
MultiDocFusion: From Flat Chunks to Hierarchy-Aware RAG — AI Innovations and Insights 130
For RAG, a lot of us begin with the same almost invisible premise: chunk the document, embed the chunks, retrieve the top matches, and the rest will take care of itself.
That story holds up right until a long industrial PDF arrives on your desk and makes one thing obvious: documents were never meant to be understood as confetti.
The Hidden Pitfalls of Naive RAG Chunking
Many RAG systems retrieve relevant chunks from documents and then ask an LLM to answer from that retrieved context.
However, there’s a catch: to make documents searchable, especially longer ones, they usually have to be split into smaller pieces. Traditional methods for splitting these documents can be overly simplistic, such as slicing by a fixed number of words or strictly relying on semantic meaning.
In practice, this approach often leads to problems. Real-world documents aren’t simply chunks of plain text, they often include:
Multiple levels of headings and subheadings
Tables, figures, and other layout-heavy elements
Content spanning across multiple pages
Scanned PDFs that require OCR processing
When documents are just “split by length,” it’s akin to randomly chopping up a textbook, headings end up isolated from their sections, paragraphs get separated from accompanying tables, and critical context can get lost altogether.
This fragmentation can make retrieval return disjointed evidence, which can reduce answer quality. The problem becomes especially pronounced when dealing with industrial documents, financial reports, legal contracts, and scanned materials.
Core Idea
To make RAG over long documents more faithful, three kinds of signals need to be modeled together:
Visual layout (what the document looks like)
Textual content (what the document says)
Structural hierarchy (how the document is organized)
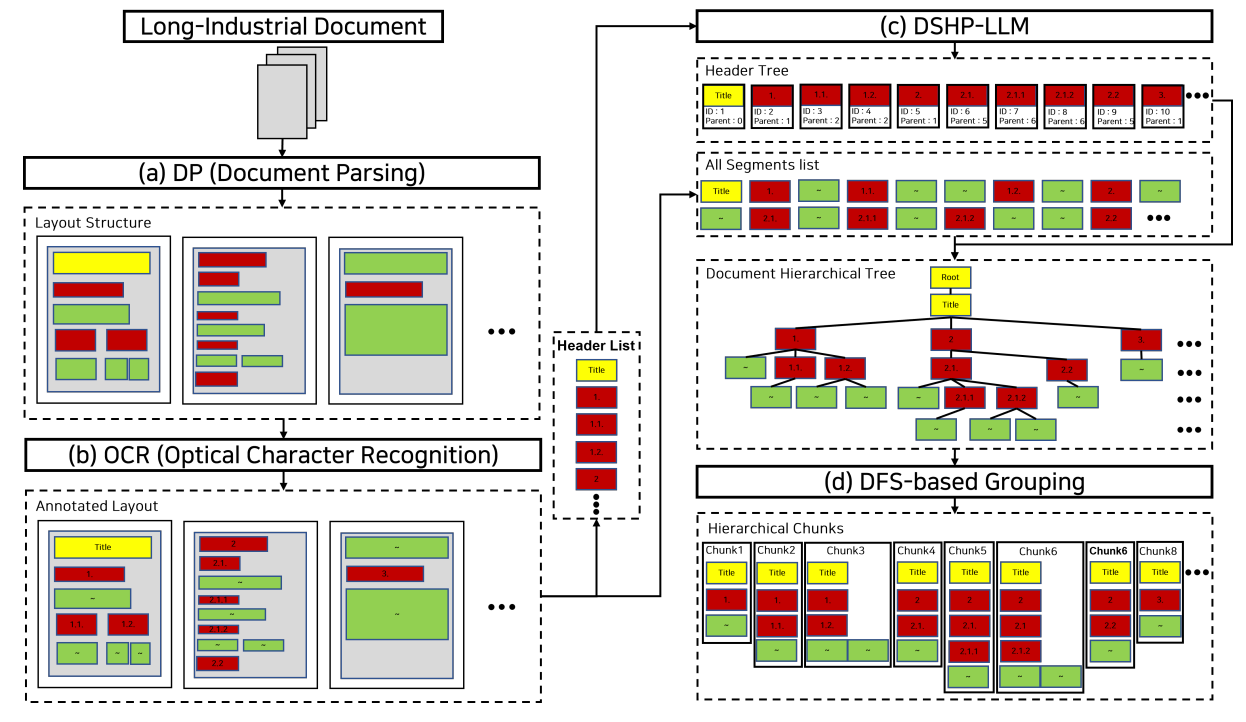
As shown in Figure 1, MultiDocFusion combines visual layout, text, and hierarchy; the name “Fusion” refers to that integration, while “MultiDoc” also reflects support for diverse document formats and corpus-level multi-document RAG scenarios.
