
Let AI Instantly Parse Heavy Documents: The Magic of MPLUG-DOCOWL2's Efficient Compression

Today, let's take a look at one of the latest developments in PDF Parsing and Document Intelligence.
In our digital age, the ability to understand documents beyond mere text extraction is crucial. Multi-page documents, such as legal contracts, scientific papers, and technical manuals, present unique challenges.
Traditional document understanding methods heavily rely on Optical Character Recognition (OCR) techniques, which present a significant challenge: the inefficiency and sluggish performance of current OCR-based solutions when processing high-resolution, multi-page documents.
These methods generate thousands of visual tokens for just a single page, leading to high computational costs and prolonged inference times. For example, InternVL 2 requires an average of 3,000 visual tokens to understand a single page, resulting in slow processing speeds.

As shown in Figure 1, a new study called MPLUG-DOCOWL2 (open-source code) aims to address this issue by drastically reducing the number of visual tokens while maintaining, or even enhancing, comprehension accuracy.
A real-world analogy would be a person scanning a legal contract: instead of trying to read every single word on each page, the ideal approach would be to compress the content into a summarized, meaningful format. MPLUG-DOCOWL2 does precisely this by focusing on summarizing the document image's key visual elements.
MPLUG-DOCOWL2

MPLUG-DOCOWL2 introduces a high-resolution document compressor that efficiently reduces visual tokens while preserving essential layout and text information.
As shown in Figure 2(c), by compressing each document image into 324 visual tokens, the system drastically cuts down processing times without sacrificing performance. This architecture supports multi-page comprehension and explanation with evidence-based reasoning.

MPLUG-DOCOWL2’s workflow consists of three major components:
Shape-Adaptive Cropping Module: It cuts high-resolution images into smaller, manageable sub-images based on layout information. This ensures the structure of the document remains intact while enabling more efficient processing.
High-Resolution DocCompressor: The core innovation compresses these cropped sub-images into fewer tokens using cross-attention between global and local visual features. By doing this after aligning with text features through the Vision-to-Text (V2T) module, the system retains both the document's visual layout and textual semantics.
Multi-image Modeling: The compressed tokens from multiple pages are combined with text instructions and passed to a Large Language Model (LLM) for comprehensive understanding and question answering.
Comparison with Other Solutions
The paper mentions and compares several other models. Below are some of the models referenced.

Through these comparisons, it demonstrates the clear advantage of MPLUG-DOCOWL2 in handling multi-page document understanding tasks, with superior visual token efficiency and faster inference speeds compared to existing models.
Evaluation

As shown in Figure 5, compared to previous solutions, such as TokenPacker and TextMonkey, which also aim to reduce tokens, MPLUG-DOCOWL2 stands out by leveraging global visual features as a compressing guide. This layout-aware approach ensures that relevant visual and textual information is preserved.

