
Fewer Steps, Better Answers: How to Develop Efficient Reasoning in LLMs — AI Innovations and Insights 46

Welcome back! Let’s dive into Chapter 46 of this delightful series!
Large language models (LLMs) shine at tackling complex tasks like math and coding through chain-of-thought (CoT) reasoning. But there’s a catch: the step-by-step explanations they generate can get unnecessarily long, leading to significant computational overhead — a problem often referred to as the "overthinking phenomenon."
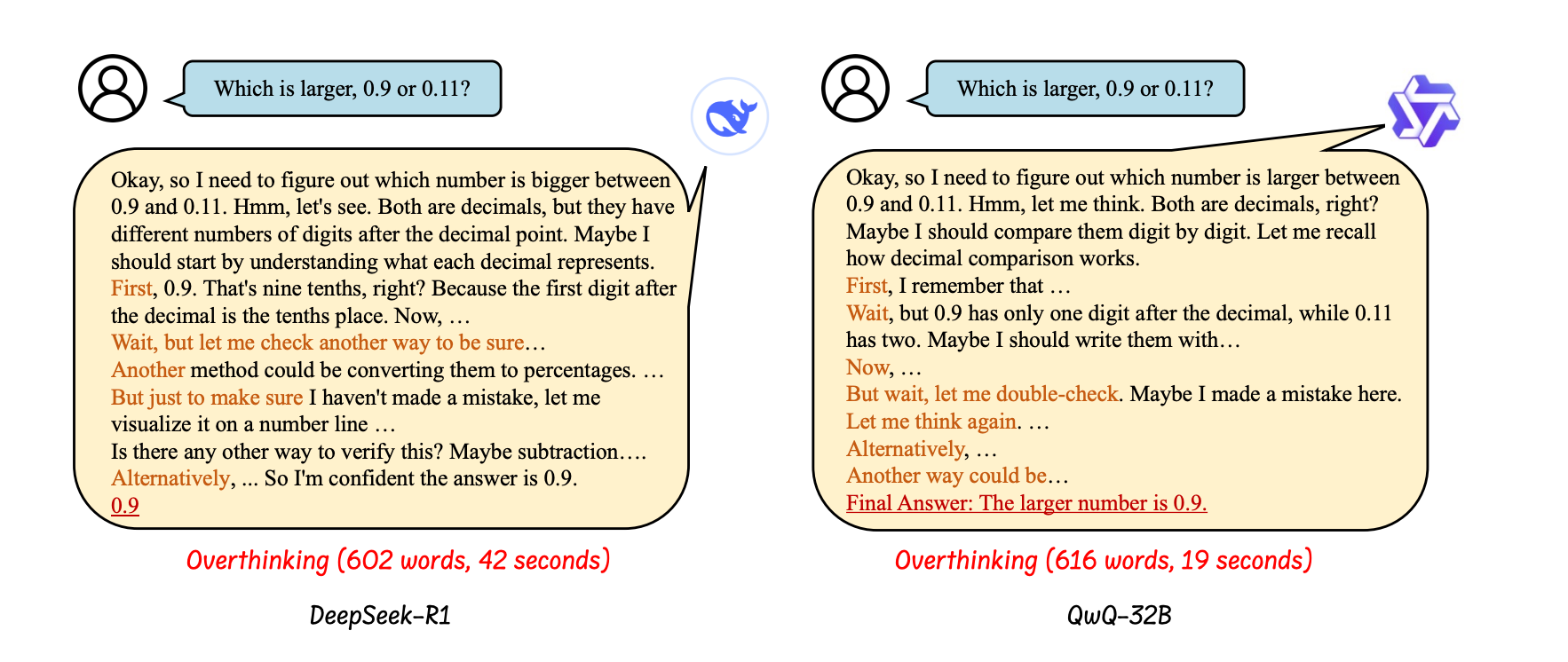
As shown in Figure 1, when answering a simple question like "Which is bigger, 0.9 or 0.11?", a reasoning model might still produce hundreds of redundant reasoning tokens, driving up both inference time and cost.
