
Hybrid OCR-LLM: Not a Bigger Model, but a Smarter Pipeline — AI Innovations and Insights 84

Have you ever encountered documents like forms, certificates, or reports during document parsing?
Today’s article offers some ideas and insights.
Why Are Copy-Heavy Documents Still Stuck in the Slow Lane?
Let’s start with a quick definition. When we say “copy-heavy” documents, we’re talking about things like insurance policies, government forms, financial statements, and ID records. These documents aren’t tricky because they vary a lot in meaning. The challenge is that they’re highly repetitive, structurally rigid, and processed in bulk.

So what’s the bottleneck?
Most general-purpose LLMs generate text token by token. That’s fine for writing stories or answering questions. But when the task is to extract large chunks of structured information that could be copied almost directly, this method becomes painfully inefficient. It’s slow, expensive, and ironically, introduces unnecessary errors into something that should be deterministic.
Now layer on real-world constraints: business workflows often demand sub-second latency and near-zero error rates. In a production pipeline, even tiny mistakes ripple into big problems.
Here’s the bottom line: instead of trying to make one model do everything, we should treat document structure as a performance asset. When documents look alike, that similarity isn’t a limitation — it’s an opportunity. By recognizing and using structural patterns, we can design smarter, faster systems that don’t waste time reinventing the wheel for every page.
Introducing Hybrid OCR-LLM: Two-Stage, Three-Mode Extraction
To address this, a hybrid framework is proposed that cleanly separates two core steps in document intelligence: reading and understanding.
The idea is simple. First, focus on getting clean, structured text out of a document. Then, focus on making sense of it. Each step uses tools best suited to the job, instead of forcing one model to do everything.
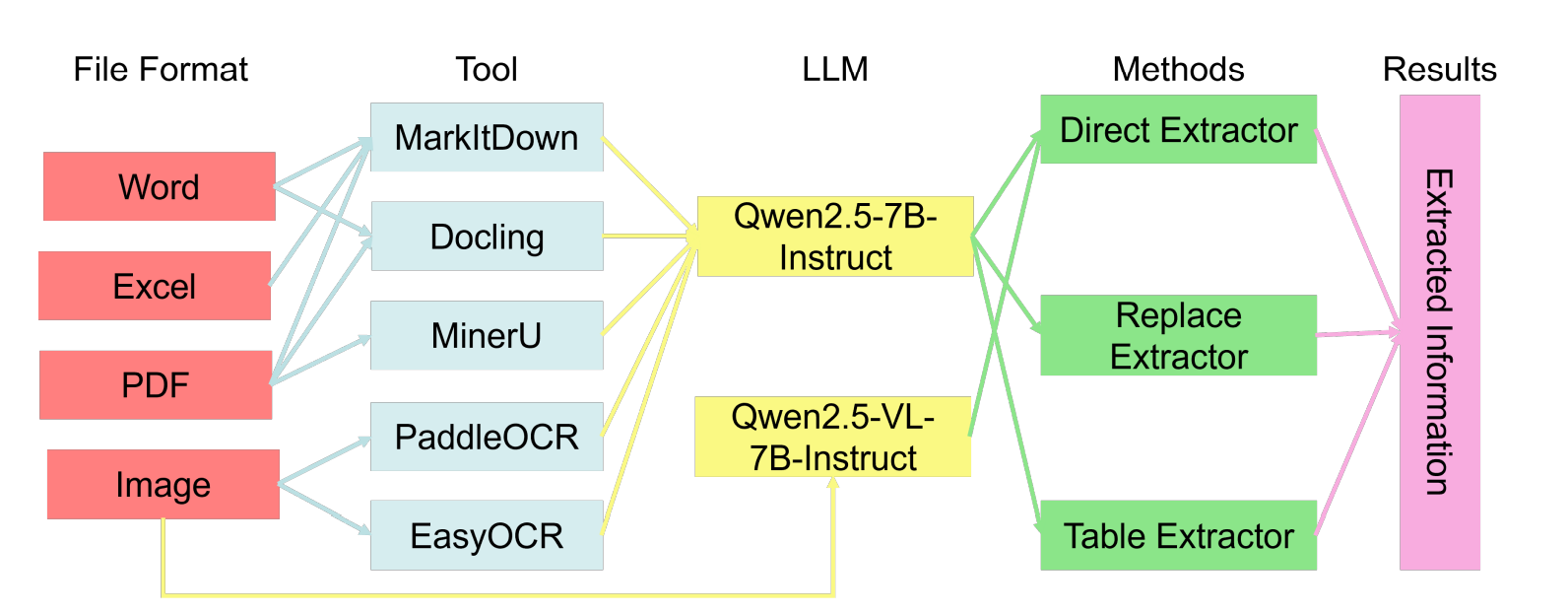
Stage 1: Text Acquisition
Depending on the file type, different parsing or OCR tools are used— MarkItDown, Docling, MinerU, PaddleOCR, EasyOCR — to extract content. The goal here isn’t just to get the words out. It is also important to preserve layout and positional information as much as possible. That context often carries important meaning, especially in forms, tables, and official documents.
