

This is the Chapter 68 of this insightful series!
Why Plain RAG Hits a Ceiling
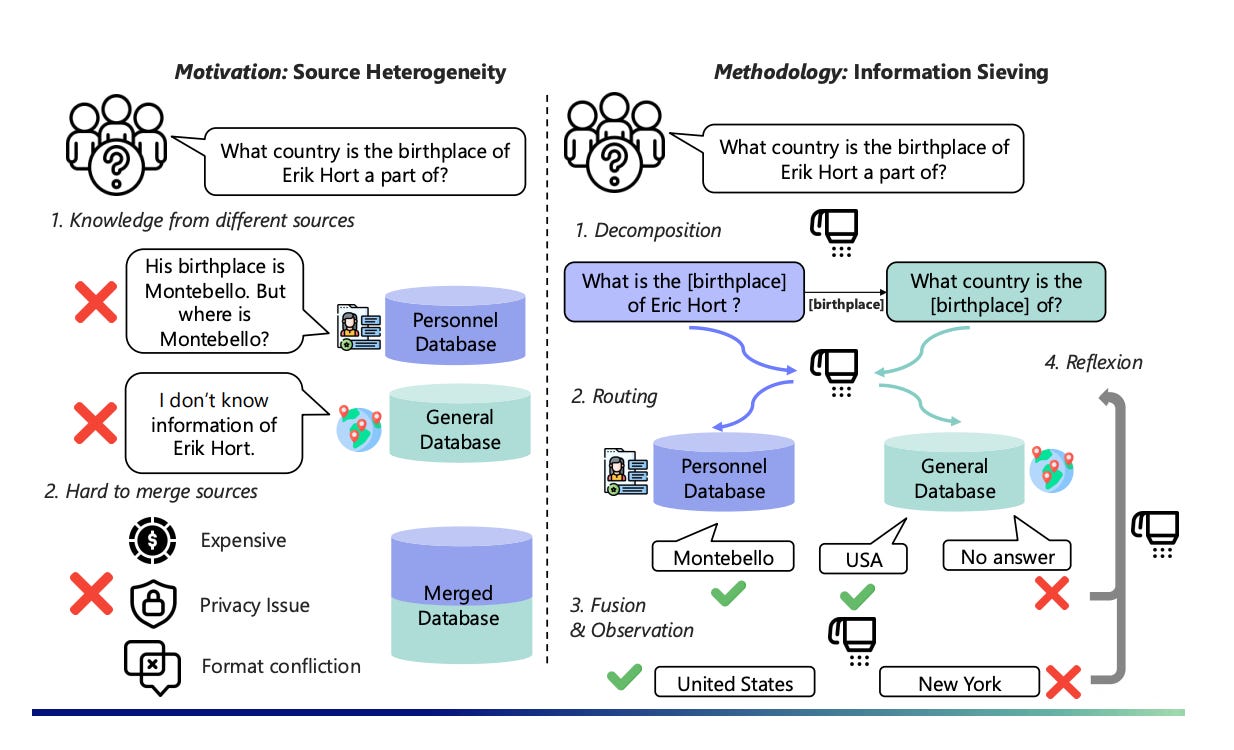
Most RAG systems treat a user question like a single, indivisible string: retrieve, read, answer. That "one heavy swing" approach glosses over structure and multi-hop dependencies, so retrieval gets noisy and reasoning stays shallow.
Real-world knowledge isn't tidy, either. You'll meet different formats (unstructured text, SQL, APIs), different domains, and sources you can't or shouldn't merge into one giant index.
Meet DeepSieve: a Four-Stage "Sieve," not a Single Swing
To address these limitations, DeepSieve runs every query through four small, predictable steps—Decompose → Route → Reflexion → Fuse—with a controller that's transparent and easy to tweak.
Each step has a clean interface, so you can swap parts without rewriting the whole pipeline.
