

Welcome back, let's dive into Chapter 66 of this insightful series!
I recently shared a RAG survey (A Recent Survey of Systematic Review in RAG — AI Innovations and Insights 62).
Now a latest review has landed (A Systematic Literature Review of Retrieval-Augmented Generation: Techniques, Metrics, and Challenges).
In this edition, we focus on what's worth reading.
Distribution of Included Studies
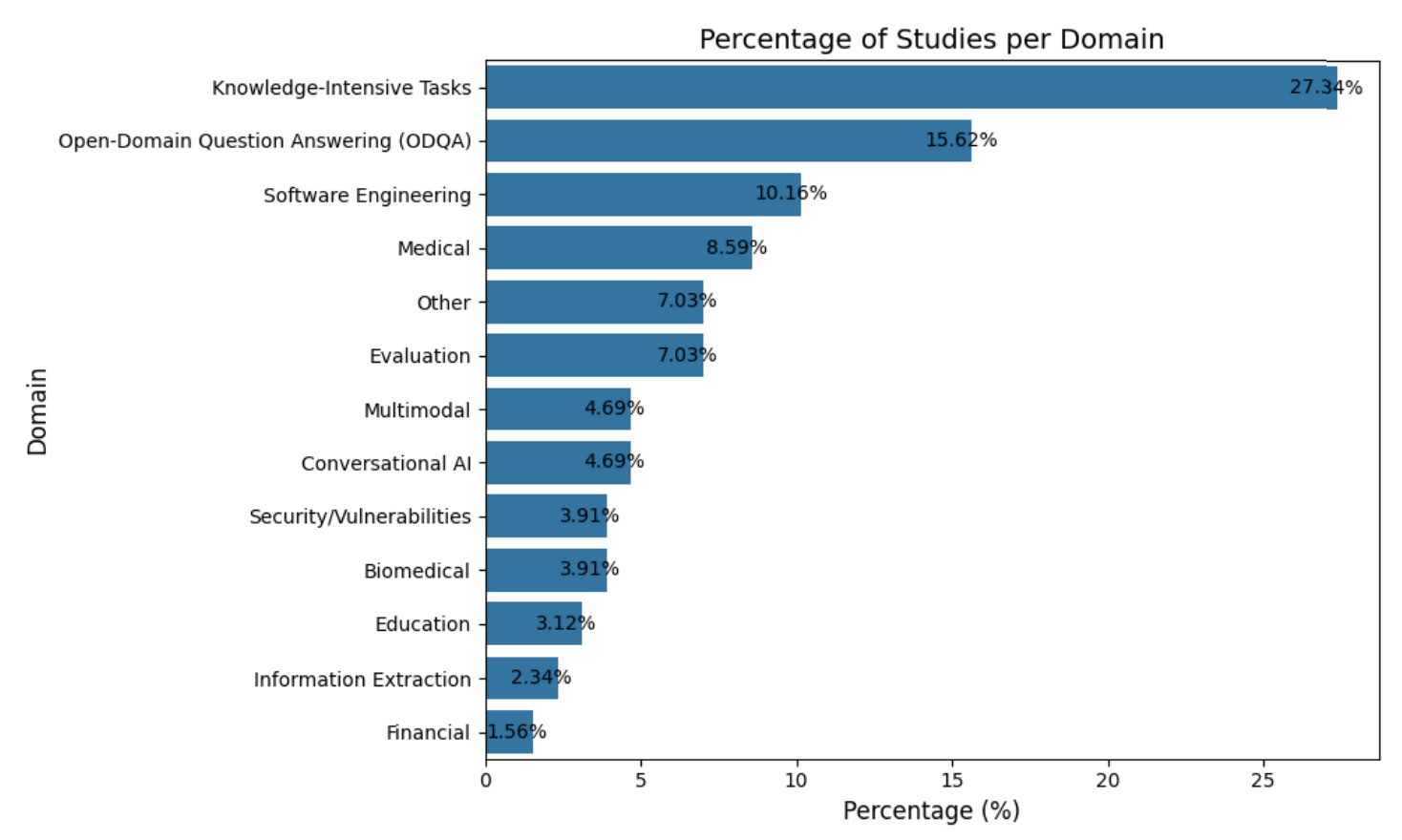
Figure 1 breaks down the included studies by research area. RAG shows broad coverage, with most of the action in knowledge-intensive tasks and open-domain QA, plus tailored uses in software engineering, healthcare, dialogue, and multimodal settings.