Stage 2: Targeted Extraction
Once you have the raw text and layout data, use one of three strategies based on the document’s structure.
Direct: For simpler cases, send the extracted text straight to an LLM for end-to-end extraction. If the document is image-heavy, it might use a multimodal model to process it directly.
Replace: In more rigid formats, replace structural elements (like field labels or placeholders) before feeding the text to the LLM. This improves consistency and makes it easier to batch process similar documents.
Table: When dealing with dense tables, the LLM only needs to find where the table is and identify the coordinates of each cell. A deterministic parser then extracts the actual content. This cuts down hallucinations and reduces overall compute.
Model Choices
Use Qwen2.5-7B for text-based tasks, and Qwen2.5-VL-7B for image-plus-text scenarios. These give us a solid balance between accuracy, efficiency, and instruction-following stability.
A Closer Look: Pushing Document Structure to Its Limits
Choosing the Right Parsing Tools
Not all formats are created equal, and different tools serve different strengths.
Docling (AI Innovations and Trends 03: LightRAG, Docling, DRIFT, and More) is ideal for maintaining reading order and hierarchical structure. This is especially useful for tasks that are sensitive to layout, like parsing tables or understanding document sections.
MinerU (From Big Picture to Details: MinerU 2.5 Redefines Document Parsing — AI Innovations and Insights 77) focuses on pixel-level layout recovery for complex PDFs. It’s particularly good when visual structure matters just as much as the text itself.
MarkItDown (AI Innovations and Insights 20: HtmlRAG, AFLOW, ChunkRAG, and MarkItDown) handles common office file formats and preserves semantic markers, which helps maintain logical structure.
