
dots.ocr: Turning Document Parsing into a Single Generation Task — AI Innovations and Insights 99
At first glance, document parsing might look like OCR, but it’s really a three-part problem.
First, you need to detect the layout (where are the blocks?); then you recognize the content (what’s inside those blocks?); and finally, you have to make sense of how everything fits together in the way humans would read it, what’s the logical flow?
But this pipeline has some issues.
This post offers a insightful perspective.
The Problem with Traditional Multi-Stage Document Parsing Pipelines
Most existing approaches treat this as a step-by-step pipeline: one model or module handles each part in sequence (Demystifying PDF Parsing 02: Pipeline-Based Method). It might seem modular and clean, but this comes with some serious downsides.
Errors Snowball: If the layout detection is off, such as the bounding boxes are misaligned, then content recognition suffers. And if the content is off, then figuring out the correct reading order becomes difficult. These cascading failures are common in multi-stage setups and tough to recover from.
The Tasks Are Inherently Interconnected: Layout, content, and structure aren’t just separate problems, they actually help each other. But traditional pipelines split them apart, preventing useful cross-talk. That separation leaves a lot of performance on the table. Treating them in isolation can cap the model’s potential.
Data Bias and Language Gaps: Most document parsing models have been trained and evaluated on English-heavy datasets. Creating high-quality annotations in multiple languages is expensive and labor-intensive, which has made true multilingual support almost impossible to scale.
In short: The industry hasn’t avoided unified models because it doesn’t want better performance. The real blockers have been the prohibitive computational cost and lack of architectural priors in generalist models, the fragmentation of specialized pipelines, and the high cost of multilingual data.
dots.ocr: One Forward Pass, All Tasks Done
dots.ocr takes a bold stance.
Instead of splitting document parsing into three separate stages, it tackles everything (layout detection, content recognition, and relational understanding) in a single-model end-to-end generative process. All of this runs inside one unified Vision-Language Model.
In other words, dots.ocr doesn’t just bundle three tasks into a single model. It rewrites the problem as a single generative task, then feeds it with the kind of data that makes true unification possible.
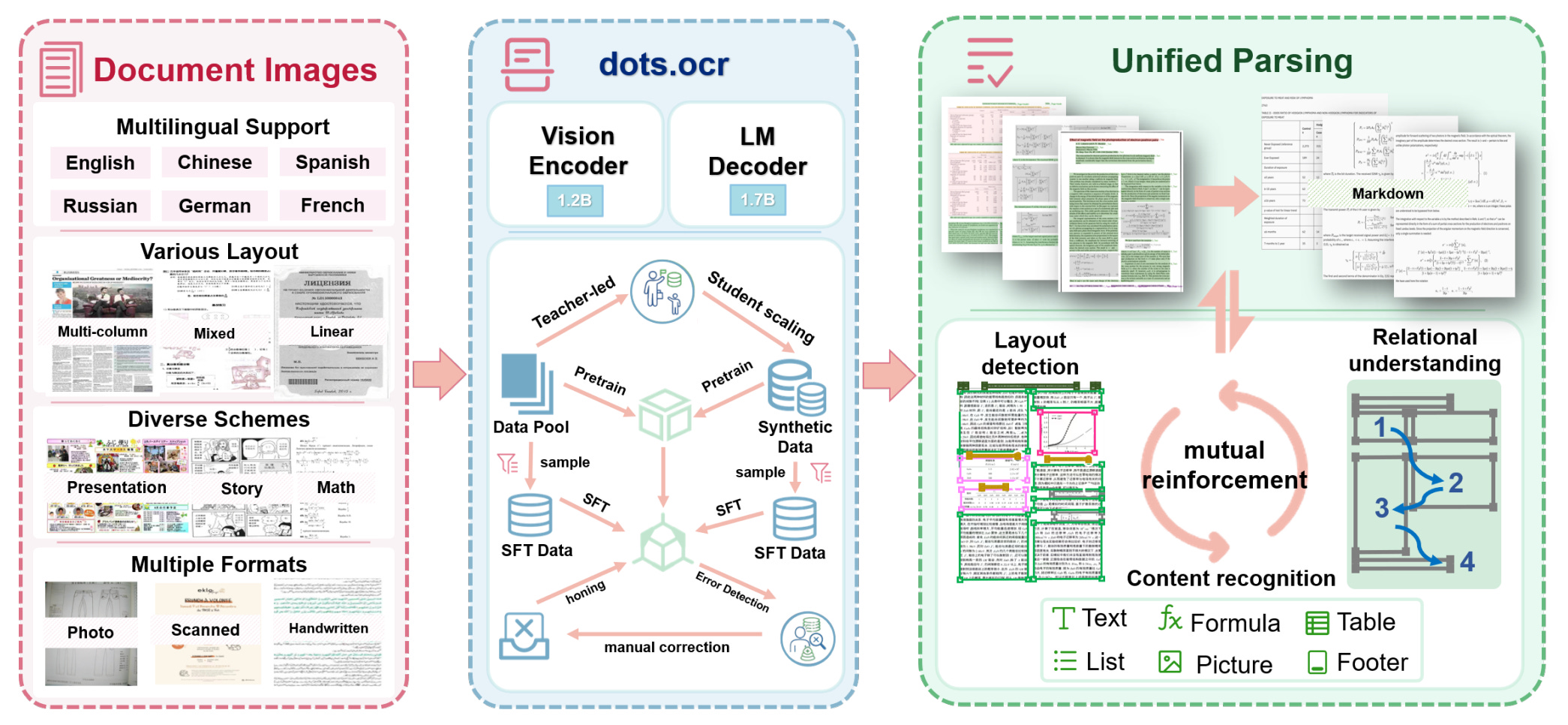
To make this work, dots.ocr breaks the core innovation into two major pieces:
1. A Unified Training Paradigm, Tailored for OCR
The architecture and training strategy are built specifically for the unified task. This isn’t about stacking existing models together.
