
HunyuanOCR: Unifying Multi-Stage OCR Pipelines into an End-to-End 1B VLM — AI Innovations and Insights 91

Real-world OCR isn’t just about reading crisp PDFs. It involves receipts, IDs, multi-page contracts, and documents in dozens of languages. If the goal is lightweight, scalable, and robust OCR that can run on the edge or serve high-QPS scenarios, then stacking a bunch of fragile modules together just doesn’t cut it anymore.
This article might provide a useful perspective.
Traditional OCR
Pipeline-Based OCR is Too Fragmented
A typical document understanding system usually cobbles together at least five separate subsystems: text detection, recognition, layout analysis, formula parsing, and table extraction (Demystifying PDF Parsing 02: Pipeline-Based Method). Any change (tweaking a model, upgrading a component, adjusting a parameter) can ripple through the entire stack. As a result, the system becomes hard to deploy, harder to maintain, and costly to scale.
Make a mistake early (such as misdetect a text box) and everything downstream collapses with it: recognition fails, layout parsing gets misordered, and your final structured output is wrong. Once errors start piling up, it’s hard to trace or fix them without rethinking the whole architecture.
General-Purpose VLMs Are Powerful, But Impractical
Multimodal models like Gemini or Qwen-VL are impressive in OCR tasks, they can handle multiple languages and messy layouts with surprising accuracy.
But with their massive parameter counts, they demand significant compute power and aren’t suitable for deployment on edge devices or in real-world business scenarios.
Existing Specialized VLMs Still Inherit Pipeline Problems
OCR-specific VLMs (Demystifying PDF Parsing 03: OCR-Free Small Model-Based Method) have started to emerge, often combining a layout detector with a recognition VLM that does unified recognition across text, formulas, and tables. While simpler than traditional stacks, they still retain a two-stage “detect → recognize” structure.
This means layout errors still leak into downstream predictions, and the system doesn’t fully benefit from true end-to-end training.
HunyuanOCR: A 1B-Parameter, End-to-End Vision-Language Model
HunyuanOCR was built with a clear goal in mind: deliver a lightweight, production-grade, open-source OCR expert model that can handle the full stack of OCR tasks (spotting, parsing, information extraction, visual question answering, and image-to-text translation) under a single unified architecture.

Model Architecture
HunyuanOCR is structured around three core components:
Native Resolution Visual Encoder (Hunyuan-ViT): Built on top of the SigLIP-v2-400M pretrained model, this module preserves the original aspect ratio of images using an adaptive patching mechanism. It natively supports arbitrary input resolutions, making it particularly suitable for extreme aspect ratios such as long-text documents and other non-standard layouts (e.g., receipts).
Adaptive MLP Connector: This component compresses the high-resolution token sequence produced by the visual encoder, intelligently retaining critical semantic information, particularly in dense text regions, while reducing computational redundancy.
Lightweight Language Model (Hunyuan-0.5B): Based on a 0.5B parameter model, this module introduces XD-RoPE, which decomposes traditional rotary position encoding (An In-depth exploration of Rotary Position Embedding (RoPE)) into four subspaces: text, height, width, and time. This establishes a native alignment for 3D spatiotemporal information and allows the model to reason across complex layouts and span multiple pages with logical consistency.
Training Data
The model is trained on over 200 million image–text pairs across nine real-world scenarios: street views, documents, advertisements, handwritten text, screenshots, cards/certificates/invoices, game interfaces, video frames, and artistic typography, covering more than 130 languages.
