
Redefining RAG: A Deep Dive into Golden-Retriever

Traditional approaches like fine-tuning Large Language Models (LLMs) for specific domains is not only computationally expensive but also prone to issues like the Reversal Curse, where the model may fail to generalize new knowledge effectively.
Furthermore, standard Retrieval-Augmented Generation (RAG) frameworks often misinterpret domain-specific terms, leading to less relevant document retrieval and ultimately reducing the effectiveness of the system.
In this artice, we introduce a study called "Golden-Retriever", a novel approach designed to enhance the capabilities of Retrieval Augmented Generation (RAG) systems in industrial settings. This framework is particularly focused on overcoming challenges related to domain-specific jargon and context interpretation, which are prevalent in industrial knowledge bases.
The motivation behind the development of Golden-Retriever stems from the need to efficiently navigate and retrieve information from vast industrial knowledge bases.
Comparison
Figure 1 illustrates the comparison of existing methods with Golden-Retriever, highlighting the need for a solution that can accurately handle ambiguous terms and provide relevant context before retrieval.

Golden-Retriever outperforms traditional RAG methods by addressing the root cause of retrieval inefficiencies: the ambiguity in the user's question.
Unlike methods such as Corrective-RAG or Self-RAG, which attempt to correct responses post-retrieval, Golden-Retriever enhances the query itself before retrieval, resulting in a more accurate and contextually relevant document selection.
Golden-Retriever
Golden-Retriever enhances the RAG framework by introducing a reflection-based question augmentation process. This process is designed to identify and clarify domain-specific jargon within a user’s query before document retrieval, thereby improving the relevance of the retrieved documents.
This augmentation is achieved by integrating both offline and online processes. Offline processes involve augmenting the document database using LLMs to ensure that the documents are more likely to be relevant when queried, while the online process focuses on augmenting the user’s question in real-time.
The paper’s Figure 2 provides a detailed workflow of the online inference process, showcasing how the system interacts with LLMs at various steps to refine the query.

The Golden-Retriever framework employs a multi-step process that significantly enhances the accuracy and relevance of document retrieval within industrial knowledge bases. Each step is meticulously designed to address specific challenges, such as domain-specific jargon and contextual ambiguities, ensuring that the system delivers highly relevant results. Below is a detailed breakdown of this workflow.
Step 1: LLM-Driven Document Augmentation
Before the system interacts with user queries, it performs a crucial offline preprocessing step known as LLM-Driven Document Augmentation. This step aims to enhance the document database by increasing the likelihood that relevant documents will be retrieved when queried.
The process begins with the collection of the company’s proprietary documents, which often exist in varied formats, such as PDFs, slides, and images with embedded text. These documents are then processed using Optical Character Recognition (OCR) to extract textual content.
Once the text is extracted, the documents are divided into smaller, manageable chunks, typically around 4,000 tokens each, depending on the capabilities of the LLM being used. Each chunk is then fed into an LLM, which generates summaries and contextual insights from the perspective of a domain expert.
This augmented data is stored in the document database, making the documents more semantically rich and contextually relevant for future queries.