That’s why studying efficient reasoning in LLMs matters more than ever.
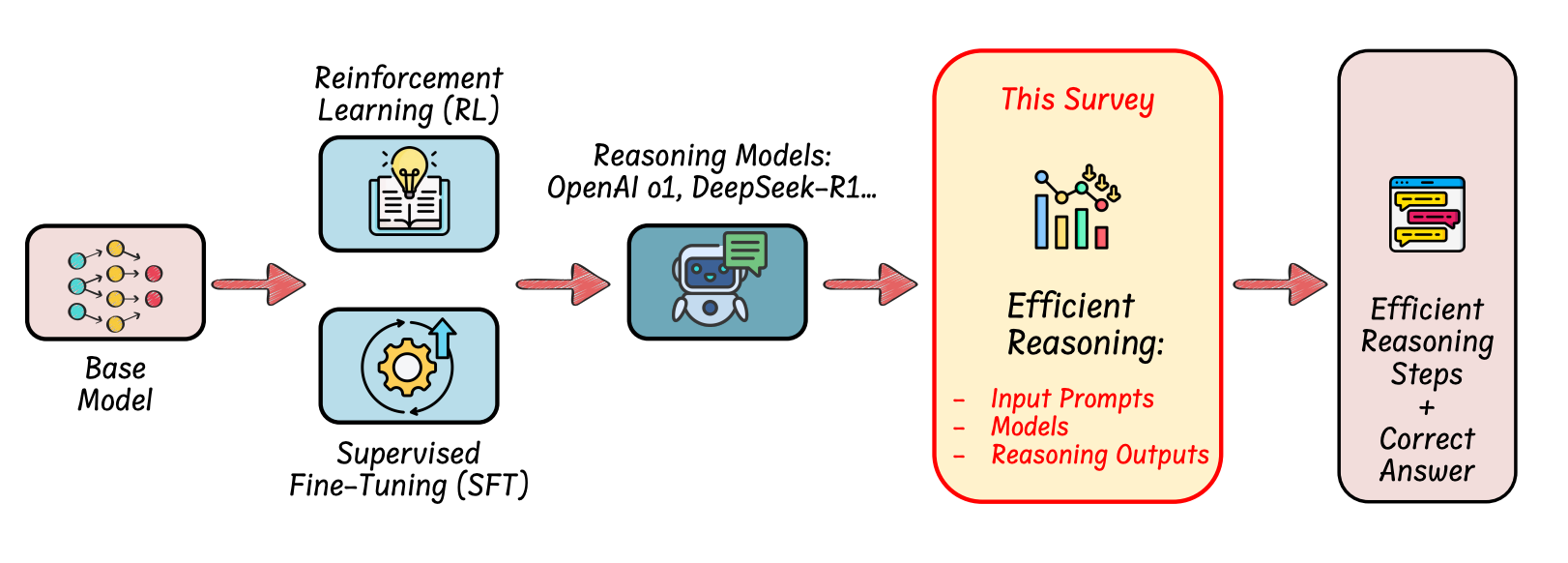
As shown in Figure 2, reasoning LLMs are usually built on top of base models using supervised fine-tuning (SFT), reinforcement learning (RL), or a mix of both.
"Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models" explores how to reduce unnecessary reasoning steps without losing accuracy—and even how to fine-tune general models to reason more efficiently. The goal is to help models deliver clear, concise answers supported by just enough reasoning—not more than needed.
