


Equipping LLMs with a "Smart Sieve": How RankRAG Enhances Efficiency in RAG

In the realm of large language models (LLMs), Retrieval-Augmented Generation (RAG) has become a widely adopted technique to enhance the generation capabilities by retrieving relevant contexts from vast data repositories.
However, the existing RAG pipelines face significant limitations:
Limited Retriever Capacity: Existing retrievers, like BM25 or BERT-based models, struggle to accurately match questions with relevant contexts, particularly in new tasks or domains.
Trade-off in Top-k Selection: Increasing the number of retrieved contexts (k) can improve recall but often introduces irrelevant or noisy information, which can mislead the LLM during answer generation.
Ineffective Ranking Models: Separate ranking models used in RAG pipelines often fail to capture query-context relevance effectively and lack strong generalization capabilities, particularly in zero-shot scenarios.
For example, consider the task of answering a complex question using a large document database. Traditional RAG methods might retrieve too many irrelevant sections, overwhelming the model and reducing the quality of the generated answer. This situation is analogous to searching for a needle in a haystack, where the haystack is so large that even a powerful LLM struggles to find the needle efficiently.
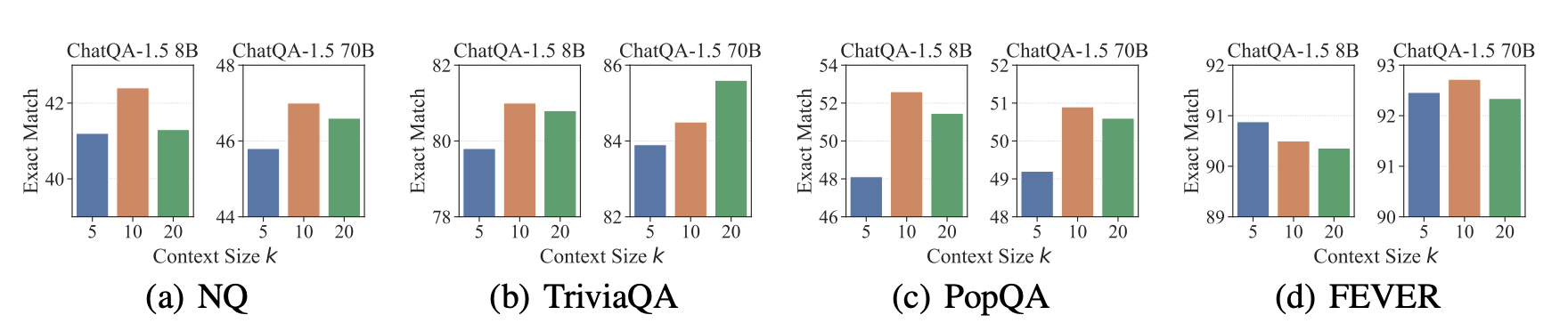
Figure 1 illustrates the trade-off between selecting a smaller set of top-k contexts and the introduction of irrelevant or noisy contexts when k is increased, highlighting the need for a more effective context ranking mechanism.
In this artice, we introduce a new study called "RankRAG", a novel framework designed to address these challenges by unifying context ranking with answer generation within a single LLM.
Solution
RankRAG is an instruction fine-tuning framework that trains an LLM to simultaneously rank contexts and generate answers. This dual-purpose model effectively handles the selection of relevant contexts from a large pool and uses them to generate high-quality answers.
Figure 2 depicts the two-stage instruction tuning framework for RankRAG, which enhances the model's capabilities in both context ranking and retrieval-augmented generation.
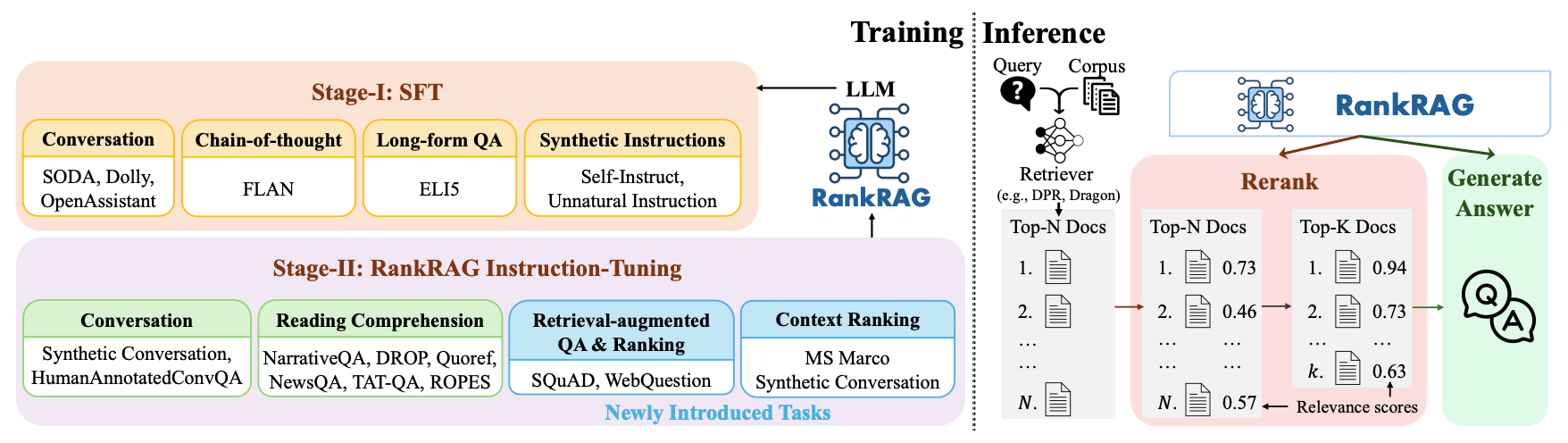
The RankRAG framework consists of two stages.
Stage I: Supervised Fine-Tuning (SFT)
This stage involves instruction-tuning the LLM using a diverse set of high-quality datasets, including conversation and long-form QA datasets. The focus is on improving the LLM's instruction-following capabilities, which lays the foundation for the subsequent stage.
Stage II: Unified Instruction-Tuning for Ranking and Generation
In this stage, the LLM is further tuned using a blend of context-rich QA, retrieval-augmented QA, and context ranking data, as shown in Figure 3.