PaddleOCR and EasyOCR are used for image-based documents. PaddleOCR tends to perform better in multilingual scenarios and does a more consistent job mapping text to spatial positions.
One key principle across all these choices: structure fidelity matters more than raw text accuracy. Especially for table-heavy workflows, preserving layout is critical. Without it, downstream table extraction often falls apart.
Choosing Among the Three Extraction Modes
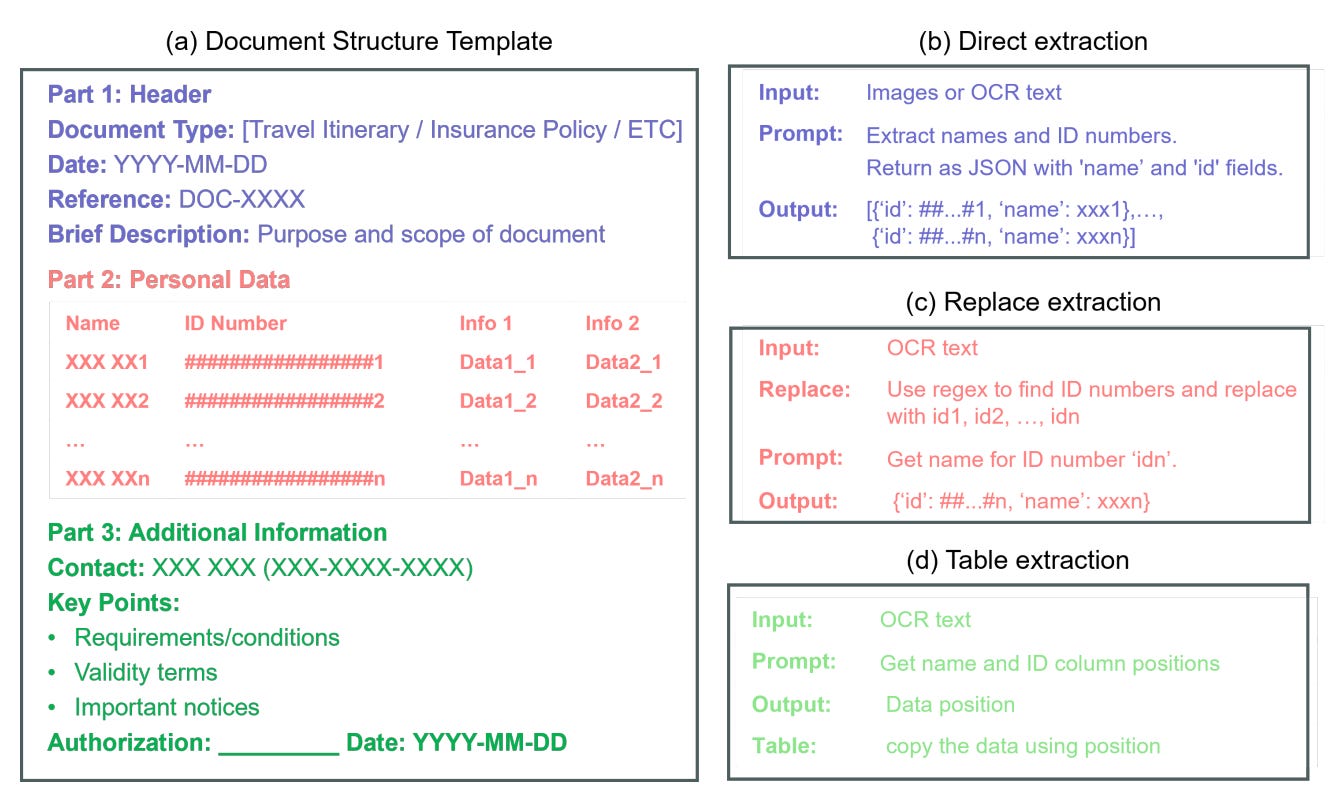
Each extraction strategy has its own trade-offs:
Direct is the most flexible. It works well across varied formats but is often bottlenecked by LLM inference speed.
Replace is reliable for documents with repetitive fields or templates. However, it can struggle with subtle associations like linking names to ID numbers when context is stripped out.
Table is the most efficient when structure is predictable. Here, the LLM only outputs the coordinates of key elements. The actual data is pulled using rule-based extractors, turning generation into controlled copy-paste.
Why 7B Models?
Models at the 7B scale hit a sweet spot: they’re lightweight enough for single-GPU deployment, yet still robust in producing structured outputs. They also offer consistency across both text and multimodal inputs, making evaluation and maintenance far more manageable.
Evaluation
The experiment used 400 synthetic Chinese identity documents spanning four formats: PNG, DOCX, XLSX, and PDF. It tested 16 different OCR-LLM combinations across three extraction modes—Direct, Replace, and Table—with up to 100 samples per format. In total, around 2,500 test cases were evaluated.
The evaluation tracked standard metrics like precision, recall, F1 score, and processing latency (broken down into OCR and LLM components). It also reported success rates and per-format accuracy.