An Intuitive Analogy
Traditional fixed-length methods are more like slicing a book at fixed token boundaries.
MultiDocFusion, on the other hand, acts like an intelligent reader: it dynamically reconstructs the document's structural tree (like building its own table of contents on the fly) and carefully groups content that naturally belongs together.
This makes it particularly effective for handling long, complex documents that reflect real-world complexities.
MultiDocFusion: How Does It Actually Work?
Think of it as a four-step process.
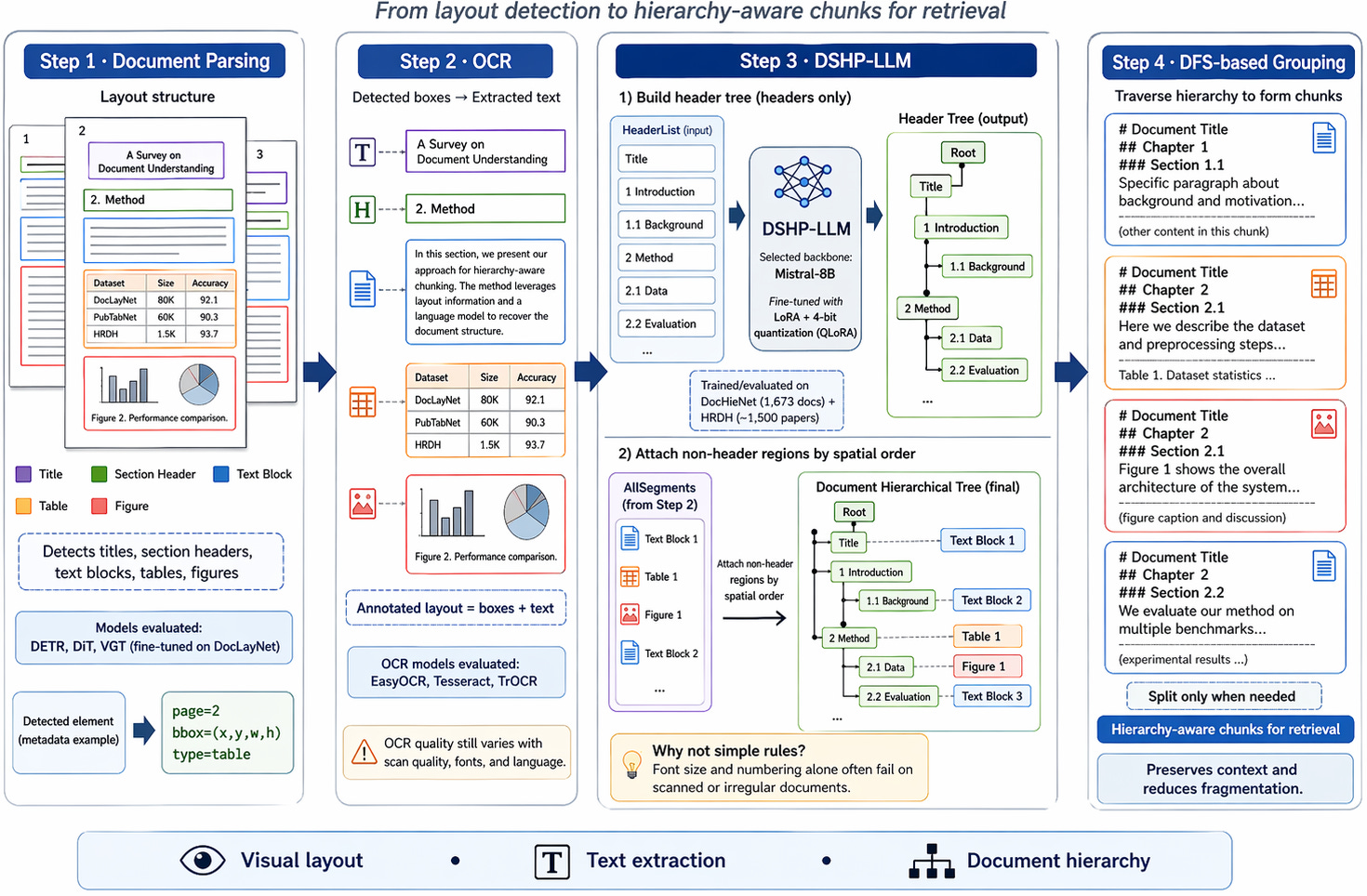
Step 1: Understanding the Document Layout (Document Parsing)
Keep reading with a 7-day free trial
Subscribe to AI Exploration Journey to keep reading this post and get 7 days of free access to the full post archives.