Figure 3 illustrates this process, showing how document preprocessing enhances the system’s retrieval accuracy by ensuring that documents are contextually enriched before they are queried.
Step 2: Identify Jargons
The online processing begins with the identification of domain-specific jargon or abbreviations within the user’s query. Industrial documents are often filled with specialized terminology that can be ambiguous or unfamiliar to a generic LLM.
To handle this, Golden-Retriever uses an LLM to scan the query and extract any potential jargon. This extracted jargon is then listed in a structured format for further processing. This step ensures that the system recognizes all critical terms that could impact the accuracy of subsequent steps. This process is visually represented in Figure 2.
Step 3: Identify Context
After identifying jargon, the system determines the context of the query, which is crucial for accurately interpreting the jargon. Context can dramatically alter the meaning of technical terms, so it's essential that the system correctly classifies the query's context.
For instance, the acronym "RAG" might refer to "Retrieval-Augmented Generation" in a machine learning context but could mean something entirely different in another domain.
Golden-Retriever uses an LLM-driven approach to classify the query into the appropriate context by selecting from a predefined set of categories. This step is vital for ensuring that the system fully understands the query’s intent before proceeding with document retrieval.
Step 4: Query Jargons
Once the jargon and context are identified, the system queries a specialized jargon dictionary to retrieve detailed definitions, descriptions, and relevant notes about the terms. This ensures that the system has a comprehensive understanding of each term within the correct context before moving forward with document retrieval.
To achieve this, Golden-Retriever uses a SQL-based approach to query the jargon dictionary, avoiding the potential risks associated with generating SQL queries directly via an LLM. By ensuring that the queries are safe and reliable, this step enhances the overall accuracy of the system.
Step 5: Augment the Question
With jargon definitions and context information in hand, Golden-Retriever proceeds to augment the user’s original question. This augmented question incorporates the context and clarifies any ambiguous terms, transforming the query into a more precise and unambiguous form.
The augmented question is then used as input for the RAG framework, significantly improving the likelihood of retrieving the most relevant documents. The automation of this process ensures that the augmented query consistently reflects the necessary context and terminology.
Step 6: Query Miss Response
In some cases, the system may encounter jargon that is not found in the dictionary or fail to retrieve relevant information for certain terms.
To manage such scenarios, Golden-Retriever includes a fallback mechanism that generates a "query miss" response. This response informs the user that the system could not find the necessary information and suggests checking the spelling of the jargon or contacting the knowledge base manager to add new terms.
This step ensures that the system maintains high fidelity and does not produce incorrect or misleading answers.
Evaluation
The question-answering experiment tests the system's ability to answer domain-specific questions based on industrial documents.
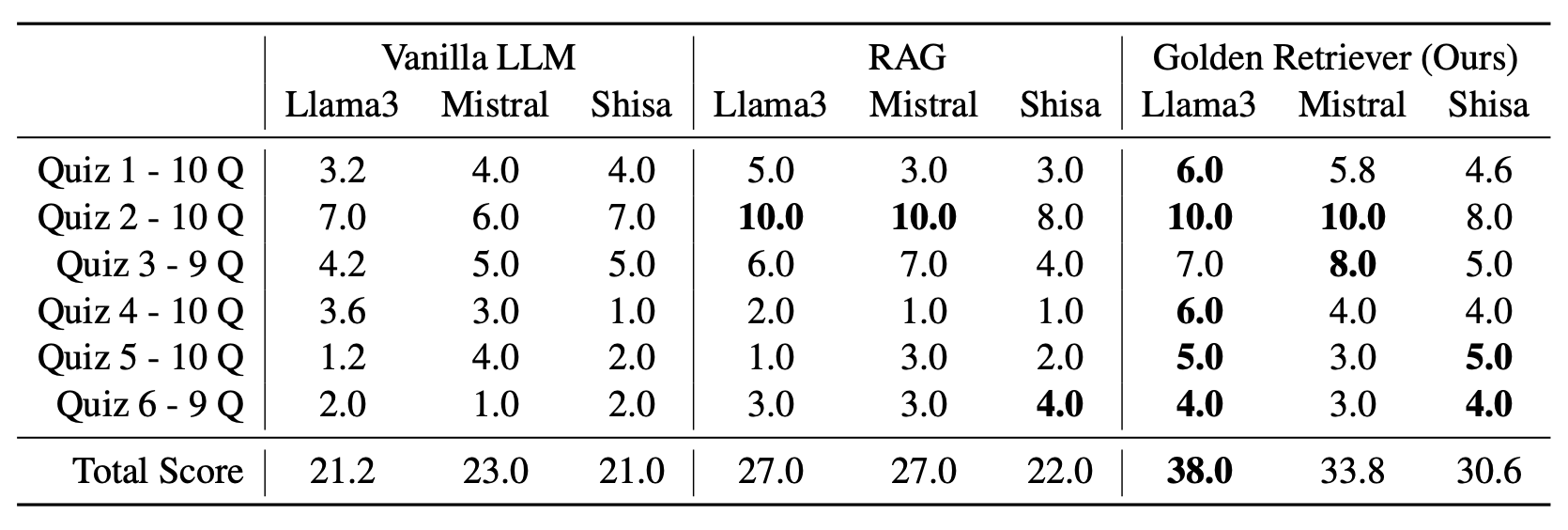
The results, as shown in Figure 4, indicate that Golden-Retriever significantly improves the total score of LLMs across multiple quizzes, outperforming both vanilla LLMs and traditional RAG methods.
Conclusion
This article explored Golden-Retriever, a high-fidelity agentic RAG system designed to enhance document retrieval accuracy in industrial knowledge bases.
Golden-Retriever represents a significant advancement in the field of RAG, particularly for industrial applications where domain-specific jargon and context are prevalent. The system's ability to augment queries before retrieval addresses a critical gap in traditional RAG methods, making it a more reliable solution for navigating complex knowledge bases.
However, the reliance on LLMs for context and jargon identification does introduce higher computational costs, which may be a consideration for large-scale deployments. Future work could explore optimizing these processes to reduce costs while maintaining accuracy.