
MinerU-Diffusion: A New Path Beyond Autoregressive OCR — AI Innovations and Insights 131
The uncomfortable truth is that some OCR systems look smarter than they are because language helps them fill in the blanks. But when the page stops being predictable, real visual reading becomes much harder to fake.
Where Autoregressive OCR Starts to Break Down
Most existing OCR and visual language models (VLMs) rely heavily on autoregressive decoding, meaning they generate text tokens sequentially, one by one, from left to right.

While this approach works well for standard text generation tasks, it’s far from ideal for document OCR. Here’s why:
Speed Issues: Documents, especially lengthy ones filled with tables, formulas, and complex layouts, require generating many tokens. Decoding each token sequentially leads to significant latency, slowing the entire recognition process.
Error Propagation: Autoregressive methods are highly sensitive to early mistakes. A single recognition error can distort the context for subsequent tokens, causing a cascade of inaccuracies that build upon one another.
Over-Reliance on Language Priors: In Semantic Shuffle benchmark, AR models often lean heavily on linguistic cues and semantic coherence. This means they may “guess” rather than clearly perceive the actual text. When the semantic structure is disrupted or ambiguous, AR performance typically drops dramatically.
OCR as Inverse Rendering: Fundamentally, document OCR is better thought of as “inverse rendering.” The goal is to reconstruct structured information (like text, layouts, tables, and equations) from a two-dimensional image. The correct interpretation primarily depends on visual evidence and spatial arrangements. Forcing a strict left-to-right serialization is merely an "implementation artifact" for representation convenience, rather than a fundamental property of how documents are actually structured.