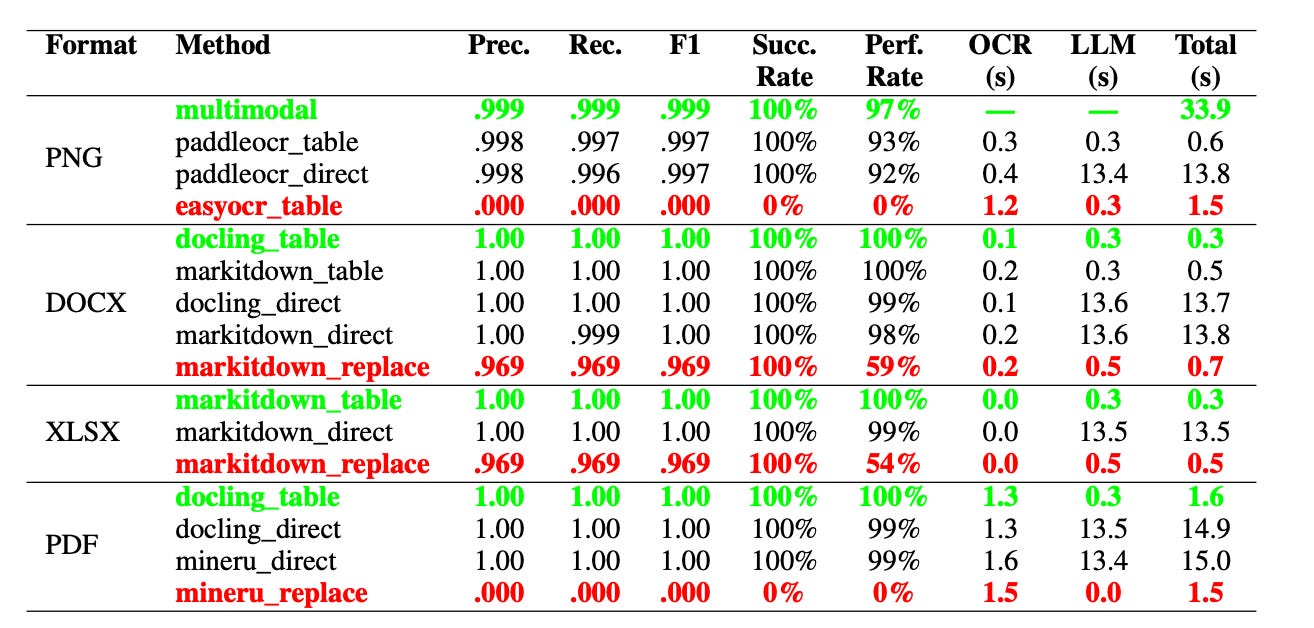
On structured formats like DOCX and XLSX, the Table mode delivered perfect results: F1 scores of 1.0, latency between 0.3 and 0.5 seconds, and a 100% success rate. Replace mode, on the other hand, performed worst on these formats, with F1 scores around 0.969 and a drop in perfect extraction rate to 59% for DOCX and 54% for XLSX, primarily due to the LLM occasionally mismatching names with their corresponding ID numbers.
For image-based documents (PNG), a multimodal model baseline achieved an F1 of 0.999, but required about 33.9 seconds per sample. When using PaddleOCR as the upstream tool, the Table mode maintained an F1 close to 0.997 while cutting latency down to roughly 0.6 seconds—offering a 54x speed-up over the multimodal baseline. By contrast, EasyOCR combined with the Table mode failed completely, scoring an F1 of 0.000, because EasyOCR’s process fails to preserve the spatial layout of the text, making it impossible for the LLM to locate table cells.
PDF results showed a similar pattern. The docling_table combination reached an F1 of 1.0 with a total latency of about 1.6 seconds. Meanwhile, mineru_replace failed entirely, with both F1 and success rate dropping to zero—highlighting the risks of mismatching method and document format.
Overall, Direct mode consistently showed the longest inference times, about 13–15 s, as it relied heavily on the LLM. In contrast, Table achieves 41–54× on PNG/Office; for PDFs, the speedup is ~9–10×.
The overarching conclusion from the evaluation is that there is no ‘one-size-fits-all’ solution. The optimal strategy is intrinsically tied to the document’s format, proving the necessity of an adaptive, format-aware framework that routes tasks to the most efficient method—such as using table-based extraction for structured files and multimodal models as a robust fallback for degraded images.
Thoughts
Hybrid OCR-LLM treats structural redundancy not as a problem, but as a performance lever. The LLM acts as a locator, while the actual content extraction is handled by deterministic parsers. It’s a rare example of a pragmatic setup designed specifically for copy-heavy documents, and it aligns closely with production goals around low latency and high stability.
Still, I have concerns about fragility. The pipeline depends heavily on stable layout patterns and precise spatial fidelity from the OCR layer. Any shift in page margins, the addition of new fields, seals overlapping text, or even a change in OCR engine can cause the system to fail abruptly. As shown in the case of EasyOCR combined with the Table mode, performance can drop from near-perfect to completely unusable.
Reference: Hybrid OCR-LLM Framework for Enterprise-Scale Document Information Extraction Under Copy-heavy Task.