
From Few-Shot to Full Scale: Unlocking the Secrets of Task-Specific SFT Dataset Creation

Constructing high-quality Supervised Fine-Tuning (SFT) datasets has always been a worthwhile research direction. Today, let's explore a new method.
While large language models (LLMs) have shown exceptional performance across a wide range of tasks, achieving optimal results for specific tasks—especially in specialized domains like biology or medicine—still requires extensive fine-tuning. However, building high-quality datasets for these specialized tasks is a time-consuming, resource-intensive process that often demands deep domain expertise.
“CRAFT(Corpus Retrieval and Augmentation for Fine-Tuning)” aims to tackle a major challenge: the difficulty of creating high-quality, task-specific datasets for fine-tuning language models. The motivation behind CRAFT is to reduce the manual overhead and enable more efficient dataset generation through synthetic means, using minimal user-provided examples.
Overview
CRAFT introduces a method that utilizes large-scale public corpora to retrieve relevant documents and then augments these documents using LLMs to create task-specific datasets. It relies on user-provided few-shot examples as input to guide the process of generating these datasets.
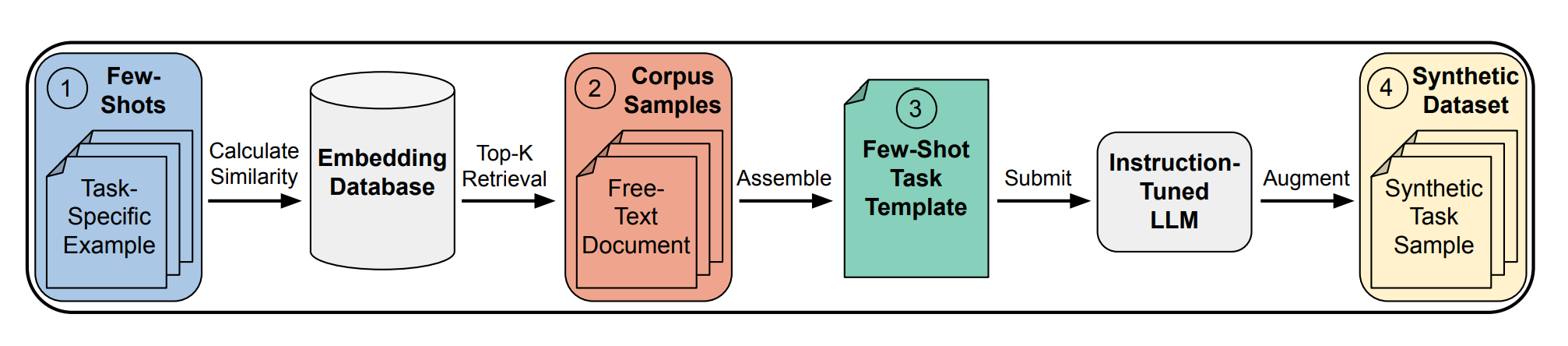
Step 1: Preparing Few-Shot Examples and Embedding Database
Few-shot examples are small, manually curated sets that provide a sample of the task, they are embedded into a vector space to facilitate the retrieval process. Figure 2 provides an example of these examples.

Embedding databases are pre-computed during the setup phase of CRAFT and are built from large, diverse corpora. These corpora can include domain-specific texts, such as biology or medical literature, as well as general-purpose documents. The embeddings capture the semantic relationships between the documents and the few-shot examples, allowing for precise retrieval.
Figure 3 presents an example from the corpora.

Step 2: Corpus Retrieval
CRAFT's workflow starts with the retrieval of relevant documents from large corpora. This step is guided by few-shot examples provided by the user. These few-shot examples serve as the query for the document retrieval system.
CRAFT calculates the similarity between these few-shot examples and documents in the corpus using methods like cosine similarity. The top-k most relevant documents are retrieved for further processing.
Step 3: Document Augmentation Using LLMs
Once the relevant documents are retrieved, CRAFT proceeds to the augmentation phase, where the retrieved documents are transformed into task-specific datasets. This is done using instruction-tuned LLMs.
The few-shot examples serve as templates, guiding the transformation of the retrieved documents. The templates specify how the text should be structured for the task. For example, a retrieved scientific article could be augmented into a question-answer format for a QA task. Figure 4 shows an example of how these templates guide the model in augmenting the corpus samples into synthetic task samples.

