
Introduction to Suffix Array
Suffix array is a powerful data structure for solving string problems, which has applications in many fields.

Suffix array is a powerful data structure for solving string problems, which has applications in full-text indexing, data compression, and bioinformatics.
Many string-related problems on platforms such as Leetcode and Codeforces can be solved using suffix arrays.
Definition
String
String s of length n, with indices starting from 1:

I-th suffix
The i-th suffix of string s is the string composed of characters from index i to n:

String comparison
Starting from the first position, compare characters one by one according to their ASCII codes. If there is a position where the characters are not the same, the string with the smaller ASCII code character at that position is considered smaller. If one string has been compared completely and the other has not, the former (with the smaller length) is considered smaller. If two strings have the same length and all characters at each position are the same, then they are considered equal.
For example: abc > aba, abc > ab, c > abcdefg
Note that two suffixes of the same string cannot be equal, because they cannot satisfy the necessary condition of having the same length.
Suffix Array
The suffix array sa is an integer array that corresponds to the sorted order of all suffixes of a string in ascending order according to lexicographical order (using ASCII values).
The suffix array (Suffix Array) mainly involves two arrays: sa and rk. Where:
sa[i]represents the index of the suffix rankediafter sorting all suffixes, which is also referred to as the suffix arraysa;rk[i]represents the rank of i-th suffix, which is an important auxiliary array, also known as the rank arrayrk.
In simple terms, the sa array is “who is ranked at which position?” and the rk array is “what is your rank?”. It is easy to see that the suffix array and the rank array are inverse operations of each other.
These two arrays satisfy the following properties:

For example: String s = “abaab” has 5 suffixes, which are:
1 abaab
2 baab
3 aab
4 ab
5 bAfter sorting, the sa array is:
sa[1] = 3 aab
sa[2] = 4 ab
sa[3] = 1 abaab
sa[4] = 5 b
sa[5] = 2 baabHow to generate a suffix array
O(n² log n) Algorithm
The easiest algorithm to think of is the O(n² log n) algorithm, which is to put all the suffixes of the string into an array, and directly sort all the suffixes using O(n log n) quicksort or mergesort.
Since directly comparing between suffixes is O(n), the time complexity is O(n² log n).
The code is simple, omitted here.
O(n log² n) Algorithm
Since directly comparing the suffixes is O(n), which is time-consuming, is there a way to reduce the time complexity of comparing suffixes?
It requires the use of the binary lifting and double-key sorting. For example,
When the length is
1, the keys are the first and second characters of each suffix.When the length is
2, the keys are the first and third characters of each suffix.…
When the length is
k, the keys are the first and1 + 2^{k−1}characters of each suffix.
Each time the length between two keys is doubled, the sorting is completed at most when the length becomes ⌊n / 2⌋.
Using the example s = “abaab” from earlier, as shown in Figure 1, its suffixes are sorted in lexicographic order based on their first character as follows:

It can be noticed that there are many repeated rankings, therefore setting double keys with a length of 1 between them:

Then update the ranking and find that there are still duplicates, therefore, set the length between the two keys to 2 and continue sorting:
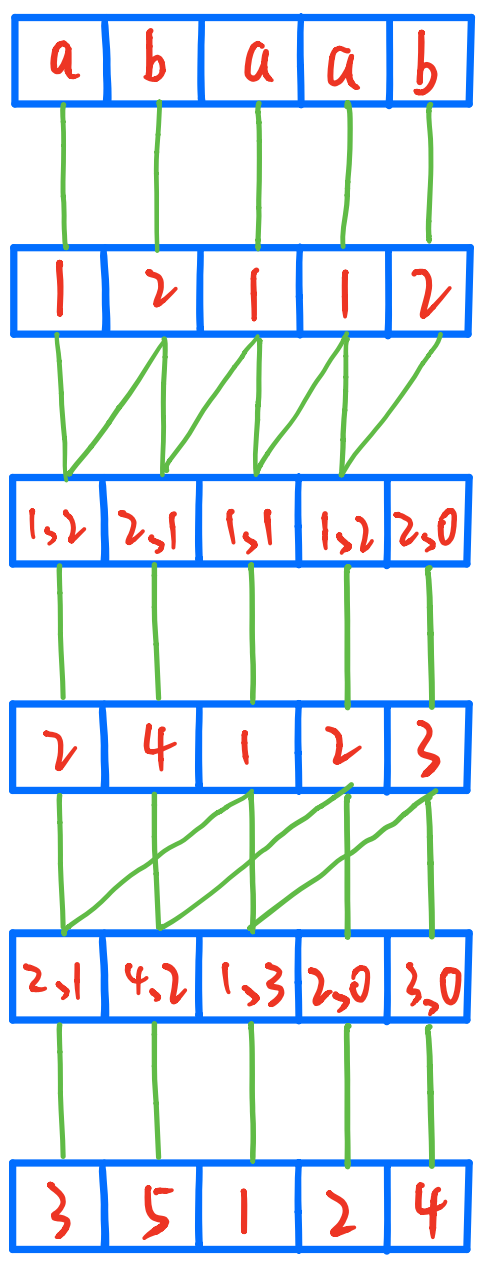
After updating the ranking, it was found that there were no duplicate rankings, and the sorting ended.
