks practical evaluation benchmarks that cover RAG and search capabilities.
As the number of conversation turns increases, current systems lack intelligent decision-making capabilities to coordinate different components. For example, they cannot determine whether the 18th round of dialogue needs query understanding, external retrieval, reranking, or other modules.
Additionally, many open-source projects choose to use TypeScript because it is the mainstream language for frontend development. Using TypeScript for backend development maintains consistency between frontend and backend languages.
Overall, from the current perspective, LLM-Enhanced Search represents the future of search technology. While still in its early stages, it has significant room for improvement.
New directions may shift from content understanding to content generation, such as directly creating videos from search content. Time will tell—let's wait and see.
“Great article! What you list are indeed some key building blocks of AI-optimized search engines.
One of the biggest pain points I see today is having to rely on engines like Bing, only to waste time reranking results. It’s inefficient, but I think we’re moving toward a future where AI-optimized search engines handle indexing, ranking, and access with smarter, more adaptive, and more ethical logic.
This is what we're building at Linkup (https://www.linkup.so/) 🤘