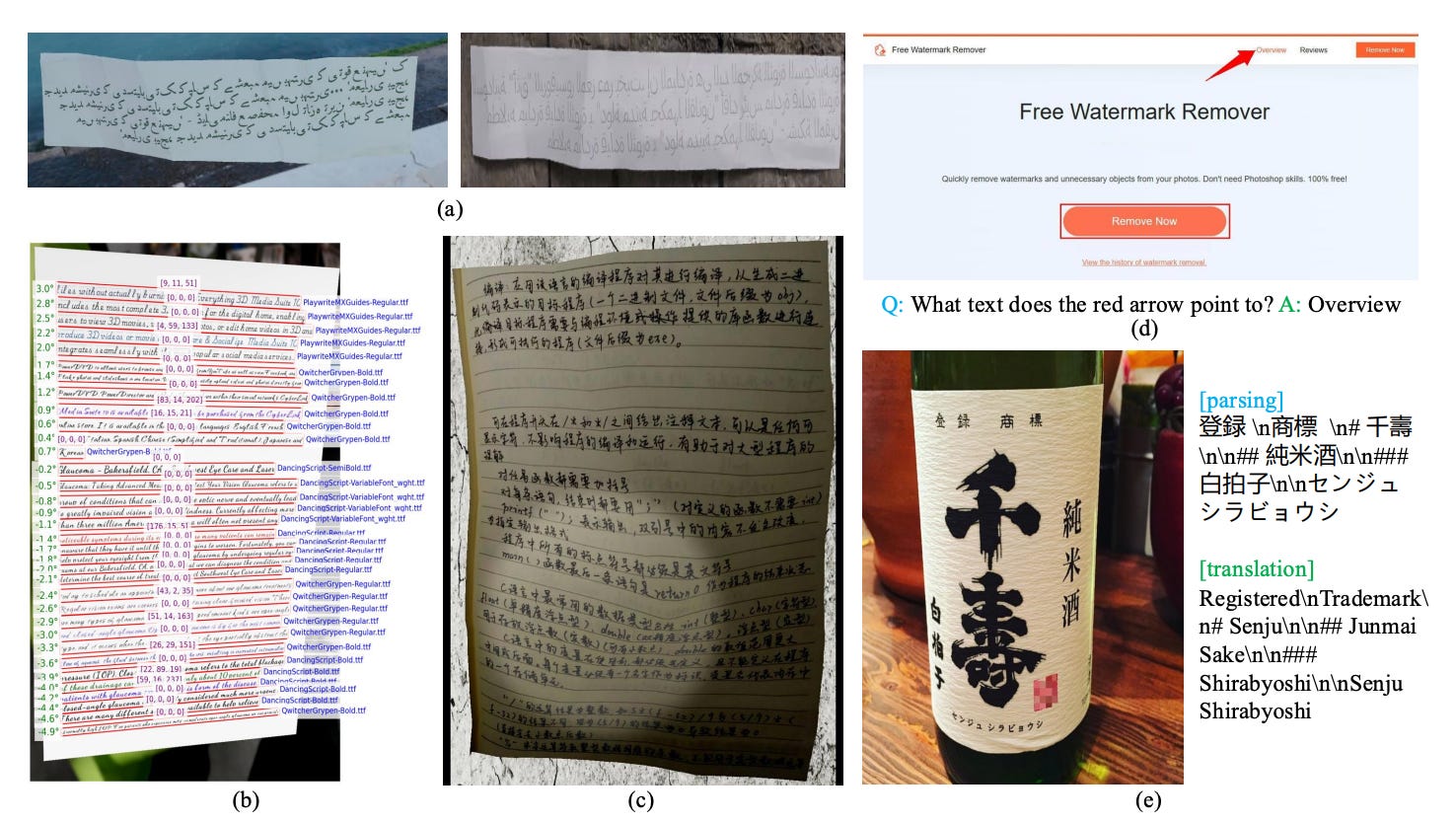
The data pipeline includes:
Building on SynthDog, image synthesis with paragraph-level rendering in 130+ languages, supporting both left-to-right and right-to-left scripts.
Augmentation techniques that simulate real-world noise: perspective distortion, blur, lighting defects.
Cross-task QA generation, reusing existing spotting/parsing outputs to automatically generate VQA examples.
This ensures broad coverage across languages, document types, and scene variations.
