

This is the Chapter 70 of this insightful series!
Why Traditional RAG Just Doesn’t Cut It Anymore
Standard RAG systems are starting to show their limits.
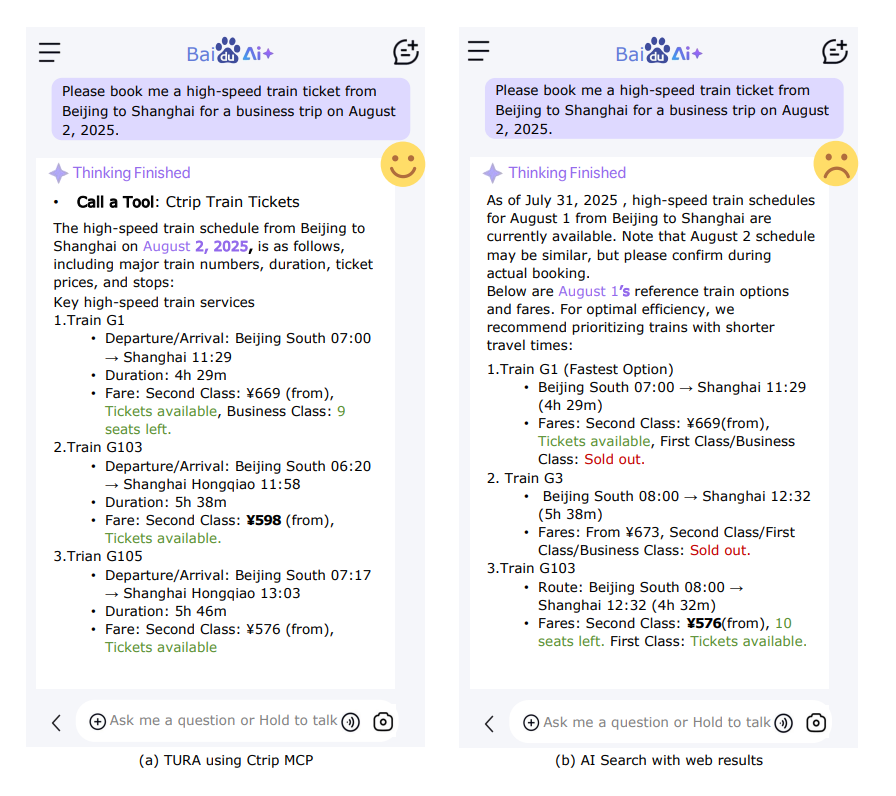
Here’s the catch: most of today’s RAG pipelines are built on top of static indexes. They can only “read” content that’s already been crawled and stored. For instance, when a user asks for "high-speed train tickets from Beijing to Shanghai for next week," a standard RAG system, being incapable of accessing live ticketing APIs, would typically retrieve outdated or irrelevant information from static webpages and fail to perform the required action.
But users today want a lot more.
They don’t just want an answer. They want to check ticket prices, book a hotel, get the weather forecast, and plan their entire trip — all within the same conversation. And they expect it to just work. That’s the new bar. RAG as we know it wasn’t built for this kind of dynamic, multi-step reasoning over real-time information.
TURA: A Three-Stage Agentic, Tool-Augmented Architecture
Enter TURA — short for Tool-Augmented Unified Retrieval Agent — a system that takes traditional RAG beyond passive “reading” and turns it into active, tool-powered interaction.
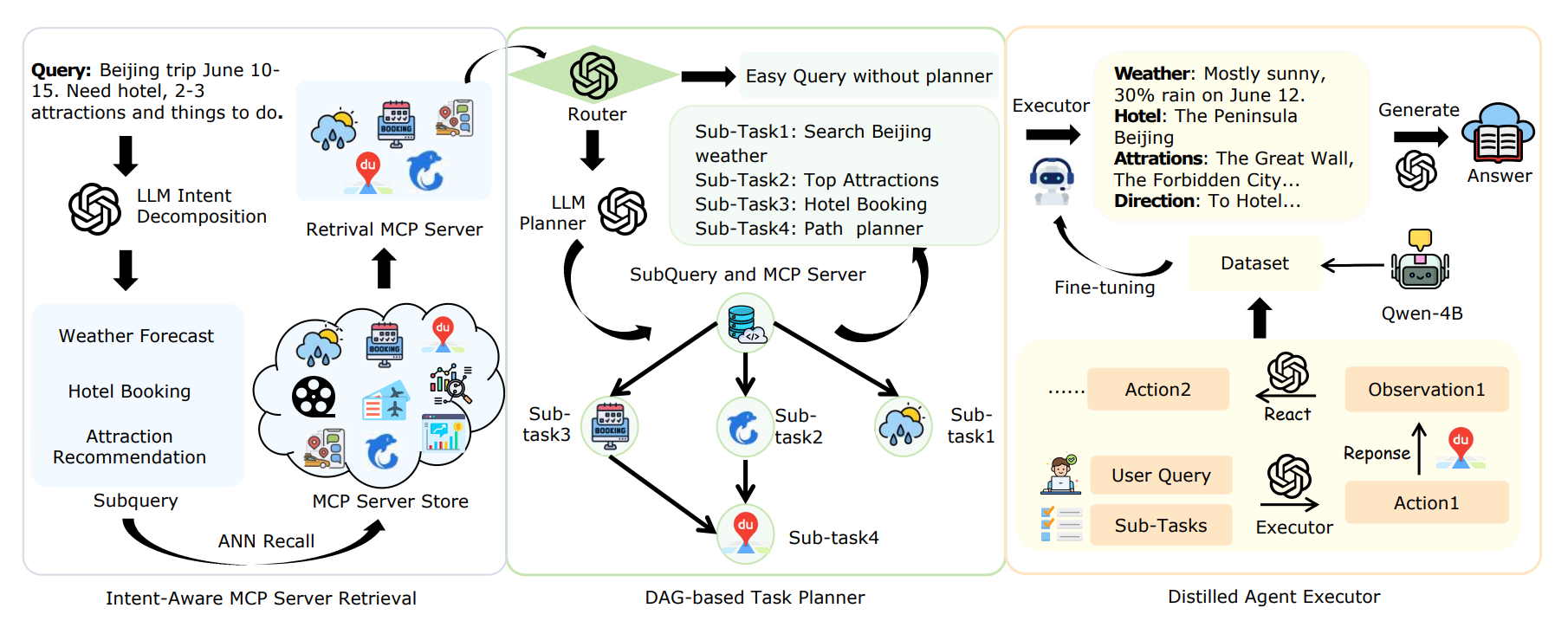
Instead of just searching static content, TURA can reason through tasks, call APIs, and stitch together results — all in a single flow. It’s built around three tightly connected stages:
Retrieve: Breaks down your query into smaller “mini-intents,” then instantly picks the right tools from thousands available. Key module: Intent-Aware MCP Server Retrieval.
Plan: Maps those mini-intents into a Directed Acyclic Graph (DAG), so tasks that don’t depend on each other can run in parallel — saving time. Key module: DAG-based Task Planner.
Execute: Uses a lightweight model distilled from a larger LLM to smartly execute each tool call — fast, accurate, and efficient. Key module: Distilled Agent Executor.
It’s like giving your RAG system a brain, a to-do list, and a toolbox — so it doesn’t just find information, it gets things done.
A Closer Look: What Powers Each Stage Behind the Scenes
Let’s break down the engine room of TURA — the three stages may look clean on the surface, but each one packs serious innovation under the hood.
Intent-Aware Retrieval: How Do You Pick 5 Relevant Tools in Just One Second?
Query Decomposition
Instead of treating a query like “Plan a 5-day trip to Beijing” as a single task, the system breaks it down into sub-intents like:
“Check Beijing weather”
“Find 5 must-see attractions”
“Book a hotel”
“Plan the route”
Semantic-Enhanced Indexing
Each tool in the system is preloaded with around 20 example phrasings users might use — bridging the gap between casual human language and dry API docs.
Multi-Vector Recall with ERNIE
For retrieval, TURA uses MaxSim-based multi-vector search powered by ERNIE.
DAG-Based Task Planning: Turning Bottlenecks into Parallel Pipelines
Traditional systems treat complex queries as step-by-step workflows. TURA doesn’t.
Instead, it builds a DAG (Directed Acyclic Graph) where tasks that don’t depend on each other can run in parallel.
Example: Hotel booking and weather checking can happen at the same time. But route planning waits until both are done.
Distilled Execution: When Small Models Punch Above Their Weight
Teacher: DeepSeek-V3 (671B)
Student: Qwen3-4B (distilled)
Despite the massive size difference, the distilled model holds its own.
What’s the trick? During training, TURA keeps the thought process (chain of thought) from the teacher. But at inference time, the student skips the “thinking aloud” and jumps straight to action — saving tokens while staying sharp.
It’s like learning from a chess grandmaster — and then skipping the narration when it’s your turn to play.
Evaluation
In the end-to-end offline evaluation using MCP-Bench, TURA focused on two core metrics: Answer Accuracy and Faithfulness — each assessed through both human annotation and LLM-as-judge.
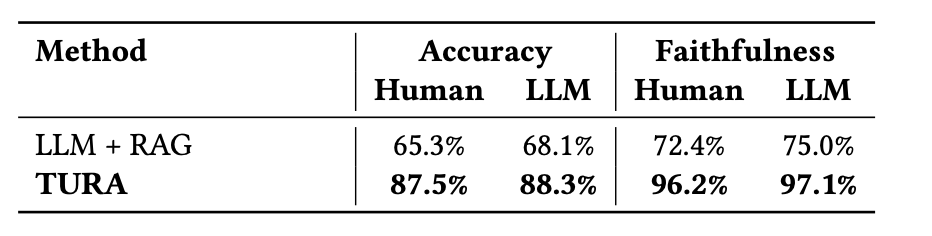
Across the board, TURA showed a significant lift over traditional RAG systems — not just in getting the answer right, but in staying grounded in the facts. What’s more, the improvements held up consistently across both human evaluations and automated scoring, providing high confidence that the gains aren’t just artifacts of the metric, but reflect real, tangible progress.
Thoughts
At the heart of TURA lies a simple but powerful idea: unify the best of both worlds — the static retrieval strengths of traditional RAG systems, and the real-time action-taking capabilities of agents — all within a clean, three-stage architecture.
This isn’t just another framework glued together with buzzwords. TURA is designed to tackle the very thing that vanilla RAG can’t handle: dynamic, time-sensitive tasks like ticket booking, live weather, or route planning.
And to top it off, TURA makes all of this actually deployable. It distills the reasoning power of massive teacher models into smaller, lighter models — ones that can run fast, make smart tool calls, and still keep up with user expectations. This kind of thoughtful engineering — striking a rare balance between top-tier performance and production-grade efficiency — offers a practical path forward for scaling the next generation of AI-native search.