Code as follows:
#include <bits/stdc++.h>
using namespace std;
const int N = 1e6 + 9;
char s[N];
// To prevent accessing rk[i+d] from causing array out of bounds,
// double the space when declaring.
int n, d, sa[N], rk[N << 1], old_rk[N << 1];
int main()
{
scanf("%s", s + 1);
n = strlen(s + 1);
for (int i = 1; i <= n; ++i)
sa[i] = i, rk[i] = s[i];
for (d = 1; d < n; d <<= 1)
{
// sort two keys using C++ lambda function
sort(sa + 1, sa + n + 1, [](int x, int y)
{ return rk[x] == rk[y] ? rk[x + d] < rk[y + d] : rk[x] < rk[y]; });
memcpy(old_rk, rk, sizeof(rk));
// The purpose of this loop is to update the ranking.
for (int rank = 0, i = 1; i <= n; ++i)
{
if (old_rk[sa[i]] == old_rk[sa[i - 1]] &&
old_rk[sa[i] + d] == old_rk[sa[i - 1] + d])
rk[sa[i]] = rank;
else
rk[sa[i]] = ++rank;
}
}
for (int i = 1; i <= n; ++i)
printf("%d ", sa[i]);
return 0;
}This can reduce the time complexity of comparing suffixes to O(log n), while sorting substrings using sort is O(n log n). Therefore, the time complexity optimized by binary lifting is O(n log² n).
Note that after updating the code rankings, the sorting will continue without stopping if there are no duplicate rankings found. This feature will be added to the final code.
O(n log n) Algorithm
Notice that the length of English character set is limited, and the maximum ASCII value of all numbers and letters, including ‘z’, is only 122.
Therefore, we can replace the O(n log n) quicksort or mergesort with O(n) radix sort, combined with binary lifting and double-key sorting, so the total complexity of suffix sorting can be reduced to O(n log n).
How to quickly understand radix sort?
Radix sort is a multi-key sorting algorithm. For each keyword, a suitable method (usually counting sort) is used to ensure stability after sorting, and then the next keyword is sorted.
The basic steps of counting sort are as follows:
Firstly, clear the
cntarray.From 1 to n, increment
cnt[…].Then calculate the prefix sum of
cntto determine the rank of each element.Finally, update the
saarray by iterating from n to 1 in reverse order.
Radix sort in suffix sorting is essentially sorting a pair of elements (old_sa[i], old_sa[i]+d). It actually performs two counting sorts.
Code as follows:
#include <bits/stdc++.h>
using namespace std;
const int N = 1e6 + 7;
char s[N];
int n, sa[N], rk[N << 1], old_rk[N << 1], old_sa[N], cnt[N];
int main()
{
int m = 127;
scanf("%s", s + 1);
n = strlen(s + 1);
// Counting sort of the original array begins
for (int i = 1; i <= n; ++i)
++cnt[rk[i] = s[i]]; // rk[i], Index: Ranking
for (int i = 1; i <= m; ++i)
cnt[i] += cnt[i - 1];
for (int i = n; i >= 1; --i)
sa[cnt[rk[i]]--] = i; // sa[i], Ranking: Index
for (int d = 1; d < n; d <<= 1, m = n)
{
// Start counting sort on the second key: old_sa[i] + d
memset(cnt, 0, sizeof(cnt));
memcpy(old_sa + 1, sa + 1, n * sizeof(int));
for (int i = 1; i <= n; ++i)
++cnt[rk[old_sa[i] + d]];
for (int i = 1; i <= m; ++i)
cnt[i] += cnt[i - 1];
for (int i = n; i >= 1; --i)
sa[cnt[rk[old_sa[i] + d]]--] = old_sa[i];
// Start counting sort on the first key: old_sa[i]
memset(cnt, 0, sizeof(cnt));
memcpy(old_sa + 1, sa + 1, n * sizeof(int));
for (int i = 1; i <= n; ++i)
++cnt[rk[old_sa[i]]];
for (int i = 1; i <= m; ++i)
cnt[i] += cnt[i - 1];
for (int i = n; i >= 1; --i)
sa[cnt[rk[old_sa[i]]]--] = old_sa[i];
// Start updating rankings
memcpy(old_rk + 1, rk + 1, n * sizeof(int));
for (int rank = 0, i = 1; i <= n; ++i)
{
if (old_rk[sa[i]] == old_rk[sa[i - 1]] &&
old_rk[sa[i] + d] == old_rk[sa[i - 1] + d])