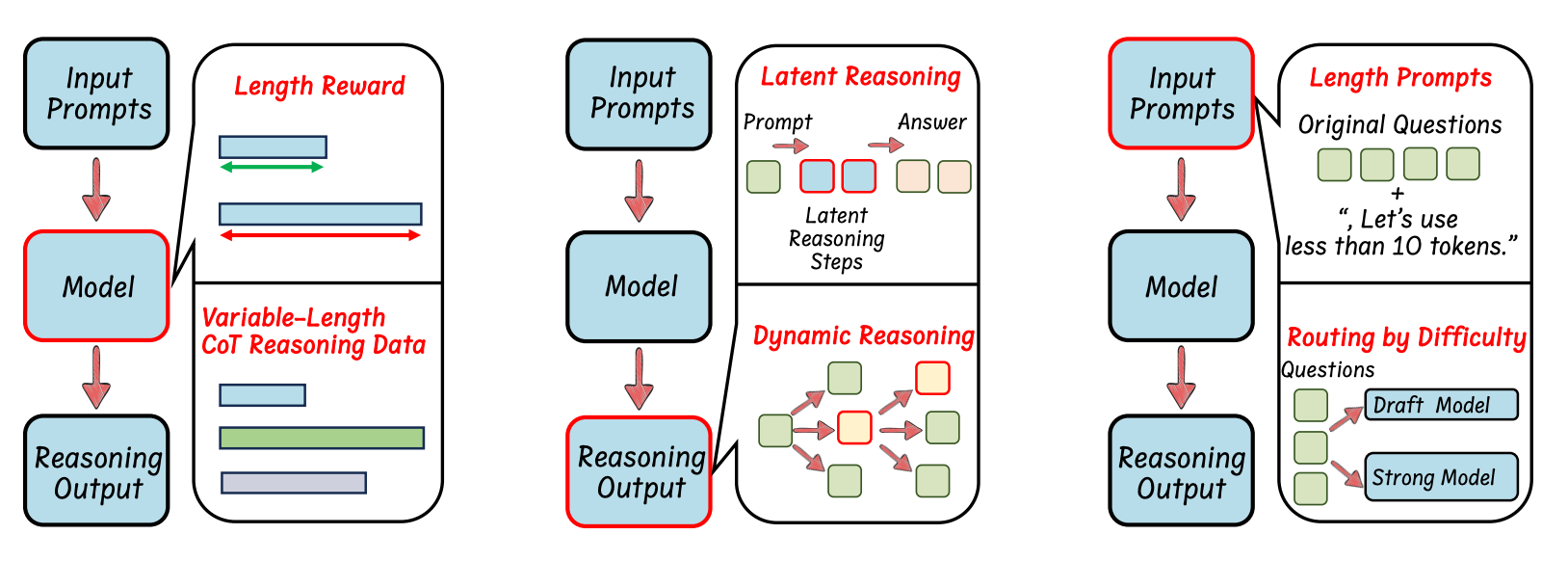
As shown in Figure 3, the existing research can be divided into three main approaches:
Model-based methods focus on training techniques—like using reinforcement learning to reward shorter reasoning paths, or fine-tuning with chain-of-thought data of varying lengths.
Output-based methods work by either compressing reasoning steps into a compact latent space or dynamically adjusting the reasoning process during inference.
Prompt-based methods guide the model’s behavior through prompt design—for example, by setting a maximum reasoning length or routing queries based on their difficulty. The goal is to encourage more concise and efficient responses.
