

Fast GraphRAG is a well-known implementation of Graph RAG. I recently took a closer look at its source code, and here are a few things I’d like to share.
What Does Fast GraphRAG Actually Store?
Storage is a core part of any RAG system—deeply tied to both indexing and retrieval. So what exactly does Fast GraphRAG persist under the hood?
After digging into the source code, I found that it maintains three main types of persistent data: Entity-Relationship Graph, Entity Vector Index, and Text Chunk Store, as shown in Figure 1.
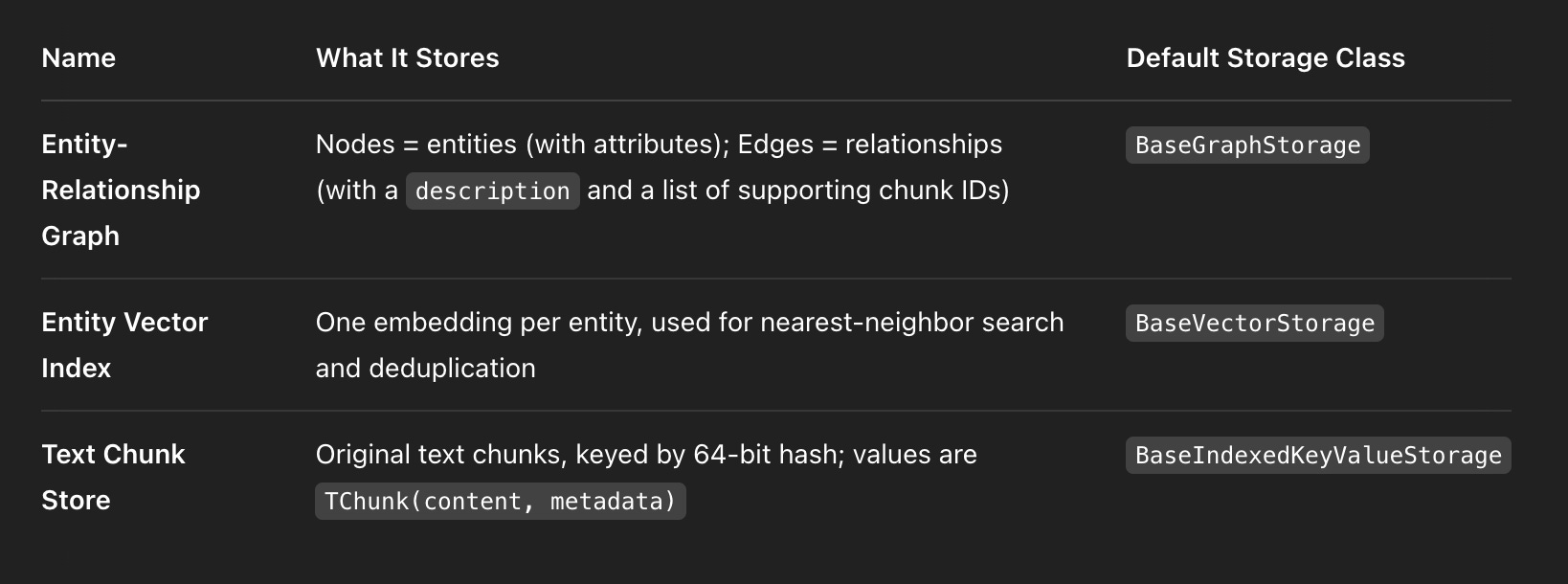
But Wait—If It’s GraphRAG, Why Store Text Chunks at All?
The answer lies in how answers are generated: they often need to reference the original source and provide evidence. Without storing the actual chunks, you can’t highlight or trace back to the original text later.
In practice, when you set with_references=True, the system includes the matched chunk in the final answer—so the frontend can highlight them for the user. No stored chunks? No traceability.
There’s another reason too: deduplication and version control. Each chunk is keyed by a hash, and paired with metadata. That way, identical sentences won’t be stored twice, and you can track exactly where each one came from.
What Database Does It Actually Use?
Technically speaking, the classes like class BaseGraphStorage, class BaseVectorStorage, and class BaseIndexedKeyValueStorage are just abstract interfaces.

The real backend is determined by the config. By default, as shown in Figure 2, here’s what’s used out of the box:
Entity-Relationship Graph → class IGraphStorage
Entity Vector Index → class HNSWVectorStorage
Text Chunk Store → class PickleIndexedKeyValueStorage
Want to use Neo4j, TigerGraph, or ArangoDB for your entity graph?
If your implementation follows the expected method signatures (e.g. insert nodes/edges, query, etc.), there’s a chance it could work, depending on the details.
Query Flow
Now let’s talk about the Query Flow.
Keep reading with a 7-day free trial
Subscribe to AI Exploration Journey to keep reading this post and get 7 days of free access to the full post archives.