rk[sa[i]] = rank;
else
rk[sa[i]] = ++rank;
}
}
for (int i = 1; i <= n; ++i)
printf("%d ", sa[i]);
return 0;
}Optimization
The second key does not require counting sort. Think about the essence of sorting the second keyword, which is actually to move the sa[i] that exceeds the string range (i.e. sa[i] + d > n) to the beginning of the sa array, and then put the rest in the original order:
// Optimized sort on the second key
int rank = 0;
memcpy(old_sa + 1, sa + 1, n * sizeof(int));
for (int i = n - d + 1; i <= n; i++)
sa[++rank] = i;
for (int i = 1; i <= n; i++)
if (old_sa[i] > d)
sa[++rank] = old_sa[i] - d;As mentioned earlier, if the rankings are not the same, the suffix array can be generated directly without further sorting:
if (rank == n)
break;Here is the optimized code:
#include <bits/stdc++.h>
using namespace std;
const int N = 1e6 + 7;
char s[N];
int n, sa[N], rk[N << 1], old_rk[N << 1], old_sa[N], cnt[N];
int main()
{
int m = 127;
scanf("%s", s + 1);
n = strlen(s + 1);
// Counting sort of the original array begins
for (int i = 1; i <= n; ++i)
++cnt[rk[i] = s[i]];
for (int i = 1; i <= m; ++i)
cnt[i] += cnt[i - 1];
for (int i = n; i >= 1; --i)
sa[cnt[rk[i]]--] = i;
for (int d = 1; d < n; d <<= 1, m = n)
{
// Start counting sort on the second key: old_sa[i] + d
// memset(cnt, 0, sizeof(cnt));
// memcpy(old_sa + 1, sa + 1, n * sizeof(int));
// for (int i = 1; i <= n; ++i)
// ++cnt[rk[old_sa[i] + d]];
// for (int i = 1; i <= m; ++i)
// cnt[i] += cnt[i - 1];
// for (int i = n; i >= 1; --i)
// sa[cnt[rk[old_sa[i] + d]]--] = old_sa[i];
// Optimized sort on the second key
int rank = 0;
memcpy(old_sa + 1, sa + 1, n * sizeof(int));
for (int i = n - d + 1; i <= n; i++)
sa[++rank] = i;
for (int i = 1; i <= n; i++)
if (old_sa[i] > d)
sa[++rank] = old_sa[i] - d;
// Start counting sort on the first key: old_sa[i]
memset(cnt, 0, sizeof(cnt));
memcpy(old_sa + 1, sa + 1, n * sizeof(int));
for (int i = 1; i <= n; ++i)
++cnt[rk[old_sa[i]]];
for (int i = 1; i <= m; ++i)
cnt[i] += cnt[i - 1];
for (int i = n; i >= 1; --i)
sa[cnt[rk[old_sa[i]]]--] = old_sa[i];
// Start updating rankings
memcpy(old_rk + 1, rk + 1, n * sizeof(int));
rank = 0;
for (int i = 1; i <= n; ++i)
{
if (old_rk[sa[i]] == old_rk[sa[i - 1]] &&
old_rk[sa[i] + d] == old_rk[sa[i - 1] + d])
rk[sa[i]] = rank;
else
rk[sa[i]] = ++rank;
}
if (rank == n)
break;
}
for (int i = 1; i <= n; ++i)
printf("%d ", sa[i]);
return 0;
}Longest Common Prefix array(LCP array)
So far, we have learned how to calculate suffix arrays in O(n log n), which is a huge improvement.
However, when we enthusiastically start solving problems, we will find ourself confused because many of the suffix array related problems require constructing the LCP array.
In computer science, the longest common prefix array (LCP array) is an auxiliary data structure to the suffix array. It stores the lengths of the longest common prefixes (LCPs) between all pairs of consecutive suffixes in a sorted suffix array.
Definition: lcp[i], which means the length of the longest common prefix between the suffix ranked i and the suffix ranked i-1, lcp[1] can be considered as 0.
Continuing with the example from the beginning of the article:
sa[1] = 3: aab
sa[2] = 4: ab
sa[3] = 1: abaab
sa[4] = 5: b
sa[5] = 2: baabFor example, if sa is a suffix array of “abaab”, the longest common prefix between sa[1] = aab and sa[2] = ab is ‘a’ which has length 1, so lcp[2] = 1. Likewise, the LCP of sa[2] = ab and sa[3] = abaab is ‘ab’, so lcp[3] = 2.