The final output of CRAFT is a large-scale synthetic dataset that mimics the format of the few-shot examples but is generated from real human-written documents. This dataset is then used to fine-tune language models on the specific task, such as biology QA, medicine QA, or summarization. Figure 5 shows an actual example output from the generated pool of synthetic training samples

Evaluation
Extensive evaluations were conducted using CRAFT-generated datasets for four tasks: biology QA, medicine QA, commonsense QA, and summarization. The experimental results indicate that models fine-tuned with CRAFT-generated datasets either outperformed or matched the performance of instruction-tuned LLMs across all tasks.
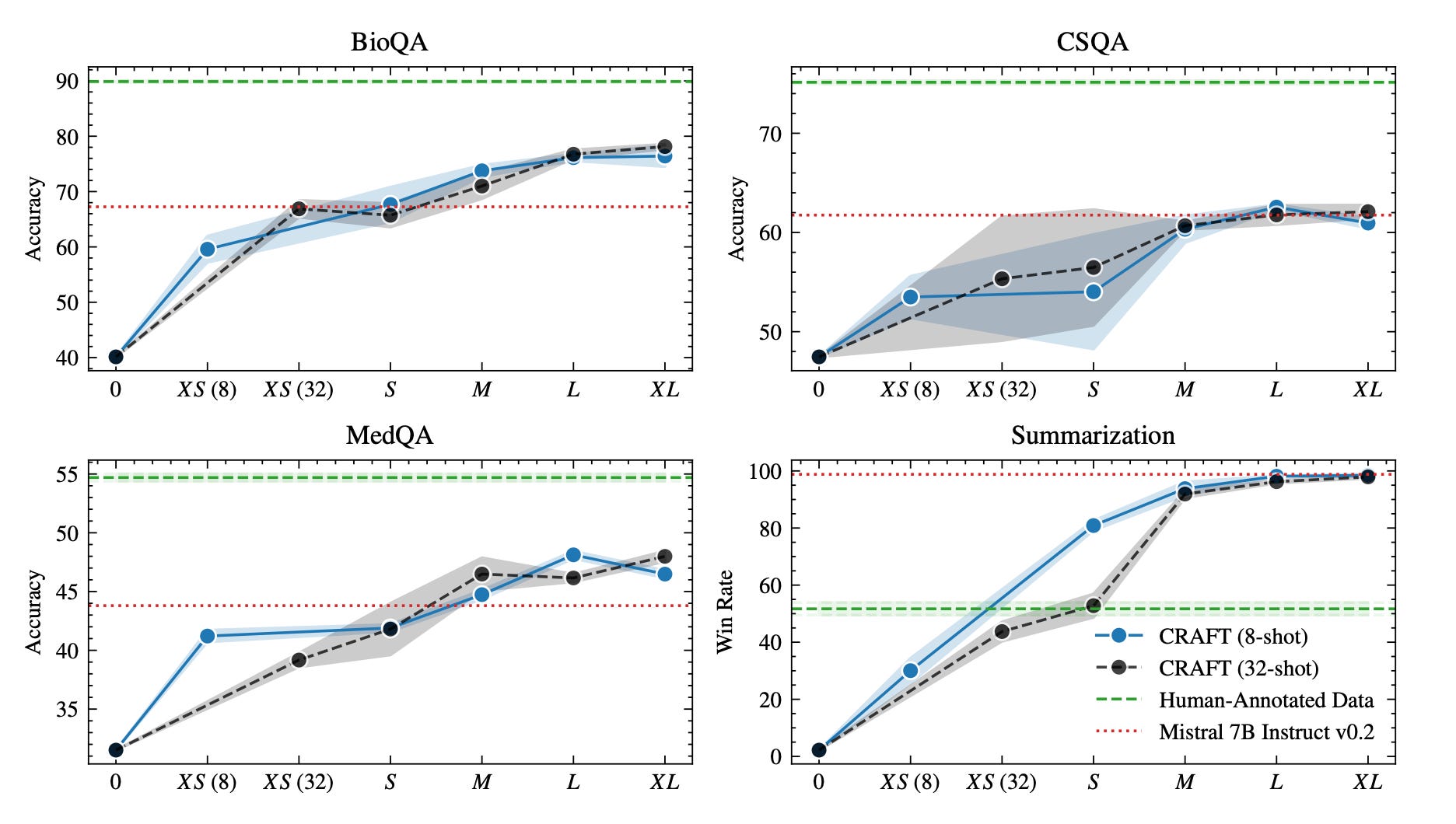
Figure 6 shows the performance scaling with increasing data size across multiple tasks, highlighting how models trained on CRAFT-generated datasets outperform or match the performance of baselines.
Case Study
1. Few-Shot Design
BioQA few-shot text samples: Compiled from diverse sources, including textbooks and Encyclopedia Britannica.
MedQA: Primarily utilized openly accessible resources such as NIH and Mayo Clinic websites.
CSQA: Samples were drawn from various online articles and blogs.
Continuous text snippets: Extracted from non-open sources to ensure articles crawled from C4 do not produce exact matches during retrieval.
Question and answer generation: Each sample's questions and answers were generated manually.
Recipe generation few-shots: Derived from blogs featuring structured meal instructions.
Summarization samples: Included texts from multiple sources to ensure a broad vocabulary for retrieval.
2. Embedding Database
SentenceTransformers were utilized, specifically the MiniLM (multi-qa-MiniLM-L6-cos-v1) optimized for cosine similarity searches. This model produces 384D embeddings, stored in an HDF5 database for efficient data retrieval.
3. Corpora
The retrieval system incorporates four extensive corpora:
C4 Dataset: A 305GB subset of a 750GB pre-cleaned dataset, omitting non-informative content.
English Wikipedia: Processed using WikiExtractor based on the January 2024 dump, offering diverse high-quality textual information.
Stack Exchange: Featuring structured Q&A formats from 173 sub-communities.
WikiHow: Step-by-step instructional documents.