This stage is crucial as it equips the model with the ability to rank contexts effectively, even when the initial retrieval results are imperfect.
Figure 4 provides a detailed instruction template used in Stage II, highlighting how various tasks are standardized into a unified format to facilitate knowledge transfer across tasks.

RankRAG Inference Pipeline: Retrieve-Rerank-Generate
As shown in the right of Figure 2, the inference process is divided into three main stages: retrieval, reranking, and generation:
Retrieval Stage: This process is akin to traditional RAG models, where pre-trained retrievers like DPR or BM25 extract text segments that potentially contain the answer. While this step retrieves a large number of possibly useful contexts, their relevance and precision are often not high enough for direct use in generating the final answer.
Reranking Stage: To enhance the accuracy of the generated content, RankRAG introduces a reranking stage. In this phase, the RankRAG model evaluates and reorders the retrieved contexts based on their relevance to the query. This allows the model to filter out irrelevant or noisy information, focusing only on the most pertinent pieces.
Generation Stage: After reranking, the RankRAG model uses the top-ranked contexts to generate the final answer. Due to the optimizations in the previous steps, the model can concentrate on processing the most useful information, thereby improving the accuracy and contextual relevance of the answer.
Evaluation
As shown in Figure 5, when compared to other models, RankRAG demonstrates superior performance in both context ranking and answer generation. Unlike traditional methods that use separate ranking models, RankRAG's integrated approach allows for better generalization and higher accuracy in zero-shot scenarios.

Case Study
To illustrate the practical effectiveness, RankRAG conducted a case study using the NQ (Natural Questions) dataset, a challenging benchmark for open-domain question answering.
In the specific example discussed, the question posed was, "Who hosted and won the inaugural World Cup?" The correct answer is Uruguay. However, the challenge lies in the model's ability to sift through a large set of retrieved contexts, some of which may contain relevant details while others introduce distractions or irrelevant information.

Traditional RAG Models
Traditional RAG models, such as ChatQA-1.5, typically retrieve several contexts but struggle to prioritize the most pertinent ones.
In this case, ChatQA-1.5 retrieved a series of passages, many of which included misleading information. For instance, passages discussing various World Cup hosts and winners did not directly address the inaugural event or introduced unrelated details, such as subsequent World Cup tournaments and host nations.
As a result, the model incorrectly predicted Germany as the answer, distracted by these less relevant contexts.
RankRAG
In the same scenario, RankRAG initially retrieved a similar set of passages as ChatQA-1.5. However, the reranking step allowed it to assign higher relevance to passages specifically mentioning Uruguay's victory in the 1930 World Cup, which was both the inaugural tournament and hosted by Uruguay.
By leveraging its reranking capability, RankRAG was able to discard irrelevant information and elevate the importance of these key passages. Consequently, the model produced the correct answer—Uruguay—demonstrating its superiority in handling complex queries within noisy datasets.
Conclusion and Insights
This article has introduced RankRAG, it innovatively combines context ranking and answer generation within a single LLM, allowing it to accurately filter and prioritize relevant information from large datasets. This dual-purpose approach improves the precision and relevance of generated answers by integrating reranking directly into the retrieval-augmented generation process. As a result, RankRAG outperforms traditional RAG models, particularly in handling complex and noisy data scenarios.
From my perspective, RankRAG represents a significant advancement in the field of retrieval-augmented generation. The unification of context ranking and answer generation within a single LLM not only simplifies the pipeline but also enhances the overall performance.
However, the introduction of an additional reranking step does raise concerns about efficiency, particularly in time-sensitive applications. Future work could explore optimizing this step to balance accuracy with processing time.
Moreover, RankRAG already shows promising results in the biomedical domain, but further exploration could solidify its applicability across diverse fields.