A Strong Fit for Diffusion: Unlike open-ended text generation (like chatting with ChatGPT), OCR is a near-deterministic task with limited semantic ambiguity. This makes OCR a strong candidate for masked diffusion, where masked tokens can be predicted in parallel conditioned on the image and partially observed sequence, producing a tunable speed–accuracy trade-off.
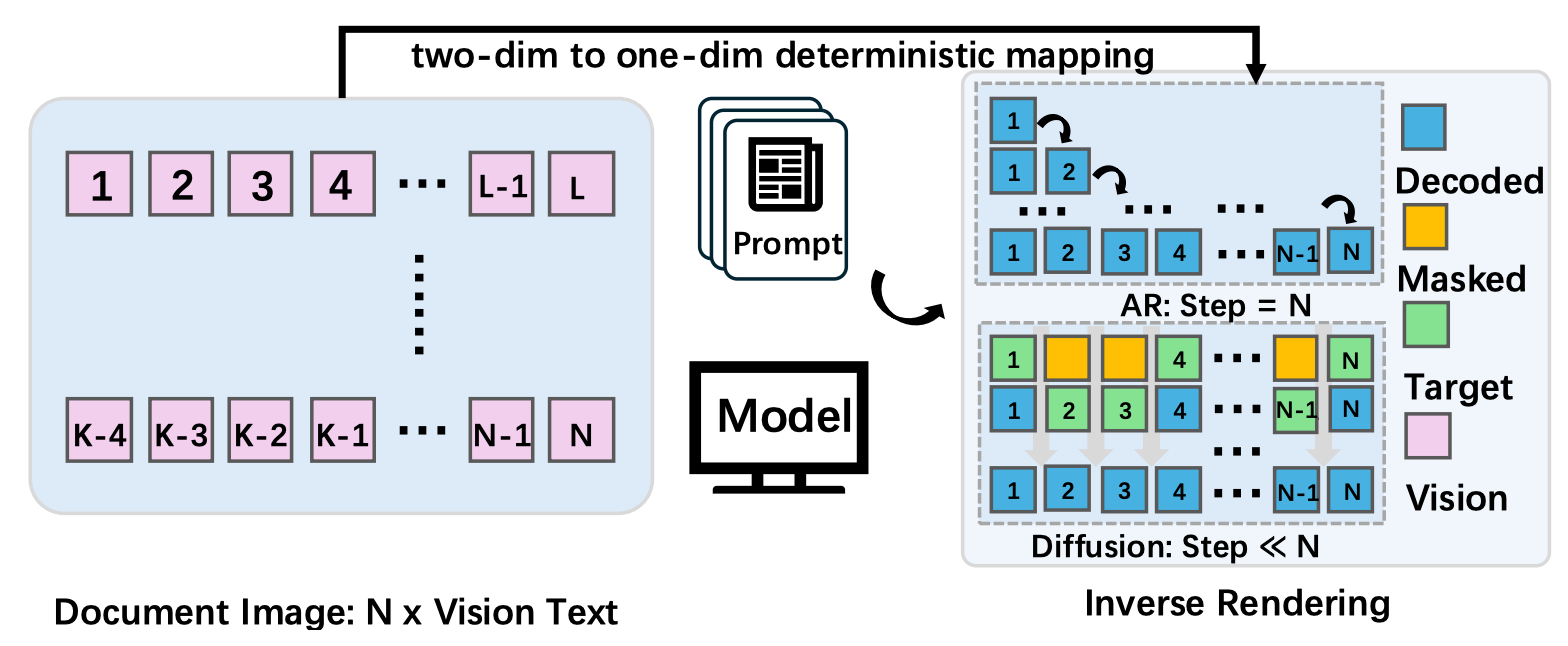
Given these considerations, document OCR systems would greatly benefit from decoding strategies that are parallelized, globally consistent, and strongly grounded in visual features. Rather than forcing OCR into the sequential patterns of autoregressive language generation, it’s more natural to employ methods designed specifically to exploit visual structure.
MinerU-Diffusion: From Left-to-Right OCR to Parallel Visual Decoding
MinerU-Diffusion uses diffusion-based decoding instead of the traditional autoregressive method, enabling the model to simultaneously confirm or correct multiple tokens through visual context. This approach boosts processing speed, reduces error propagation, and decreases reliance on linguistic context for guessing content.
The method can be understood through four practical components.
1. Unified Output Format
Text, layout annotations, table symbols, and formula indicators are all represented as a unified sequence of tokens.
For document parsing, the model outputs a structured sequence rather than only plain text; task-specific prompts can still produce plain text, LaTeX, or table markup.
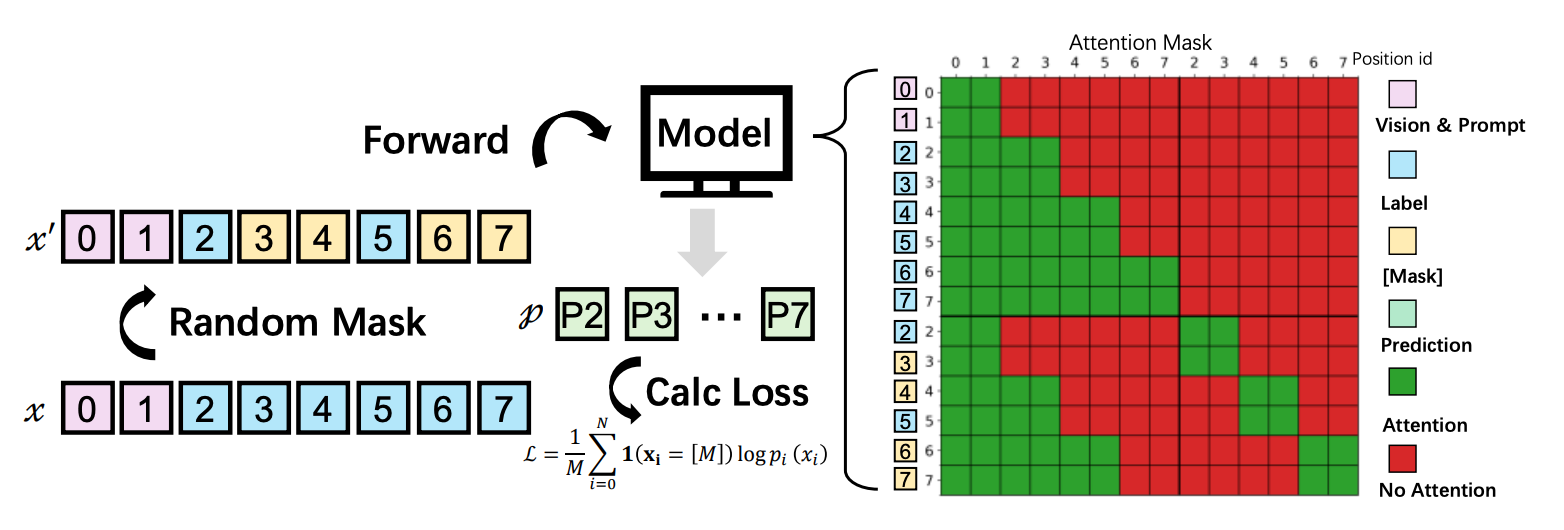
2. Diffusion-Based Decoding Replacing Autoregression
During training, tokens are randomly masked, prompting the model to predict these masked elements based on the surrounding context and visual evidence from the document image.