Four-Stage Pretraining Strategy
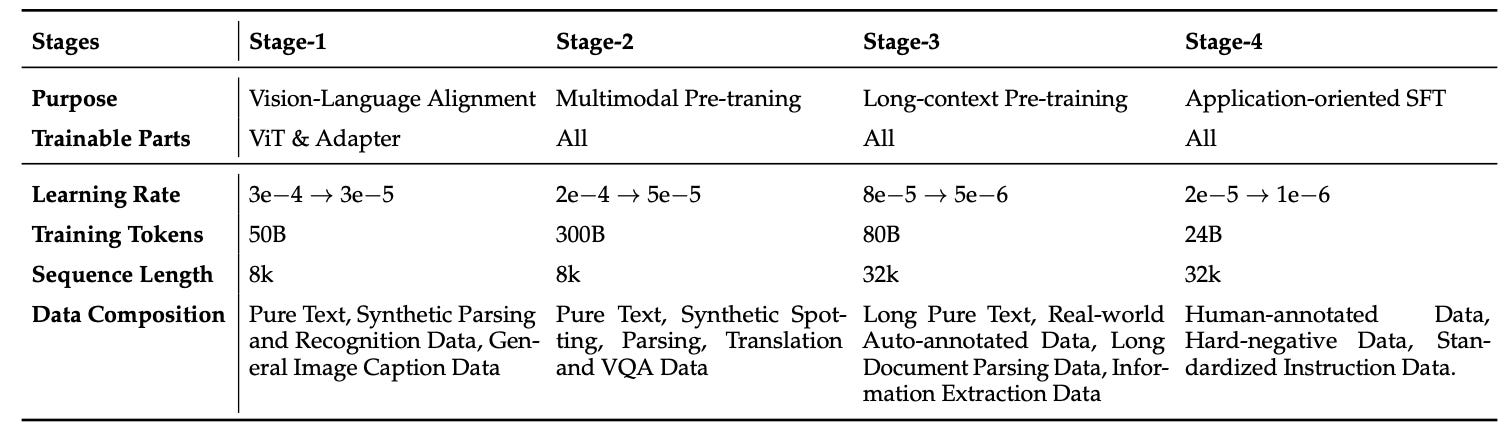
HunyuanOCR’s pre-training process unfolds in four stages, followed by GRPO-based reinforcement learning for post-training.
Stage 1 (Vision-Language Alignment): Only the visual encoder and adapter are trained, aligning visual features with textual semantics.
Stage 2 (Multimodal Joint Learning): All parameters are unfrozen to support full end-to-end training across tasks like spotting, parsing, translation, and VQA.
Stage 3 (Long-Context Support): the context window is extended to 32k tokens by incorporating long-document parsing and lengthy text data, enhancing the model’s ability to handle long contexts.
Stage 4 (Application-Oriented SFT): Instruction tuning is applied using curated real-world data, establishing a foundation for downstream optimization.
Reinforcement Learning That Actually Works
After pre-training, HunyuanOCR adopts GRPO as its main RL algorithm, combined with Reinforcement Learning with Verifiable Rewards (RLVR) for closed-form tasks (spotting and parsing) and an LLM-as-a-judge scheme for translation and text-centric VQA, using task-specific reward designs to fine-tune its capabilities.
Spotting: Matches predicted boxes with ground truth using IoU, then scores based on
1 - normalized edit distance. Unmatched predictions get zero reward.Parsing: Reward is computed from the normalized edit distance between the model’s output and the ground-truth reference, emphasizing both structural integrity and content accuracy.
VQA: Simple scoring, if the answer semantically matches the reference, it gets a 1 (tolerating minor stylistic differences). Otherwise, 0.
Translation: Uses an LLM-as-a-judge setup to rate output between 0 and 5, normalized to [0, 1]. The mid-range (2–4) is expanded to better reflect nuanced differences in translation quality.