As shown in Figure 6, on DocVQA, MPLUG-DOCOWL2 achieves an ANLS score of 80.7, which is competitive with the best-performing models, all while using far fewer visual tokens. This means that MPLUG-DOCOWL2 provides fast and accurate document comprehension.
Furthermore, the First Token Latency (FTL), a measure of the time to generate the first response token, is significantly lower for MPLUG-DOCOWL2 (0.26 seconds), cutting latency by more than 50% compared to prior models. This highlights the system's efficiency in real-time applications.
Case Study: Multi-Image Question Answering
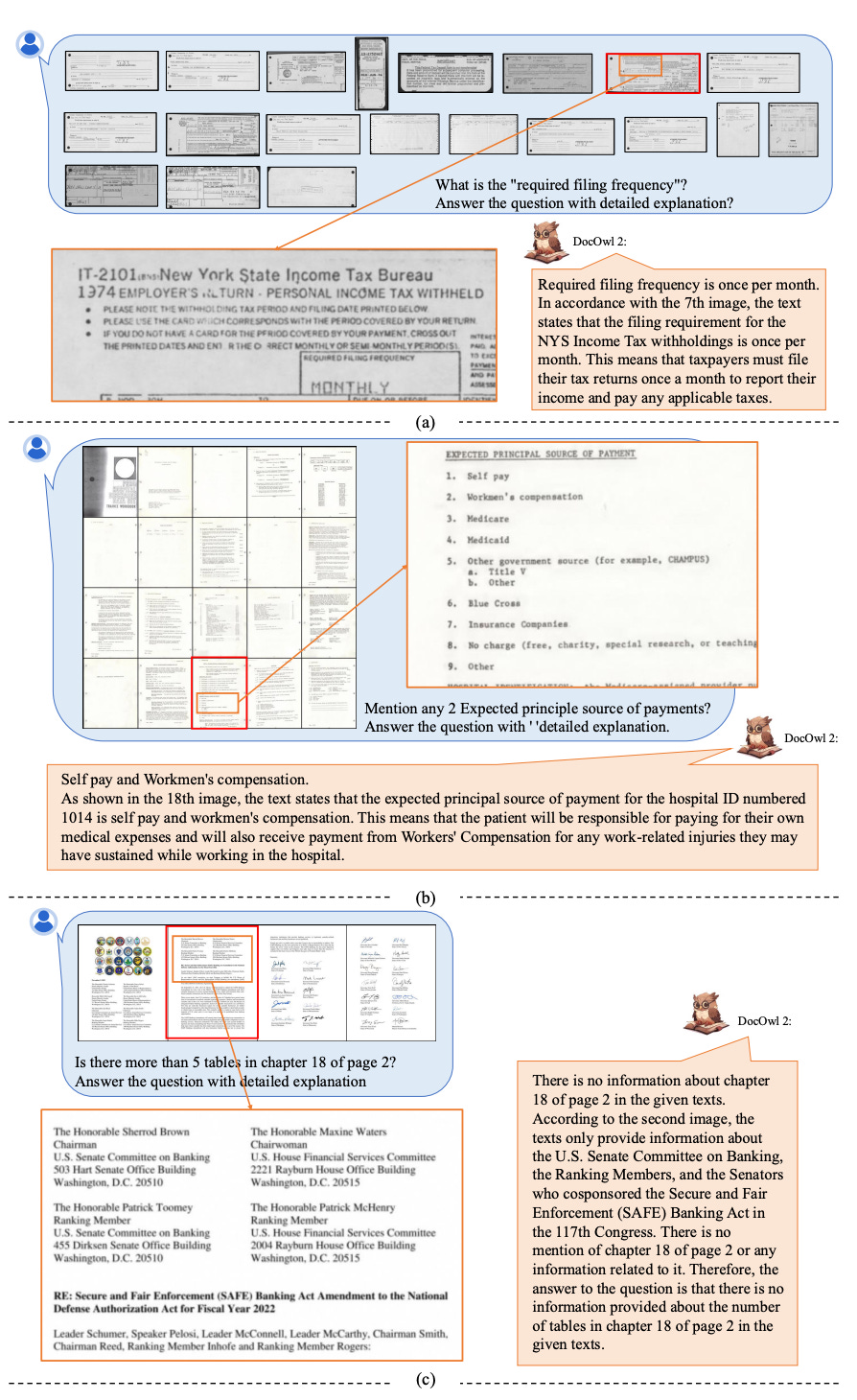
As shown in Figure 7(a-b), MPLUG-DOCOWL2 not only provides a simple answer to the question but also delivers a detailed explanation, complete with page references to the evidence supporting its answer.
Additionally, as shown in Figure 7(c), the model can also identify when a question is unanswerable due to missing information. For instance, when asked about a chapter in a page where the relevant content wasn’t available, MPLUG-DOCOWL2 provided a clear response indicating the lack of data, demonstrating its robustness in handling real-world scenarios.
Conclusion and Insights
This article explored MPLUG-DOCOWL2, an innovative solution for high-resolution, multi-page document understanding that excels in efficiency and accuracy. By leveraging layout-aware compression, MPLUG-DOCOWL2 ensures that visually situated text information is retained, offering a scalable solution for large-scale document analysis.
What I found particularly enlightening is how token efficiency does not necessarily equate to performance reduction. By compressing visual features smartly, MPLUG-DOCOWL2 achieves remarkable results without the bloat typically seen in multi-page document models. However, the challenges of real-world deployment, such as handling diverse document layouts and noisy data, still need further refinement.