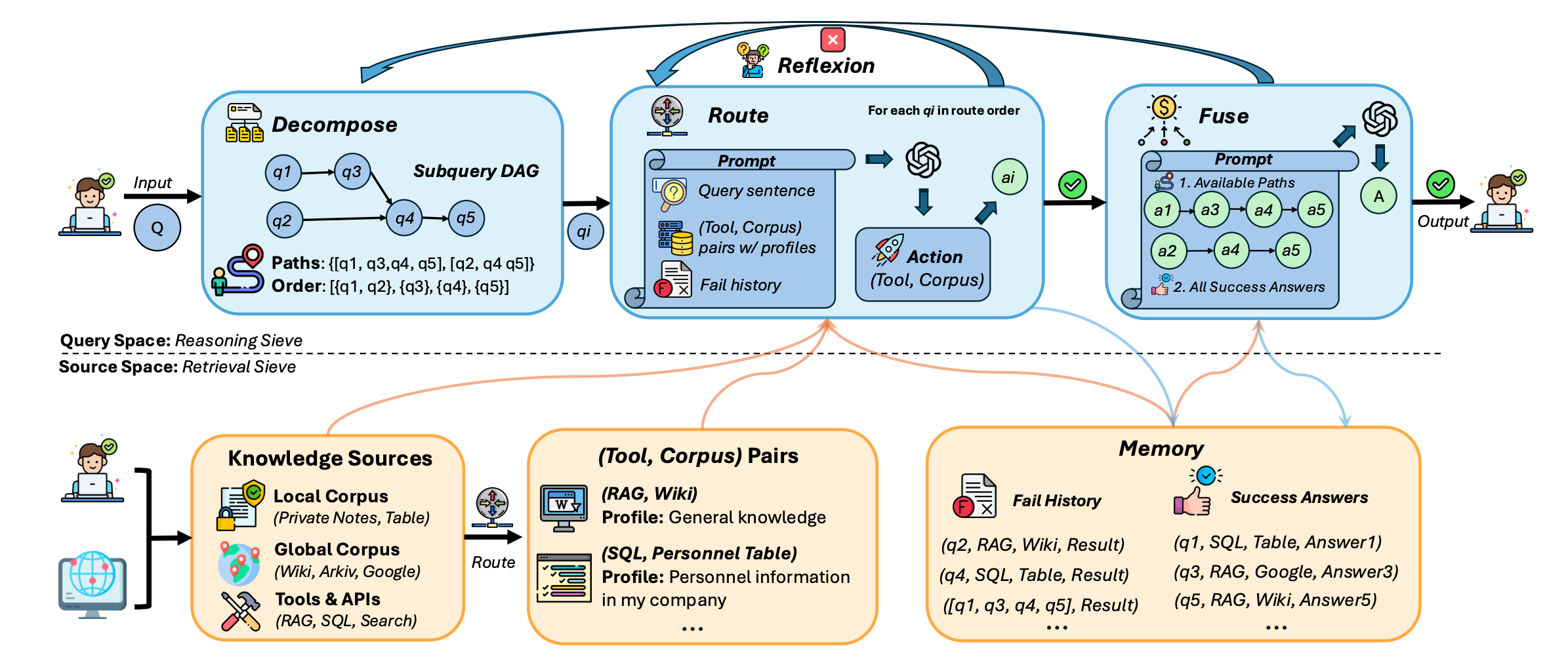
Under the Hood: How Each Stage Actually "Sieves"
1. Decompose—turn a big ask into a DAG you can run.
A planner splits the original query into structured subquestions and wires them into a DAG. Nodes are atomic reasoning units; edges encode dependencies that get resolved at fusion time. This makes the plan legible, auditable, and reproducible.
2. Route—pick the right source on purpose, not by vibes.
For each subquestion, a router chooses a (Tool, Corpus) pair from the source pool. The routing prompt bakes in three signals: what the subquestion means, what each source is good for (its profile), and where you've already failed. The system then runs the chosen tool over the chosen corpus to get a candidate answer.