Evaluation: A Quick Look at the Scoreboard
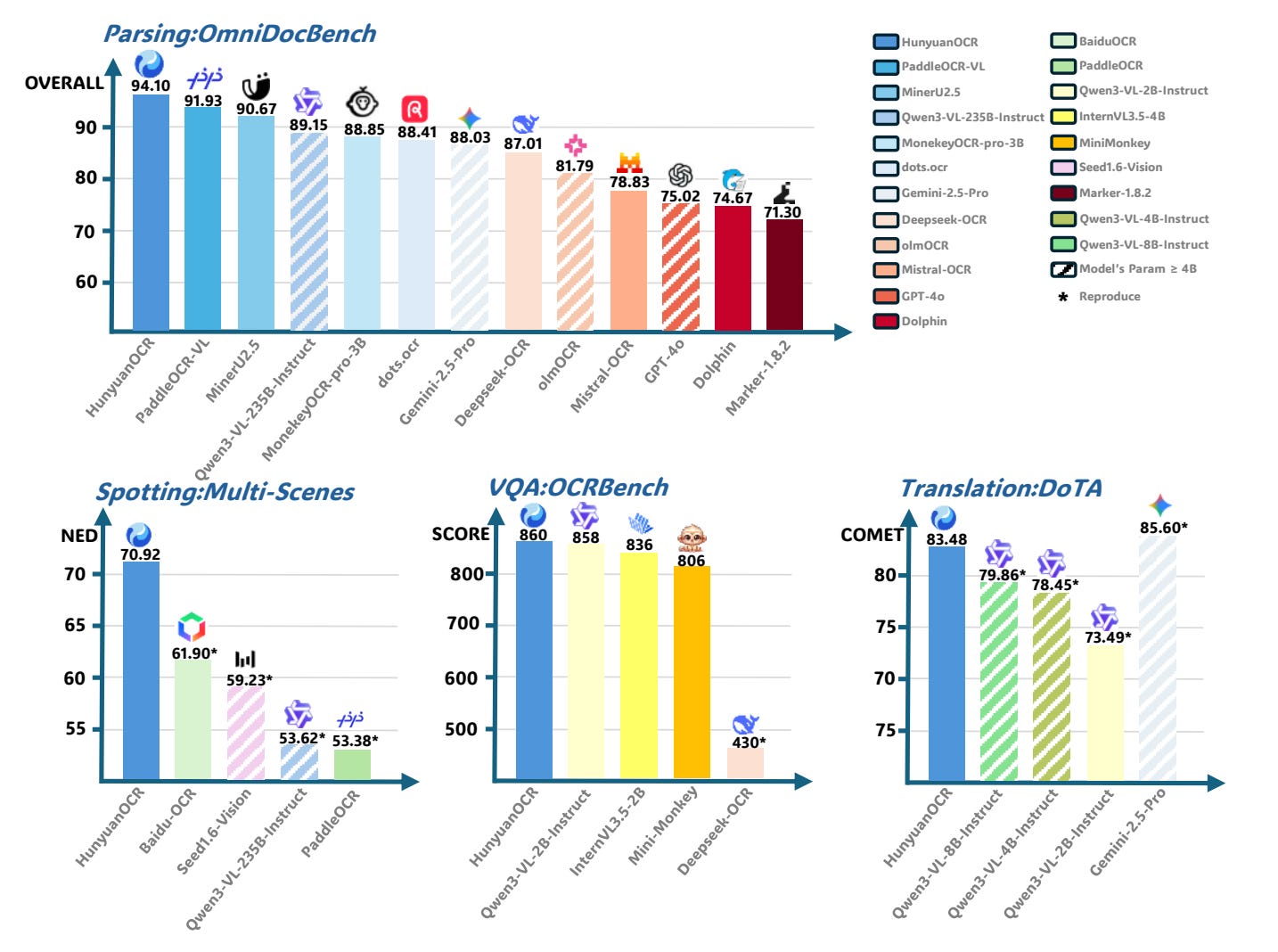
Figure 4 shows a snapshot of HunyuanOCR’s capabilities across a handful of representative tasks. Against models like PaddleOCR-VL, MinerU2.5 (From Big Picture to Details: MinerU 2.5 Redefines Document Parsing — AI Innovations and Insights 77), and Qwen3-VL, HunyuanOCR comes out ahead in parsing and spotting, and achieves SOTA results on OCRBench among comparable lightweight models.
