


The Logic Behind OCRFlux — AI Innovations and Insights 57

Welcome back, let’s dive into Chapter 57 of this insightful series!
I’ve shared a lot in the past about PDF parsing (AI Exploration Journey: PDF Parsing and Document Intelligence).
Today, let’s take a closer look at OCRFlux — a new tool built on a 3B-parameter multimodal LLM. It’s designed to convert PDFs and images into clean, structured Markdown text.
Traditional OCR tools often fall apart when dealing with content that spans across pages. The core feature of OCRFlux is its ability to intelligently merge tables and paragraphs that span across pages. This is crucial for working with complex documents like academic papers, financial reports, and technical manuals.

Handling tables and paragraphs that span across pages has always been one of the classic challenges in building PDF parsing tools. Let’s dive into how OCRFlux tackles it.
Overview
OCRFlux takes a pretty straightforward approach: it treats the problem as two tasks — Single-Page Parsing and Cross-Page Merging. These tasks are trained together in a single model.
Once the model is trained, you can feed in a multi-page PDF, and it outputs clean, readable Markdown.
Here’s how the inference process works: through the parse() function in ocrflux/inference.py, OCRFlux runs a full pipeline: multi-page PDF → single-page Markdown → cross-page element & table merging → clean, readable Markdown.
Powered by Qwen 2.5-VL’s vision-language capabilities, it delivers end-to-end document parsing with no rule-based templates.
Figure 2 shows the prompts used in the following stages.

Stage 1: Page → Markdown

First, the system batches up queries by calling build_page_to_markdown_query for each page in the PDF. These are then sent all at once to the vLLM — taking advantage of multimodal parallelism — and the responses are parsed into page-level Markdown.
Stage 2: Cross-page Element Merge Detection
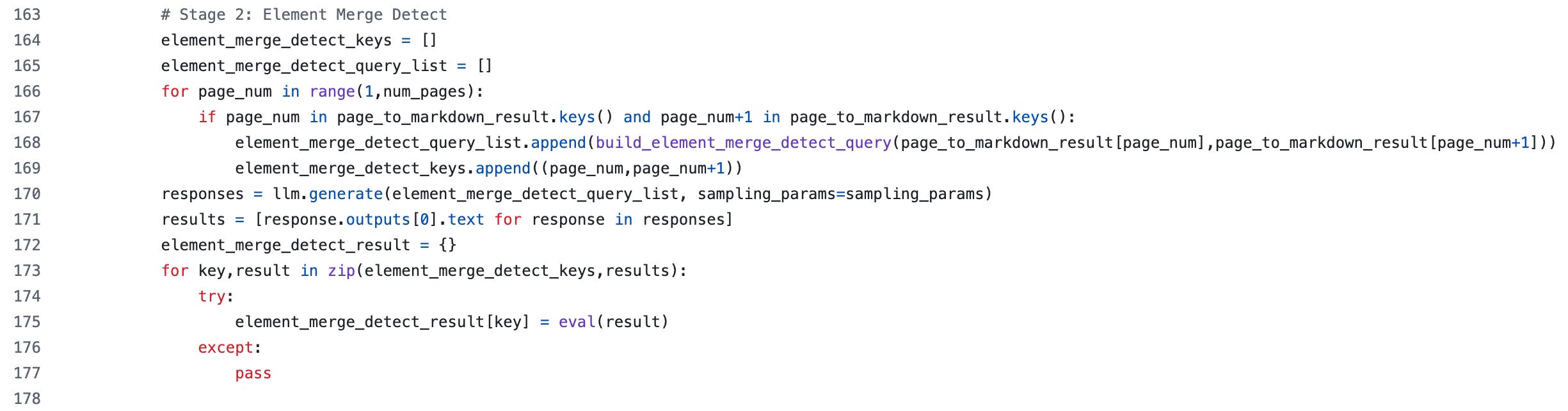
Next, it filters out the successfully parsed pages and pairs up adjacent ones. For each valid pair, it generates a query using build_element_merge_detect_query and runs batch inference through vLLM to detect elements that may have been split across pages.
Stage 3: Cross-page Table Merging

Now comes the last part — merging tables back together. The system looks through the merge detection results and finds pairs where both pages have matching <table> tags. These are added to html_table_merge_keys. For each of these pairs, it runs build_html_table_merge_query to generate a fully merged, structured table.
Training
OCRFlux-3B is fine-tuned from Qwen2.5-VL-3B-Instruct, with a focus on two core tasks: single-page parsing and cross-page merging of paragraphs and tables.
Both tasks are jointly trained in a single multimodal model using different prompts, enabling OCRFlux to handle end-to-end document parsing with strong cross-page reasoning.
Single-Page Parsing
For single-page parsing, the model was trained on 1.1 million manually labeled pages from financial and academic documents, plus 250,000 pages from the public olmOCR-mix-0225 dataset (with low-quality GPT-4o-labeled table pages filtered out).
Unlike some earlier approaches, OCRFlux uses only page images—no metadata—making it more robust and lightweight.
Tables in the training data are represented in HTML (not Markdown) to better handle complex structures like rowspan and colspan.
Cross-Page Merging
For cross-page merging, the model was trained to detect and merge split elements across pages—450,000 samples for detection, and 100,000 for merging, all from private datasets.
Detection task: Given the Markdown representations of two consecutive pages—each structured as a list of elements like paragraphs and tables—the goal is to identify which elements should be merged across the page break.
Merging task:Paragraphs are merged by concatenation, while tables require more complex handling.
Thoughts and Insights
When it comes to handling cross-page content, the traditional pipeline usually looks something like this: OCR → model-based layout analysis → table/paragraph extraction → result merging.
OCRFlux takes a very different approach. Instead of treating these as separate steps, it folds the entire pipeline into a single 3B-parameter multimodal LLM — combining visual parsing and semantic reconstruction in one unified inference loop.
Despite being only 3B in size, evaluation shows that it performs competitively against olmOCR-7B models (AI Innovations and Insights 31: olmOCR , HippoRAG 2, and RAG Web UI). This offers a much better cost-performance ratio for small businesses or on-premise deployments.
But in my view, the real moat isn’t the model — it’s the data and pipeline design. The cross-page detection-and-merge task, along with high-quality HTML table supervision, depends on proprietary data that’s far harder to replicate than the model itself.