3. Reflexion—if the result is weak, try another lane.
When a candidate answer looks incomplete or irrelevant, DeepSieve doesn't rewrite the question. It re-routes the same subquestion to a different source, guided by a memory of failed attempts (to avoid repeating them) while storing successful ones to form trusted evidence for fusion.
4. Fuse—stitch consistent subanswers along the DAG.
Fusion considers valid paths through the subquestion graph and includes only consistent subanswers; if evidence conflicts, it can run a brief global pass to reconcile contradictions and produce a single, unified response.
Modularity—Keep What Works, Replace What You Like.
Every stage is a module. Sources are abstracted as (Tool, Corpus) pairs with human-readable profiles, so adding BM25, FAISS, ColBERTv2, or even SQL/API just means registering a wrapper and profile. No schema gymnastics, no index fusing required.
Experimental Setup: Datasets, Baselines, Metrics
DeepSieve evaluates on three multi-hop QA benchmarks—MuSiQue, 2WikiMultiHopQA, and HotpotQA—and reports EM/F1 plus total tokens used by the LLM across steps. Backbones are DeepSeek-V3 and GPT-4o. To simulate source heterogeneity, each dataset is partitioned into "local" and "global" segments; DeepSieve routes at the subquestion level across those segments, while baselines use the merged corpus for fairness. Baselines include IRCoT, ColBERTv2, HippoRAG, RAPTOR, ReAct, ReWOO, Reflexion, and standard CoT.
What Changes in Practice: Accuracy and Cost