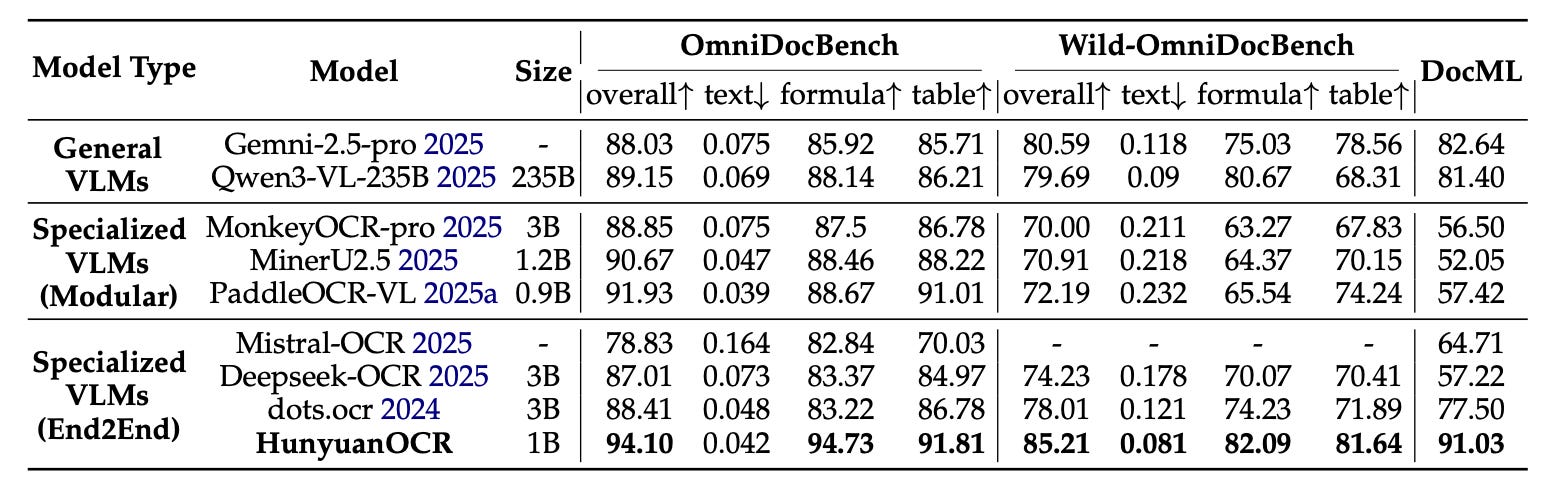
For document parsing specifically, the model performs especially well. On OmniDocBench, which includes both digital and scanned documents, HunyuanOCR achieved an overall score of 94.10. That’s a solid jump over MinerU2.5 (90.67) and PaddleOCR-VL (91.93), and it also edges out several much larger general-purpose vision-language models (see Figure 5).
These results underline the model’s strong generalization across structured, real-world OCR tasks, and do so with just 1B parameters.
Thoughts
What makes HunyuanOCR genuinely valuable is how it compresses the traditional, multi-model OCR pipeline—usually a messy combo of detection models, recognition modules, layout parsers, and a pile of scripts—into a single, end-to-end 1B vision-language model. That alone simplifies deployment and long-term maintenance in a very real way.
That said, I have some concerns. The model leans heavily on large-scale, high-quality synthetic data and a carefully engineered reward system for reinforcement learning. Both are difficult to reproduce outside the original team. Even though HunyuanOCR addresses this concern by evaluating on Wild-OmniDocBench and DocML, demonstrating strong robustness against real-world distortions, though independent verification is still needed.
From a practical engineering standpoint, this kind of unified OCR VLM starts to make a lot of sense when the workload involves diverse formats: receipts, ID cards, subtitles, multilingual documents. In those cases, trying to stitch together a dozen separate models becomes more trouble than it’s worth. But in narrower scenarios (such as single-language, high-throughput text extraction), the old-school lightweight pipeline still has its place.
In my view, in the future, a more sustainable direction for OCR might be to stop trying to serve production traffic directly with massive, general-purpose VLMs. Instead, use them as judges and teachers to supervise and fine-tune smaller, task-specific expert models that are cheaper to run and easier to deploy. That’s likely where the sweet spot lies for both performance and engineering cost.
Reference: HunyuanOCR Technical Report.
The point about error propagtion in traditional OCR pipelines really resonates. I've seen firsthand how one misdetected text box early on can completly derail downstream parsing. Consolidating all this into a 1B end-to-end model feels like the right directon, especially for edge deployment. What's your take on reproducing the synthetic data pipeline though?