At inference, the model progressively reconstructs masked positions, using already decoded context and visual features rather than generating strictly left to right. Over multiple iterative rounds, uncertain tokens are progressively revealed and corrected rather than sequentially generating each token from left to right.
3. Block-wise Diffusion
Diffusing across an entire document sequence can be slow and unstable, so sequences are divided into smaller blocks:
Within blocks: Diffusion is parallelized, and context is considered bidirectionally.
Between blocks: A coarse, front-to-back dependency helps preserve sequence coherence and reduce long-range drift.
System Efficiency: The causal (front-to-back) structure across blocks naturally enables efficient KV-caching during inference, reducing memory and computation costs compared to full-attention diffusion models.
This design maintains fast parallel decoding while mitigating position drift and error accumulation common in lengthy documents.
4. Confidence-Driven Dynamic Decoding + Two-Stage Training
During inference, tokens with high confidence are confirmed first, while low-confidence tokens undergo further iterative correction. Confidence thresholds balance decoding speed and accuracy.
After multimodal initialization, training happens in two stages: initial broad-scale training provides general capabilities, followed by an uncertainty-driven refinement. The model automatically mines challenging examples (like complex tables or ambiguous boundaries) by measuring its own inference consistency, focusing its learning on the hardest cases to enhance robustness.
In short, MinerU-Diffusion treats document OCR as the inverse problem of reconstructing structured text from images, leveraging block-wise diffusion to parallelly refine tokens, and employing confidence-driven scheduling and challenging-case training to boost decoding speed, stability, and reliability.
Evaluation
Document Parsing Evaluation
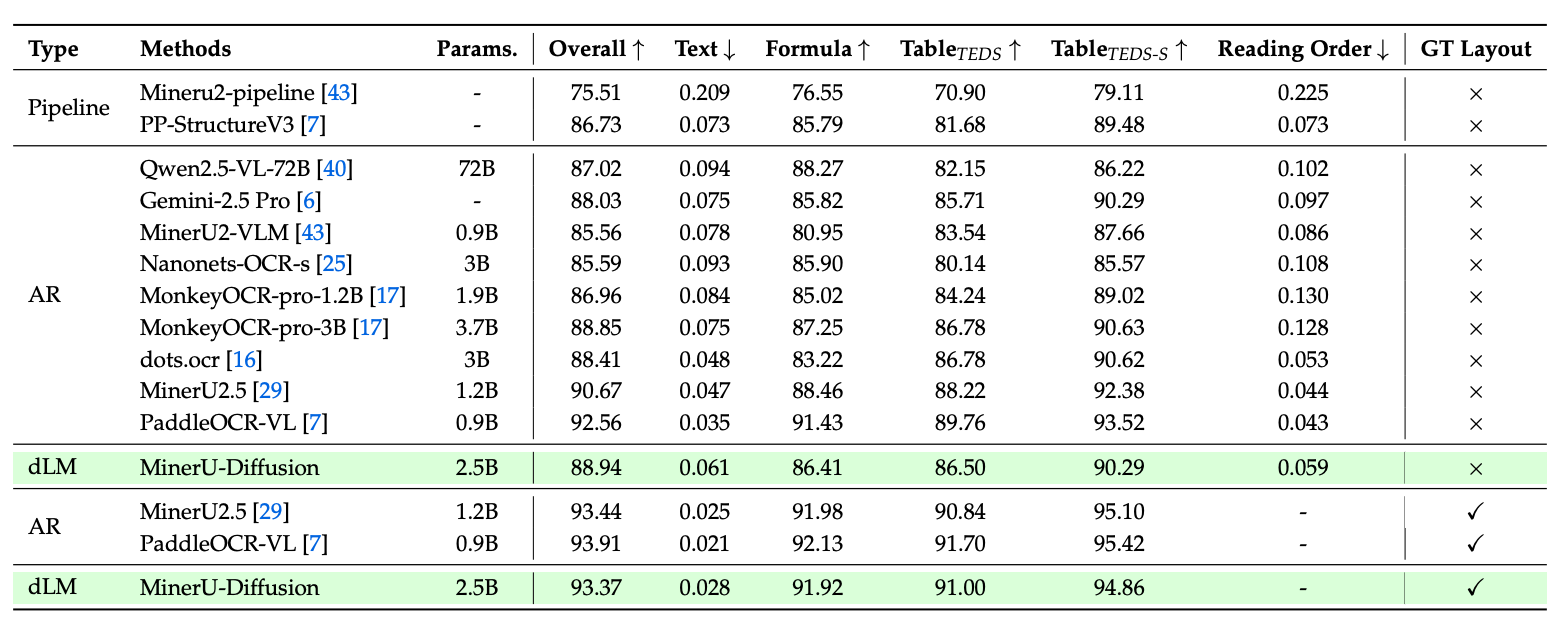
MinerU-Diffusion’s capability in full-page document parsing is evaluated using OmniDocBench v1.5, measuring its performance through various metrics such as text edit distance, formula correctness (CDM), table extraction quality (TEDS), and reading order.
The results showed that MinerU-Diffusion achieved an overall score of 88.94 without using ground-truth layouts. When provided with ground-truth layouts, the score improved significantly to 93.37, coming very close to the performance of strong autoregressive OCR systems. This mainly shows that once layout errors are removed, its recognition quality is highly competitive.
Efficiency Evaluation