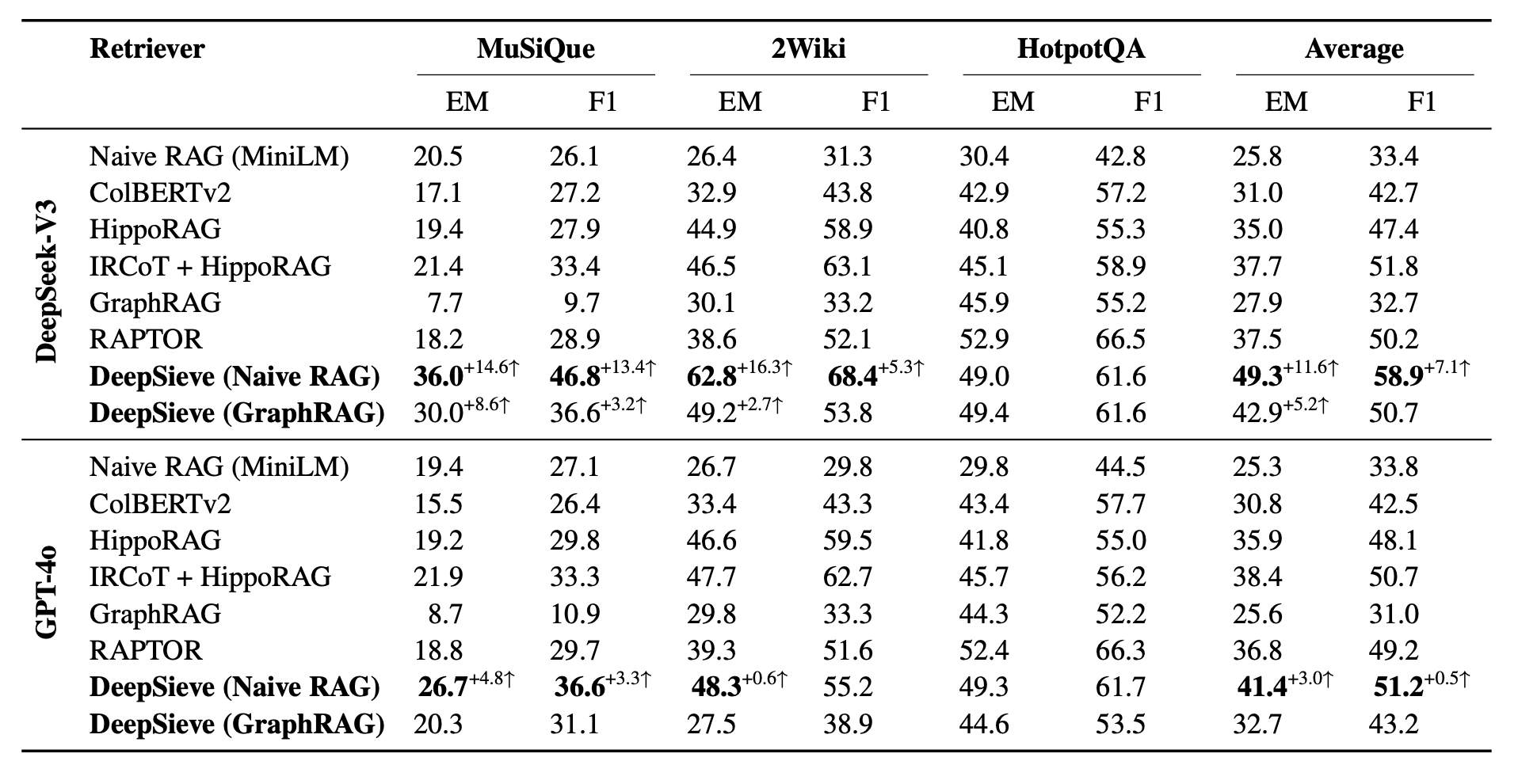
Accuracy: DeepSieve lifts F1 across the board. With DeepSeek-V3, the Naive RAG variant reaches 46.8 F1 on MuSiQue and 68.4 F1 on 2Wiki, leading to a 58.9 average F1—the best among all systems compared. With GPT-4o on HotpotQA, DeepSieve clocks 49.3 EM / 61.7 F1.
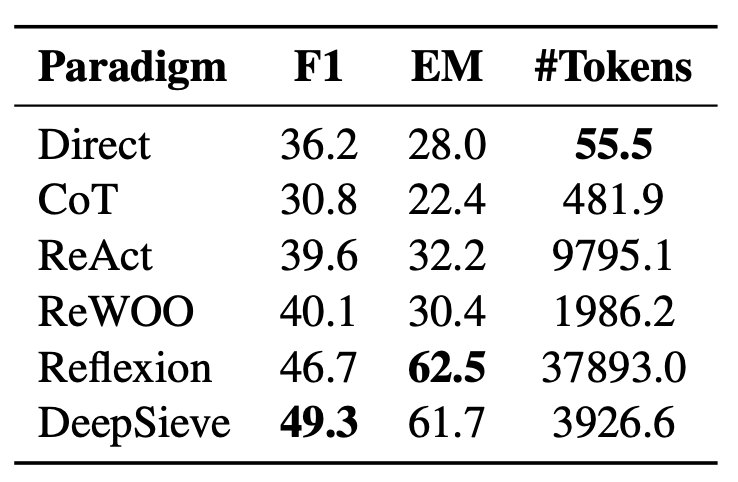
Cost: On HotpotQA (GPT-4o), DeepSieve averages ~3.9K tokens per query, versus 9.8K for ReAct and 37.9K for Reflexion—so you get higher accuracy without burning through tokens.
Thoughts
DeepSieve replaces the usual "retrieve-then-hope" with four small verbs: decompose, route, reflect, fuse. The payoff is tangible—higher average F1 with leaner token budgets—and the path to adoption is practical thanks to the modular controller and human-readable source profiles. If you need explainable, multi-source reasoning that you can adapt and maintain, this is a strong baseline to build on.
The real cleverness of DeepSieve is that it turns the hidden, black-box "chain of thought" inside traditional RAG systems into an explicit, controllable pipeline — a modular “cognitive assembly line” you can inspect, tune, and orchestrate. That shift moves us from ad-hoc "augmented generation" toward deliberate, composable reasoning. Yes, it trades single-query latency for the ability to handle complicated, heterogeneous data and multi-hop dependencies — but that’s a conscious trade: you pay a bit of orchestration complexity to gain much deeper, more reliable inference.