

This series covers common interview questions in the field of AI.
Ever wondered how long it actually takes to train a 1B-parameter language model on a trillion tokens?
It's a simple question on the surface — but the answer opens up a whole world of compute, efficiency, and scale.
Floating Point Operations
Let’s start with an important question: How many floating point operations (FLOPs) does it actually take to train a Transformer model on a single token?
According to the scaling laws of Transformer, the rough rule of thumb is:
FLOPs per token ≈ 6 × the number of model parameters (N)
Here’s how that breaks down:
Forward pass: ~2N FLOPs
Backward pass (including gradient calculation): ~4N FLOPs
Total: ~6N FLOPs per token
It’s worth noting that the "6N FLOPs per token" only accounts for forward and backward passes. It does not include activation recomputation, regularization terms, or optimizer overhead (e.g., Adam typically adds an additional 2–3× FLOPs).
Say we’re working with a 1B-parameter model — that’s 1 × 10⁹ parameters. Using the 6N estimate, you’re looking at:
6 × 10⁹ FLOPs per token
Yep, that’s 6B floating point operations just to train on a single token. If we’re training on 1T tokens, and each token costs around 6B FLOPs, the total compute adds up fast:
6 × 10⁹ FLOPs/token × 1 × 10¹² tokens = 6 × 10²¹ FLOPs
As we can see, training even a "small" 1B model at this scale is no small task.
Single GPU Training Time
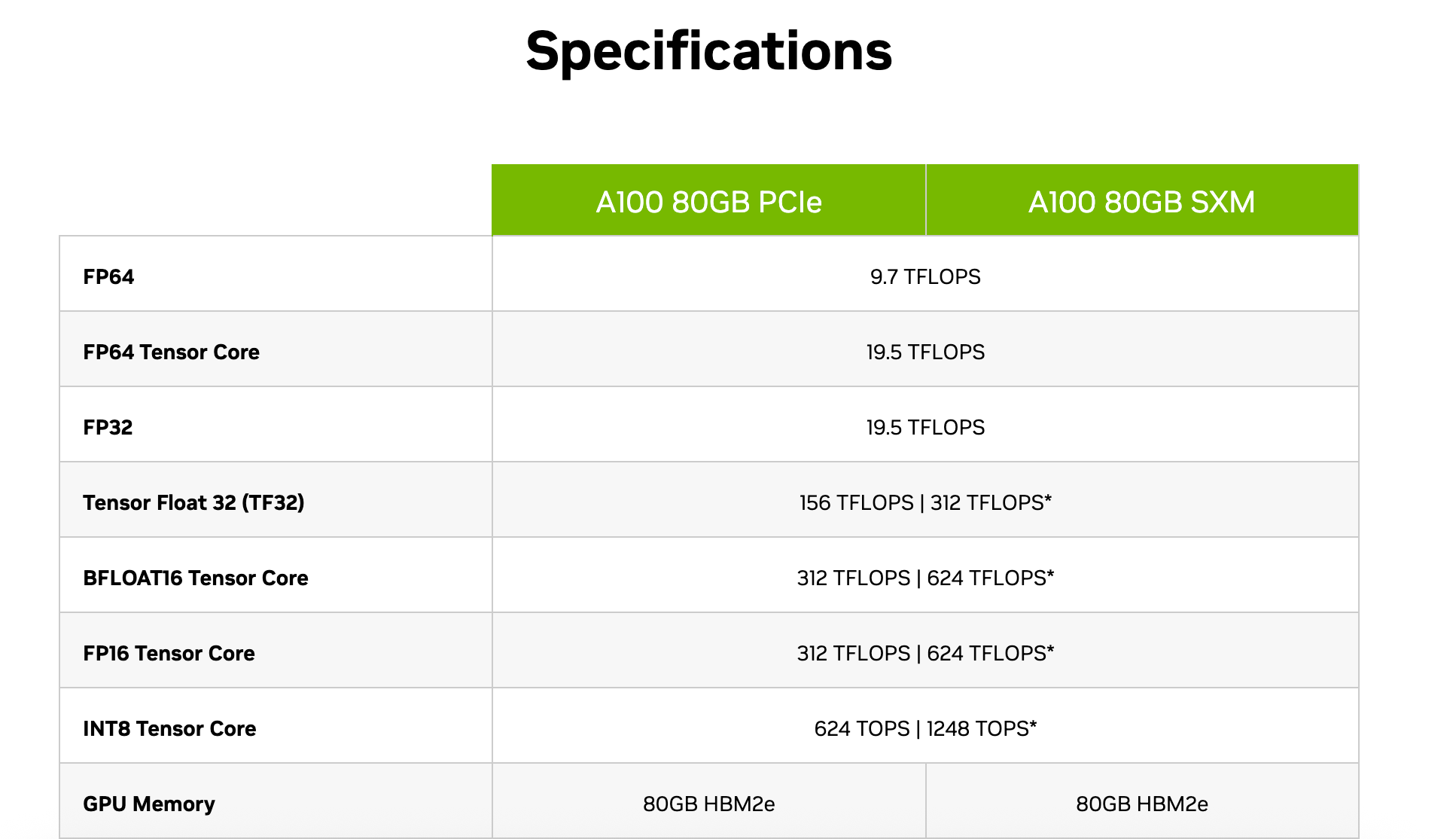
Take the NVIDIA A100 80GB, for example. Its theoretical peak performance in FP16/Tensor Core mode is 312 × 10⁹ FLOPS, but in practice, you’re likely getting around 50% efficiency — so roughly 150 × 10¹² FLOPS per GPU.
Now let’s do the math:
6 × 10²¹ total FLOPs ÷ 150 × 10¹² FLOPs/sec ≈ 40 million seconds → 1.11 × 10⁴ h → 463 d
That’s about 463 days of non-stop training on a single A100.
More than a year of compute time for a "tiny" 1B model on 1T tokens… assuming we're only using one GPU.
Money
Now let’s talk money.
If we’re renting cloud GPUs — and let’s say the typical cost is around $2 per GPU hour — then training this model on a single A100 would cost you:
1 GPU × 11,100 hours × $2/hour = $22,200
No Time to Wait? Scale Up.
Of course, if we’re not planning to wait over a year, we can always scale up.
Renting 8 A100s brings the training time down to around 1,389 hours — that’s just under 58 days.
Go with 32 A100s, and you’re looking at roughly 347 hours, or about two weeks.
One thing worth noting: in the real world, scaling isn't perfect.
As you add more GPUs, they need to constantly communicate — syncing gradients, aggregating parameters, coordinating updates. And that communication comes at a cost.
So while 8 GPUs should be 8× faster than one, in practice it might only be around 7.5×. With 32 GPUs, you might get 28× the speed instead of a perfect 32×.
This drop in scaling efficiency means the total GPU hours — and therefore the total cost — actually goes up as you add more GPUs.
So that original $22,200 estimate? It assumes perfect efficiency, which you almost never get in reality.
In short: you're paying extra for speed. Faster training, higher cost. It’s all about where you draw the line between time and money.