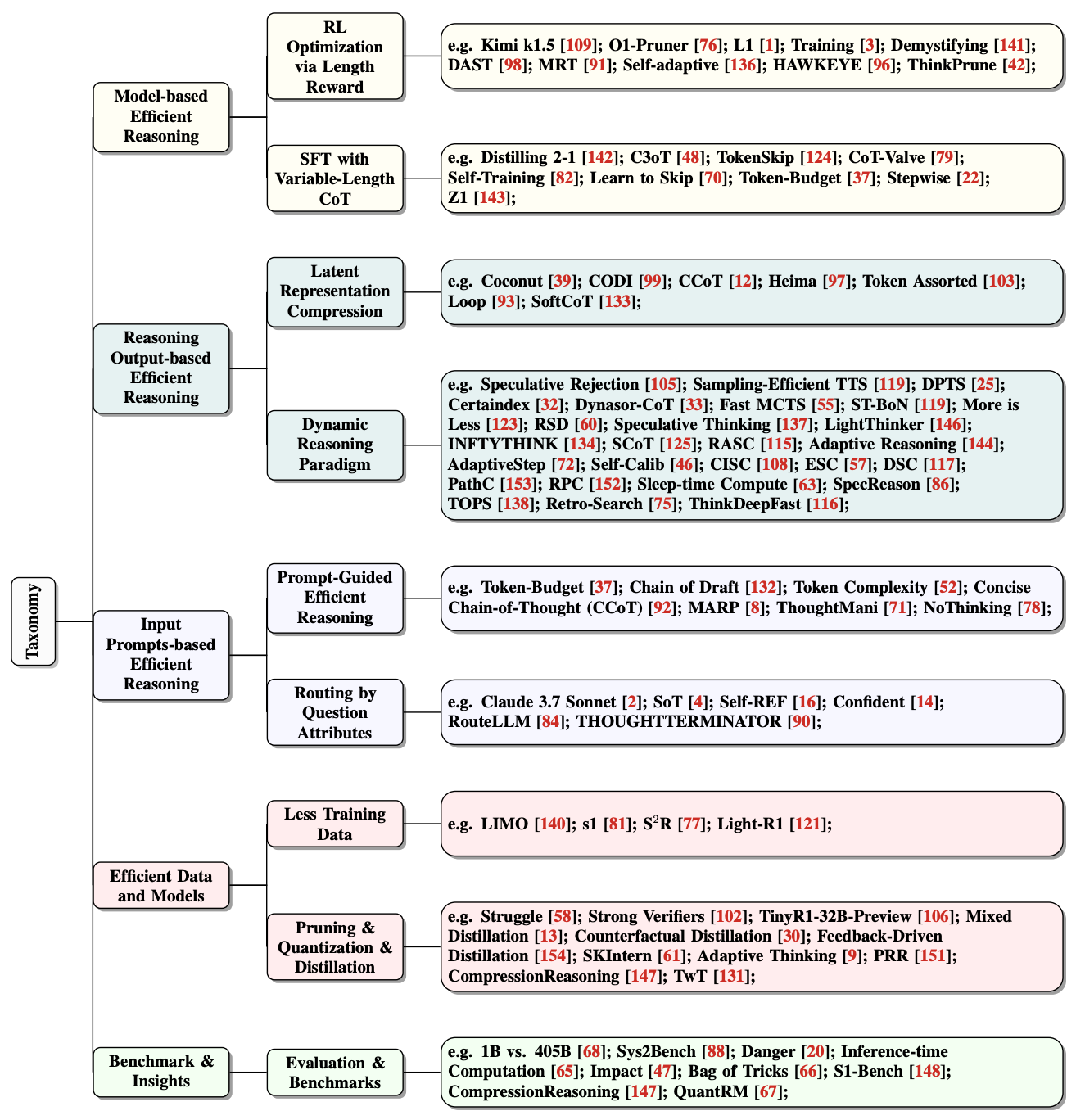
Figure 4 gives an overview of the related methods.
Thoughts and Insights
LLMs today are caught in a tough trade-off between reasoning quality and efficiency. As reasoning chains get longer, the cost keeps climbing—making it hard to deploy these models in real-world scenarios like search, dialogue systems, or autonomous driving. In many cases, inefficient reasoning has become a real bottleneck.
Here are a few practical tips I’ve found helpful in real-world use:
Use a token budget in your prompts to keep responses focused and efficient.
For long conversations or large corpus RAG tasks, try KV-Cache compression with INT8 or INT4—it can save a lot of memory.
In high-load scenarios or when working with very long inputs, consider using Latent Chain of Thought (Latent CoT) to ease the processing burden.
Overall, improving reasoning efficiency isn’t just a technical challenge—it’s quickly becoming a key industry priority. Over the next few years, "efficient reasoning" is likely to emerge as one of the central themes in optimizing AI infrastructure.