After filtering based on character count, approximately 383 million documents were compiled across these datasets.
4. Document Retrieval
A two-step retrieval process for efficient similarity search was employed. The embedding database was divided into subsections, calculating cosine similarity in the first step, reducing the pool to around 19 million documents. In the second step, top-k similarity retrieval was performed. A mixed similarity retrieval strategy ensures a balance between topic diversity and relevance by combining individual top-k retrieval and averaged similarity.
5. Task Sample Synthesis
Text generation was aligned with few-shot design through in-context learning to mitigate hallucinations and formatting errors. Each prompt included three randomly sampled few-shot examples, leading to input lengths often exceeding 10,000 tokens. Task samples were generated using the Mistral 7B Instruct model, with quality control applied through structured JSON outputs. Samples that did not meet formatting criteria or showed high similarity to existing samples were discarded.
6. Training and Optimization
Fine-tuning utilized low-rank adaptation (LoRA) for efficiency. Implemented in PyTorch, an adaptive momentum optimizer was employed. Fine-tuning spanned three epochs, with a batch size of 2 for human-curated few-shots and 16 for others. LoRA adapters were applied to every linear layer, adding a minimal percentage of parameters while keeping the rest of the model frozen during training.
Conclusion and Insights
This article has explored the motivation behind CRAFT, its method for generating synthetic datasets, and the evaluation of its performance. In summary, CRAFT’s innovation lies in:
Efficiently generating synthetic task-specific datasets.
Utilizing large-scale retrieval and augmentation of human-written documents.
Outperforming human-curated datasets in certain tasks, as seen in summarization and QA tasks.
However, I think there are potential limitations. While synthetic data generation is powerful, it can sometimes produce noise or low-quality data. CRAFT addresses this through augmentation and specific task templates, but fully synthetic data generation may still suffer from low-quality outputs.
In future work, I believe adding a more robust quality-check mechanism or integrating real-time human feedback could further improve the dataset quality.