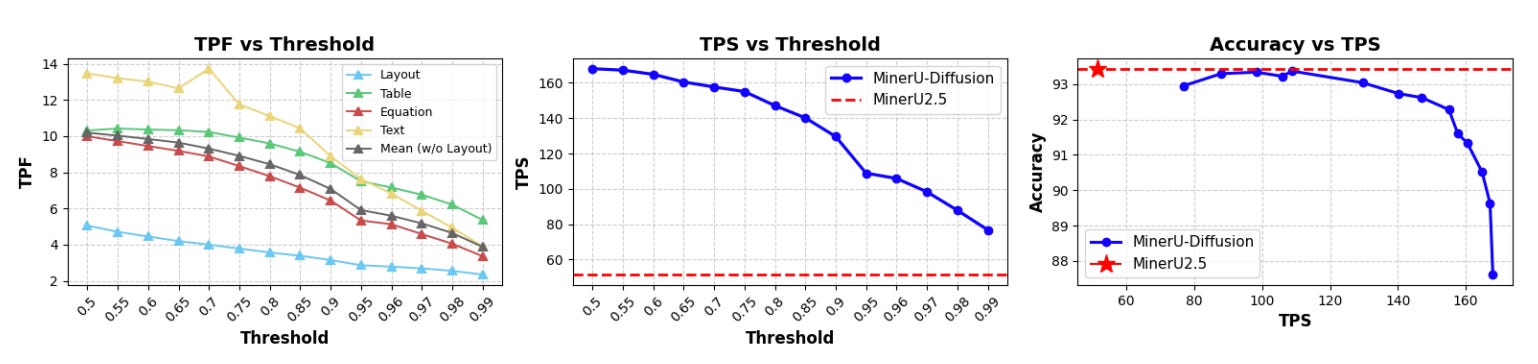
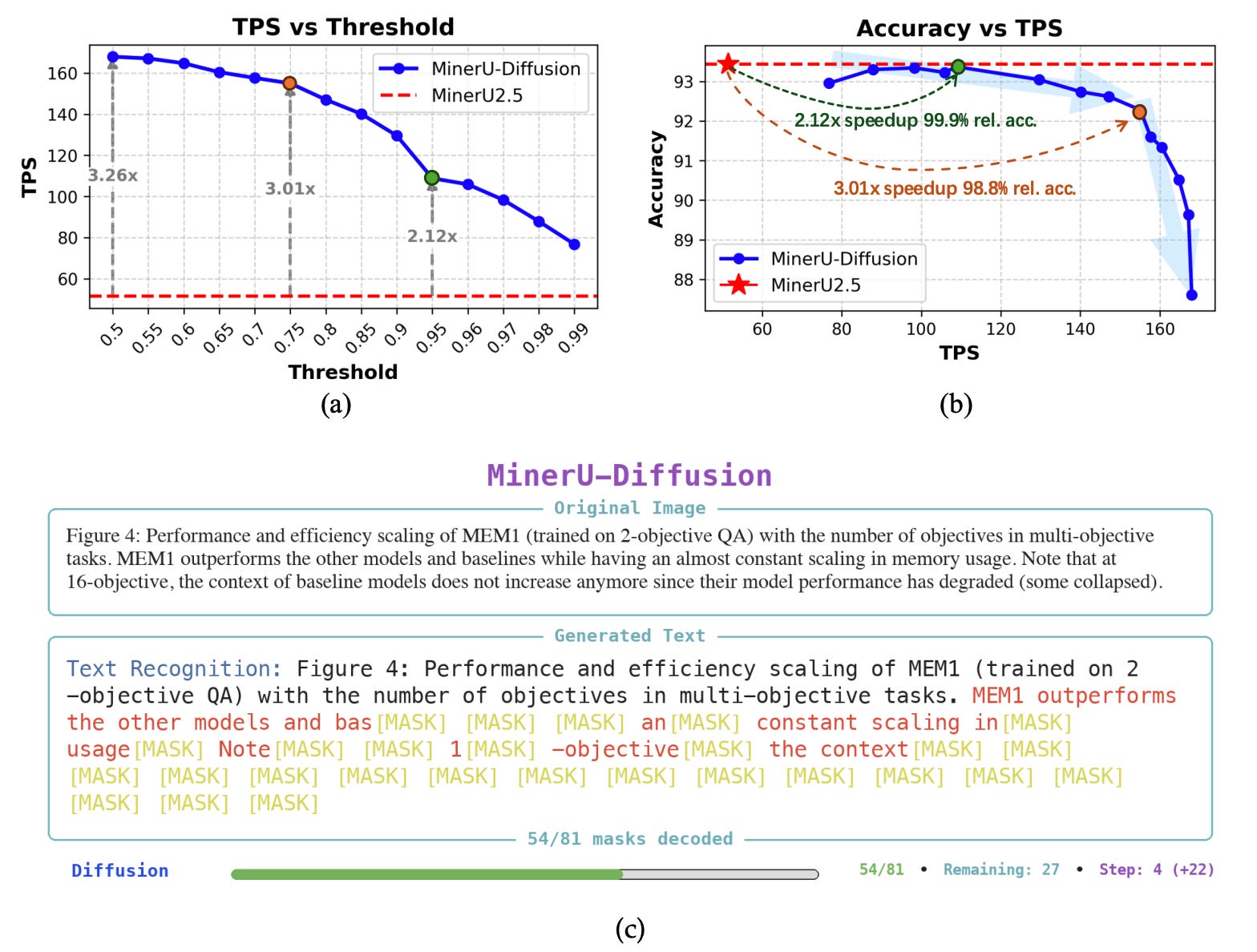
Efficiency was tested by adjusting the confidence thresholds, which determine how many tokens the model finalizes in a single decoding step. Lower thresholds led to faster decoding speeds, while higher thresholds improved stability.
MinerU-Diffusion achieved up to a 3.2× decoding speedup, maintaining a clear advantage in speed even at high accuracy levels.
Thoughts
At its core, MinerU-Diffusion transforms OCR decoding from sequential token-by-token generation into a visually-driven, block-wise diffusion process: tokens are refined in parallel within each block, while blocks retain a coarse front-to-back dependency.
Coupled with uncertainty-driven curriculum training, this shift represents a fundamental change at the decoding paradigm level, not merely swapping out the underlying model backbone.
But I have a concern.
Block boundaries could introduce new sources of subtle errors. While MinerU-Diffusion mitigates this by allowing tokens to causally attend to preceding blocks, they are strictly cut off from future blocks. Structures like headers, footers, table cells, or formulas spanning line breaks might still be disrupted if they fall near these boundaries. Such systemic fragmentation might not clearly surface through averaged evaluation metrics.
Reference: