
The Best Practices of RAG
Typical RAG Process, Best Practices for Each Module, and Comprehensive Evaluation

The process of RAG is complex, with numerous components. How can we determine the existing RAG methods and their optimal combinations to identify the best RAG practices?
The paper "Searching for Best Practices in Retrieval-Augmented Generation" introduced in this article addresses this problem.
This article is divided into three main parts. First, it introduces the typical RAG process. Then, it presents best practices for each module of RAG. Finally, it provides a comprehensive evaluation.
Typical RAG Workflow
A typical RAG workflow includes several intermediate processing steps:
Query classification (determining if the input query requires retrieval)
Retrieval (efficiently obtaining relevant documents)
Re-ranking (optimizing the order of retrieved documents based on relevance)
Re-packing (organizing the retrieved documents into a structured form)
Summarization (extracting key information to generate responses and eliminate redundancy)
Implementing RAG also involves deciding how to split documents into chunks, choosing which embeddings to use for semantic representation, selecting a suitable vector database for efficient feature storage, and finding effective methods for fine-tuning LLMs, as shown in Figure 1.

Best Practices of Each Steps
Query Classification
Why is query classification needed? Not all queries require retrieval enhancement, as LLMs have certain capabilities. While RAG can improve accuracy and reduce hallucinations, frequent retrieval increases response time. Therefore, we classify queries first to determine if retrieval is needed. Generally, retrieval is recommended when knowledge beyond the model's parameters is required.
We can classify tasks into 15 types based on whether they provide sufficient information and display specific tasks and examples. Tasks based entirely on user-provided information are marked as "sufficient" and do not require retrieval; otherwise, they are marked as "insufficient" and may require retrieval.

This classification process is automated by training a classifier.

Chunking
Dividing the document into smaller chunks is crucial for improving retrieval accuracy and avoiding length issues in LLM. There are generally three levels:
Token-level chunking is straightforward but may split sentences, affecting retrieval quality.
Semantic-level chunking uses LLM to determine breakpoints, preserving context but taking more time.
Sentence-level chunking balances preserving text semantics with being concise and efficient.
Here, sentence-level chunking is used to balance simplicity and semantic retention. The chunking process is evaluated from the four dimensions below.
Chunk Size
Chunk size significantly affects performance. Larger chunks provide more context, enhancing comprehension, but increase processing time. Smaller chunks improve recall rates and reduce time but may lack sufficient context.

As shown in Figure 4, two main metrics are used: faithfulness and relevancy. Faithfulness measures whether the response is hallucinatory or matches the retrieved text. Relevancy measures whether the retrieved text and the response match the query.
Organization of Chunks
The results are shown in Figure 5. The smaller chunk size is 175 tokens, the larger chunk size is 512 tokens, and the block overlap is 20 tokens.

Embedding Model Selection
As shown in Figure 6, LLM-Embedder achieved results comparable to BAAI/bge-large-en but is only one-third its size. Therefore, LLM-Embedder is chosen to balance performance and size.

Metadata Addition
Enhancing chunk blocks with metadata like titles, keywords, and hypothetical questions can improve retrieval.
The paper does not include specific experiments but leaves them for future work.
Vector Databases
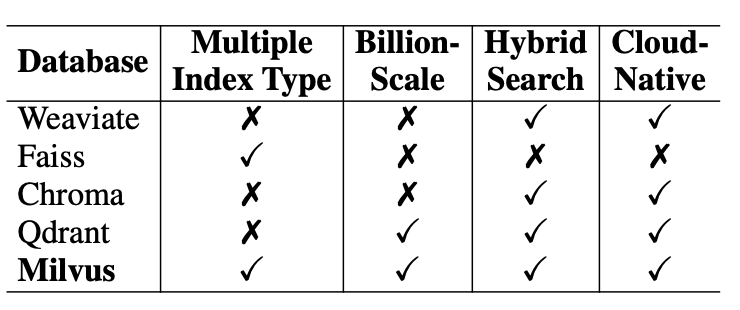
Figure 7 provides a detailed comparison of five open-source vector databases: Weaviate, Faiss, Chroma, Qdrant, and Milvus.
Milvus stands out among the evaluated databases, meeting all the basic criteria and outperforming other open-source options in performance.
Retrieval
For user queries, the retrieval module selects the top k documents most relevant to the query from a pre-constructed corpus, based on their similarity.
The following evaluates three retrieval-related techniques and their combinations:
Query Rewriting: This technique improves queries to better match relevant documents. Inspired by the Rewrite-Retrieve-Read framework, we prompt LLM to rewrite queries to enhance performance.
Query Decomposition: This method retrieves documents based on sub-questions extracted from the original query. These sub-questions are typically more complex and difficult to understand and process.
Pseudo-Document Generation: This method generates a hypothetical document based on the user's query and uses the embeddings of the hypothetical answer to retrieve similar documents. A notable implementation is HyDE.
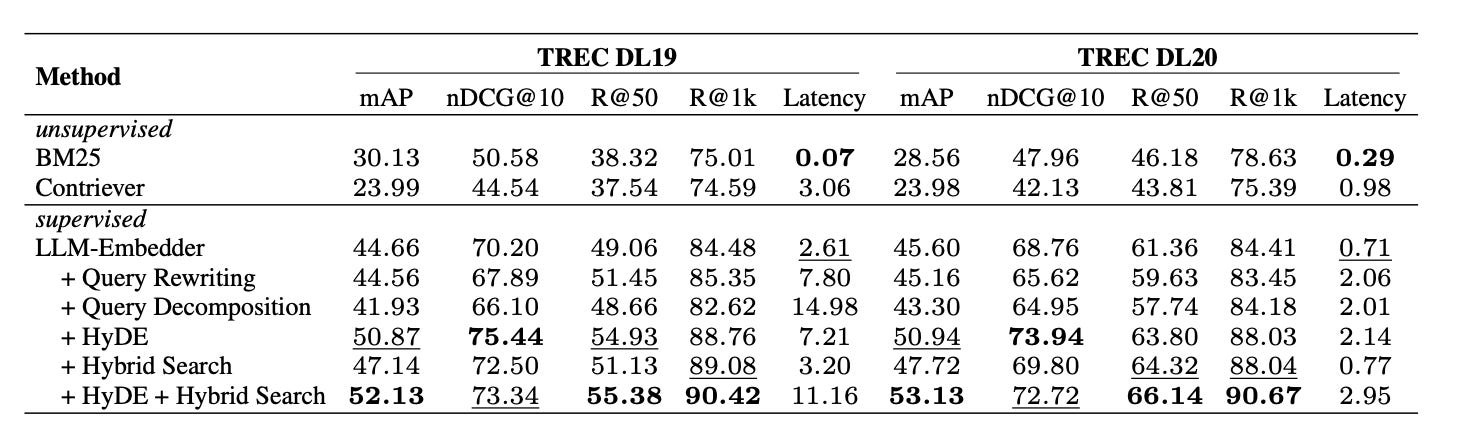
Figure 8 shows that the supervised methods significantly outperform the unsupervised methods. By combining HyDE and hybrid search, LLM-Embedder achieved the highest score.
Therefore, it is recommended to use HyDE + hybrid search as the default retrieval method. Hybrid search combines sparse retrieval (BM25) and dense retrieval (original embeddings), achieving high performance with relatively low latency.
Re-ranking
After an initial search, a re-ranking phase enhances the relevance of the retrieved documents, ensuring the most pertinent information appears at the top of the list. Two main methods are considered:
DLM Re-ranking: This method uses Deep Language Models (DLMs) for re-ranking. These models are fine-tuned to classify the relevance of documents to queries as "true" or "false." During fine-tuning, the models are trained with queries and documents annotated for relevance. During inference, documents are sorted based on the probability of the "true" label.
TILDE Re-ranking: TILDE independently calculates the likelihood of each query term by predicting the probability of each term in the model's vocabulary. Documents are scored by summing the precomputed log probabilities of the query terms, enabling fast re-ranking during inference. TILDEv2 improves this by only indexing terms present in the documents, using NCE loss, and expanding documents, thereby increasing efficiency and reducing index size.

As shown in Figure 9, it is recommended to use monoT5 as a comprehensive method balancing performance and efficiency. RankLLaMA is ideal for those seeking optimal performance, while TILDEv2 is suitable for quickly experimenting on a fixed set.
Re-packing
The performance of subsequent processes, such as LLM response generation, may be affected by the order in which documents are provided.
To address this, we have included a compact re-packing module in the workflow after re-ranking, with three methods:
The "forward" method repacks documents in descending order based on relevance scores from the reordering phase.
The "reverse" method arranges them in ascending order.
The "sides" option, inspired by Lost in the Middle, performs best when relevant information is located at the beginning or end of the input.
Since these re-packing methods mainly affect subsequent modules, their evaluation is introduced in the following review section.
Summarization
Retrieval results may contain redundant or unnecessary information, which can prevent the LLM from generating accurate responses. Additionally, long prompts may slow down the inference process. Therefore, effective methods to summarize retrieved documents are crucial in the RAG process.
Extractive compressors segment the text into sentences, scoring and ranking them based on importance. Generative compressors synthesize information from multiple documents to rephrase and generate coherent summaries. These tasks can be either query-based or non-query-based.
Three methods are primarily evaluated:
Recomp: It features both extractive and generative compressors. The extractive compressor selects useful sentences, while the generative compressor synthesizes information from multiple documents.
LongLLMLingua: It improves LLMLingua by focusing on key information relevant to the query.
Selective Context: It improves LLM efficiency by identifying and removing redundant information in the input context.
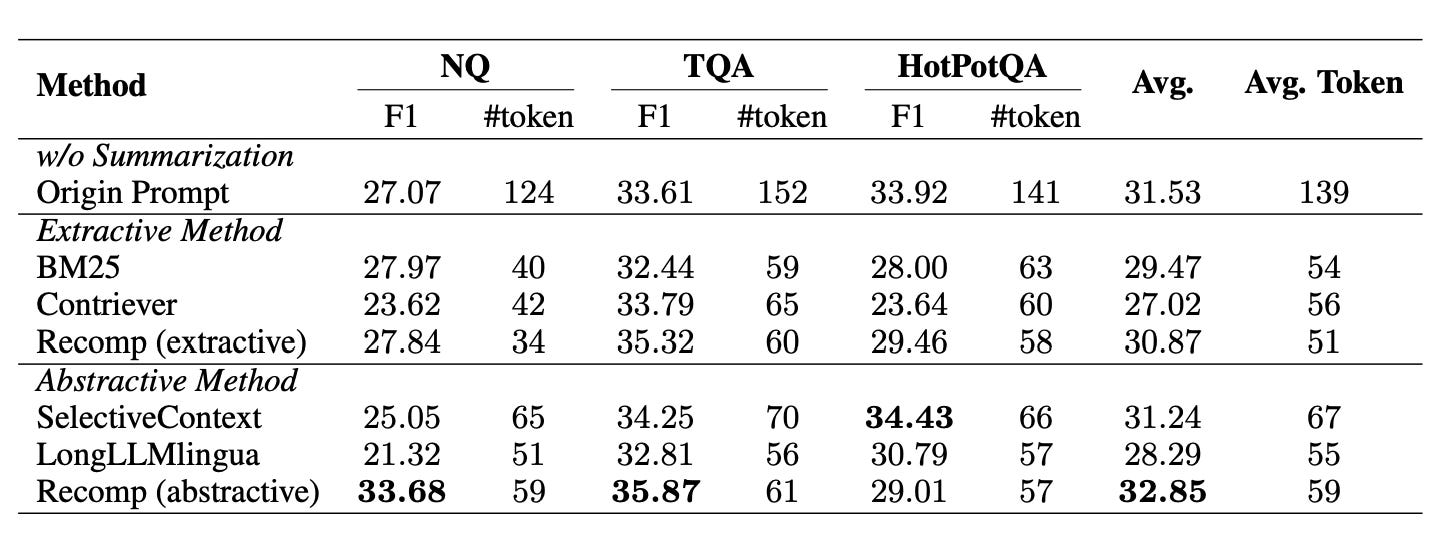
As shown in Figure 10, it is recommended to use Recomp because it performs excellently. Although LongLLMLingua did not perform well, it demonstrated better generalization ability without being trained on these experimental datasets. Therefore, we can consider it an alternative method.
Generator Fine-tuning
Figure 11 shows that the model trained with mixed relevant and random documents (Mgr) performs best when provided with gold documents or mixed context.
Therefore, mixing relevant and random context during training can enhance the generator's robustness to irrelevant information while ensuring effective use of relevant context.

Comprehensive Evaluation
Previous evaluations were conducted separately for each module, but now these modules are integrated for a comprehensive evaluation.

As shown in Figure 12, the following key insights are derived:
Query Classification Module: This module not only improves effectiveness and efficiency but also increases the overall score from 0.428 to an average of 0.443, and reduces query latency from 16.41 seconds to 11.58 seconds.
Retrieval Module: While the "Hybrid with HyDE" method achieved the highest RAG score of 0.58, its computational cost is high, requiring 11.71 seconds per query. Therefore, it is recommended to use the "Hybrid" or "Original" methods as they reduce latency while maintaining comparable performance.
Re-ranking Module: The absence of the re-ranking module results in a significant drop in performance. MonoT5 achieved the highest average score, demonstrating its effectiveness in enhancing the relevance of retrieved documents. This indicates the crucial role of re-ranking in improving the quality of generated responses.
Re-packing Module: The reverse configuration exhibited superior performance, achieving a RAG score of 0.560. This suggests that placing more relevant context closer to the query position yields the best results.
Summarization Module: Recomp demonstrated superior performance, although removing the summary module can achieve comparable results at lower latency. Nevertheless, Recomp remains the preferred choice because it addresses the generator's maximum length limitation.
Conclusion
Overall, two different RAG system implementation strategies are recommended:
Best Performance Practice: For the highest performance, include a query classification module, use the "Hybrid with HyDE" method for retrieval, adopt monoT5 for re-ranking, choose "Reverse" for re-packing, and utilize Recomp for summarization.
Balanced Efficiency Practice: To balance performance and efficiency, include a query classification module, implement the Hybrid method for retrieval, use TILDEv2 for reranking, choose "Reverse" for re-packing, and use Recomp for summarization.
We should note that the evaluation mentioned is mainly based on public datasets, and its performance on other datasets (such as private enterprise datasets) needs further assessment.
The main value of this paper is that it offers valuable ideas and methods for studying RAG best practices.
Do you have any articles or suggestions on improving incomplete answers when using RAG? We are having a problem with returning accurate lists.