The proof corresponding to constructing LCP array is relatively complicated, and this article will not explain it further. Interested readers can refer to Wikipedia: LCP array, which provides various construction methods and corresponding papers.
Here is the code for the O(n) method:
void get_lcp()
{
int k = 0;
for (int i = 1; i <= n; i++)
rk[sa[i]] = i;
for(int i = 1; i <= n; i++)
{
if (rk[i] == 1)
continue;
if (k)
k--;
int j = sa[rk[i] - 1];
while (i + k <= n && j + k <= n && s[i + k] == s[j + k])
k++;
lcp[rk[i]] = k;
}
}Template problem
LeetCode 1044. Longest Duplicate Substring
Problem Description: Given a string, find the longest substring that appears at least twice.
This problem is a template problem for suffix arrays.
It is equivalent to finding longest common prefix between any two suffixes of the given string. The longest common prefix between two adjacent suffixes will always be the longest.
Therefore, we can first find the lcp (longest common prefix) array and then find the maximum value in it which corresponds to the suffix and its length will be the answer.
Code:
#include <bits/stdc++.h>
using namespace std;
const int N = 1e6 + 7;
char s[N];
int n, sa[N], lcp[N], rk[N << 1], old_rk[N << 1], old_sa[N], cnt[N];
void get_sa()
{
int m = 127;
// Counting sort of the original array begins
memset(cnt, 0, sizeof(cnt));
for (int i = 1; i <= n; ++i)
++cnt[rk[i] = s[i]];
for (int i = 1; i <= m; ++i)
cnt[i] += cnt[i - 1];
for (int i = n; i >= 1; --i)
sa[cnt[rk[i]]--] = i;
for (int d = 1; d < n; d <<= 1, m = n)
{
// Optimized sort on the second key
int rank = 0;
memcpy(old_sa + 1, sa + 1, n * sizeof(int));
for (int i = n - d + 1; i <= n; i++)
sa[++rank] = i;
for (int i = 1; i <= n; i++)
if (old_sa[i] > d)
sa[++rank] = old_sa[i] - d;
// Start counting sort on the first key: old_sa[i]
memset(cnt, 0, sizeof(cnt));
memcpy(old_sa + 1, sa + 1, n * sizeof(int));
for (int i = 1; i <= n; ++i)
++cnt[rk[old_sa[i]]];
for (int i = 1; i <= m; ++i)
cnt[i] += cnt[i - 1];
for (int i = n; i >= 1; --i)
sa[cnt[rk[old_sa[i]]]--] = old_sa[i];
// Start updating rankings
memcpy(old_rk + 1, rk + 1, n * sizeof(int));
rank = 0;
for (int i = 1; i <= n; ++i)
{
if (old_rk[sa[i]] == old_rk[sa[i - 1]] &&
old_rk[sa[i] + d] == old_rk[sa[i - 1] + d])
rk[sa[i]] = rank;
else
rk[sa[i]] = ++rank;
}
if (rank == n)
break;
}
}
void get_lcp()
{
int k = 0;
for (int i = 1; i <= n; i++)
rk[sa[i]] = i;
for(int i = 1; i <= n; i++)
{
if (rk[i] == 1)
continue;
if (k)
k--;
int j = sa[rk[i] - 1];
while (i + k <= n && j + k <= n && s[i + k] == s[j + k])
k++;
lcp[rk[i]] = k;
}
}
class Solution {
public:
string longestDupSubstring(string ss) {
n = (int)ss.size();
for(int i = 1; i <= n; i++)
s[i] = ss[i-1];
get_sa();
get_lcp();
// find longest common prefix between two adjacent suffixes
int mx = 0;
for(int i = 1; i <= n; i++)
if (lcp[i] > lcp[mx])
mx = i;
string res;
for(int i = sa[mx]; i <= sa[mx] + lcp[mx] - 1; i++)
res += s[i];
return res;
}
};Conclusion
Suffix array is a powerful tool for processing string problems.
This article introduces various methods for constructing suffix arrays under different time complexities, as well as methods for finding LCP arrays. A typical example problem is also provided.
For regular problems, O(n log n) suffix array construction is sufficient. However, for some problems with strict time limits, or if you want to pursue shorter time, it is necessary to learn the O(n) suffix array construction methods, such as SA-IS and DC3. Maybe they will be explained in the future.
Finally, if there are any omissions or errors in this article, please kindly advise me. Thank you.
References
Introduction to Algorithms (Third Edition): chapter 8(Counting sort, Radix sort)
https://en.wikipedia.org/wiki/Suffix_array
https://en.wikipedia.org/wiki/LCP_array