The Master Index
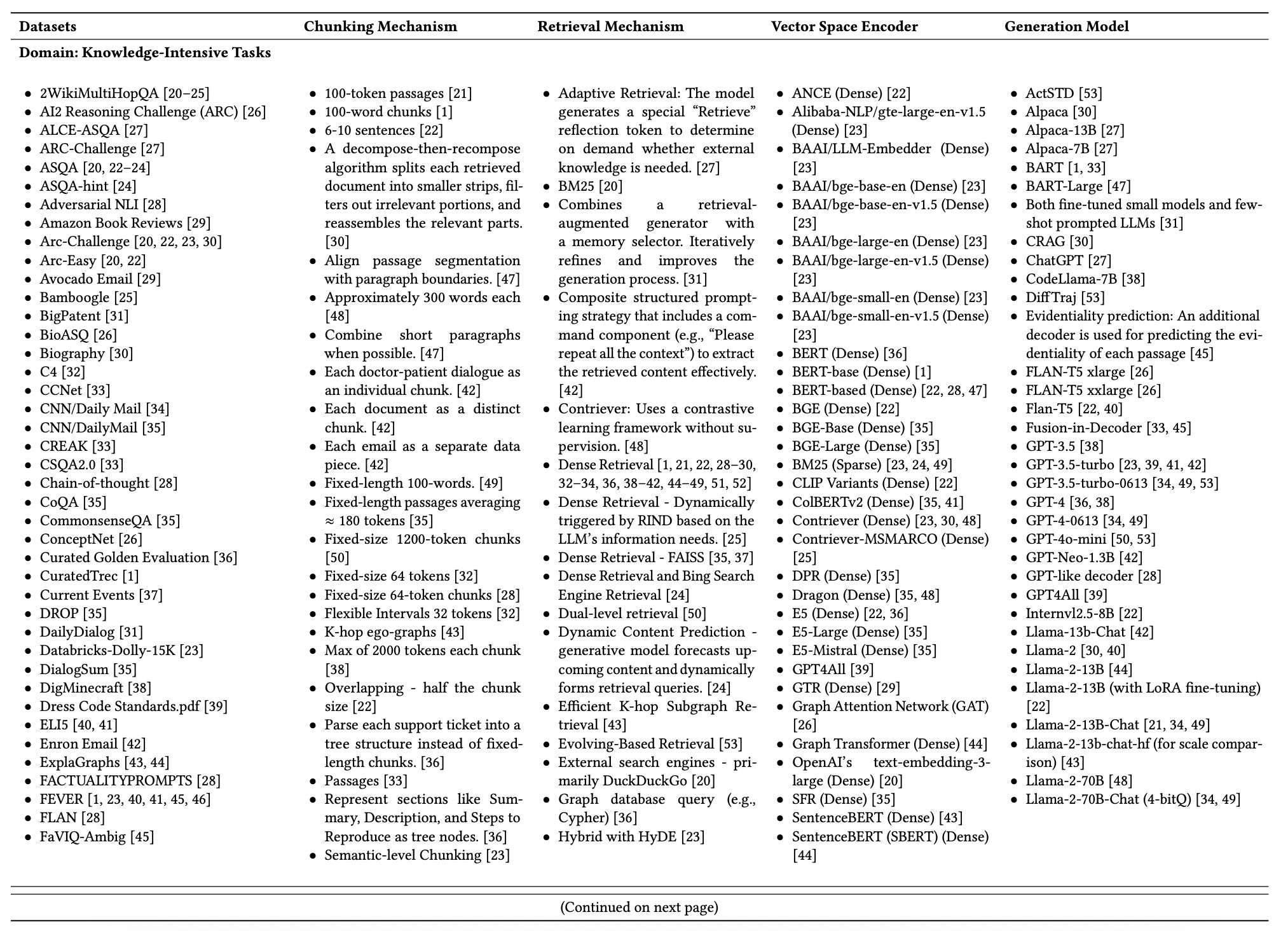
This table summarizes all 128 RAG studies this survey included, grouped by domain. Each entry records five aligned components: datasets, chunking mechanism, retrieval mechanism, vector-space encoder, and generation model.
I've never seen a table stretch this far: page 6 through 18 in the original paper. If you're building a PDF parser, this is your benchmark sample.
This table is huge, so I'm trimming it here. Interested readers can find it in the original paper.
What are the Key Topics Already Addressed?
Retrieval Mechanisms
Below are the common retrieval strategies:
Sparse methods (e.g., BM25) are fast but weak on semantic recall.
Dense retrieval (e.g., DPR) embeds queries and documents into vectors and uses MIPS.
Hybrid sparse–dense pipelines try to balance recall and precision.
Encoder–decoder based query rewriting turns multi-hop or conversational questions into standalone, retrievable queries.
Graph retrieval methods: Build a knowledge graph from passages and entities, then retrieve the most relevant subgraphs or paths to feed the model with structured evidence.
Iterative frameworks: Interleave retrieval and generation in a feedback loop: each model output sharpens the next query, step by step closing the semantic gap.
Specialized retrievers: Tailor the retriever to a modality (code, images) or domain (e.g., clinical reports) to maximize task-specific relevance.
In practice these building blocks are mixed and matched into well-worn combos.
Vector Databases
ANN indexes like HNSW and FAISS power millisecond-scale vector lookups. Engineering patterns include GPU sharding and managed offerings (Pinecone, etc.), but pain points remain: synchronization latency, update throughput, and cost.
Open challenges include:
Truly real-time adaptive indexes.
Smooth interoperability across index types and embedding formats.
Cost-aware scaling remains a blind spot—few teams optimize latency and infrastructure together.
In addition, domain-specific vector stores are emerging—purpose-built for code, biomed, and finance to match each data type's characteristics.
Document Chunking
There are four typical chunking strategies:
Keep reading with a 7-day free trial
Subscribe to AI Exploration Journey to keep reading this post and get 7 days of free access to the full post archives.