It’s a deeply customized architecture: it employs a 1.2B Vision Encoder trained entirely from scratch paired with an adapted Language Model Decoder (Qwen2.5-1.5B as foundation), allowing the model to learn layout, content, and structure as one cohesive process:
The architecture follows a ViT-LLM design inspired by recent VLMs (e.g., Qwen2-VL) with task-specific modifications.
The vision encoder is high-resolution (up to ~11M pixels) and trained with multi-faceted objectives for both fine-grained text and high-level layout structures.
The decoder is based on Qwen2.5-1.5B and modified (e.g., tied embeddings) to ~1.7B parameters.
dots.ocr treats multilingual document parsing as a single auto-regressive generation task: given a document image I, the model outputs a structured sequence S.
But S isn’t just a dump of boxes and text. Each item in the sequence is a well-formed triplet:
Bk: the bounding box coordinates
ck: the type of content block (like title, header, table, figure)
tk: the text inside that block. For structured regions like tables, the content is encoded in LaTeX format to preserve layout and hierarchy.
The key idea behind the unification lies in how the sequence is generated. It follows the natural reading flow of a human, which means the model has to understand not just what is on the page, but how it’s organized and how the pieces connect.
Put simply, rather than decoupling layout and recognition into staged subsystems, the model jointly resolves block localization, categorization, text, and reading-order/relations while generating a reading-order-aligned structured sequence (which may involve multi-column layouts).
2. A Holistic Data Engine
Training a model like this takes more than clever design, it also demands scale and diversity in data.
dots.ocr built a three-stage data engine to synthesize massive, multilingual, and richly structured document data. It’s not just big, it’s balanced and deeply curated to reflect real-world complexity.
If the unified task is the steering wheel, then the Data Engine is the fuel tank. Off-the-shelf datasets simply don’t meet the demands of both scale and diversity, so dots.ocr built a custom, three-stage engine from scratch.
Bootstrapping a Multilingual Synthesis Engine: The first challenge in building a multilingual document parser is getting high-quality training data across languages. To tackle the cold start problem, dots.ocr began with a teacher–student distillation: the teacher (Qwen2.5-VL-72B) generates layout-preserving multilingual seed documents, which are then used to fine-tune an efficient 7B student (Qwen2.5-VL-7B) that becomes the scalable auto-labeling engine.
Strategically Curated Corpus for Large-Scale Pre-training: Next, dots.ocr curates a large pool of real-world PDFs stratified by layout complexity, language rarity, and domain. Using the engine from Stage 1, these documents are automatically labeled at scale, transforming raw files into structured training data.
Targeted Correction: Finally, the pre-trained model was run across the diverse document set. Its outputs were programmatically audited, and a powerful VLM oracle flagged errors, everything from misalignments to omissions and hallucinated content. High-confidence mistakes were then routed to human annotators, resulting in a compact but high-signal dataset of over 15,000 samples that efficiently honed the model's precision.
In short: stage 1 builds the multilingual engine, stage 2 scales it up with curated diversity, and stage 3 fine-tunes it with precision feedback to keep the model on track.
Evaluation
The performance is evaluated on the comprehensive OmniDocBench benchmark for English (EN) and Chinese (ZH), and on newly proposed XDocParse benchmark for large-scale multilingual evaluation (Multilingual).
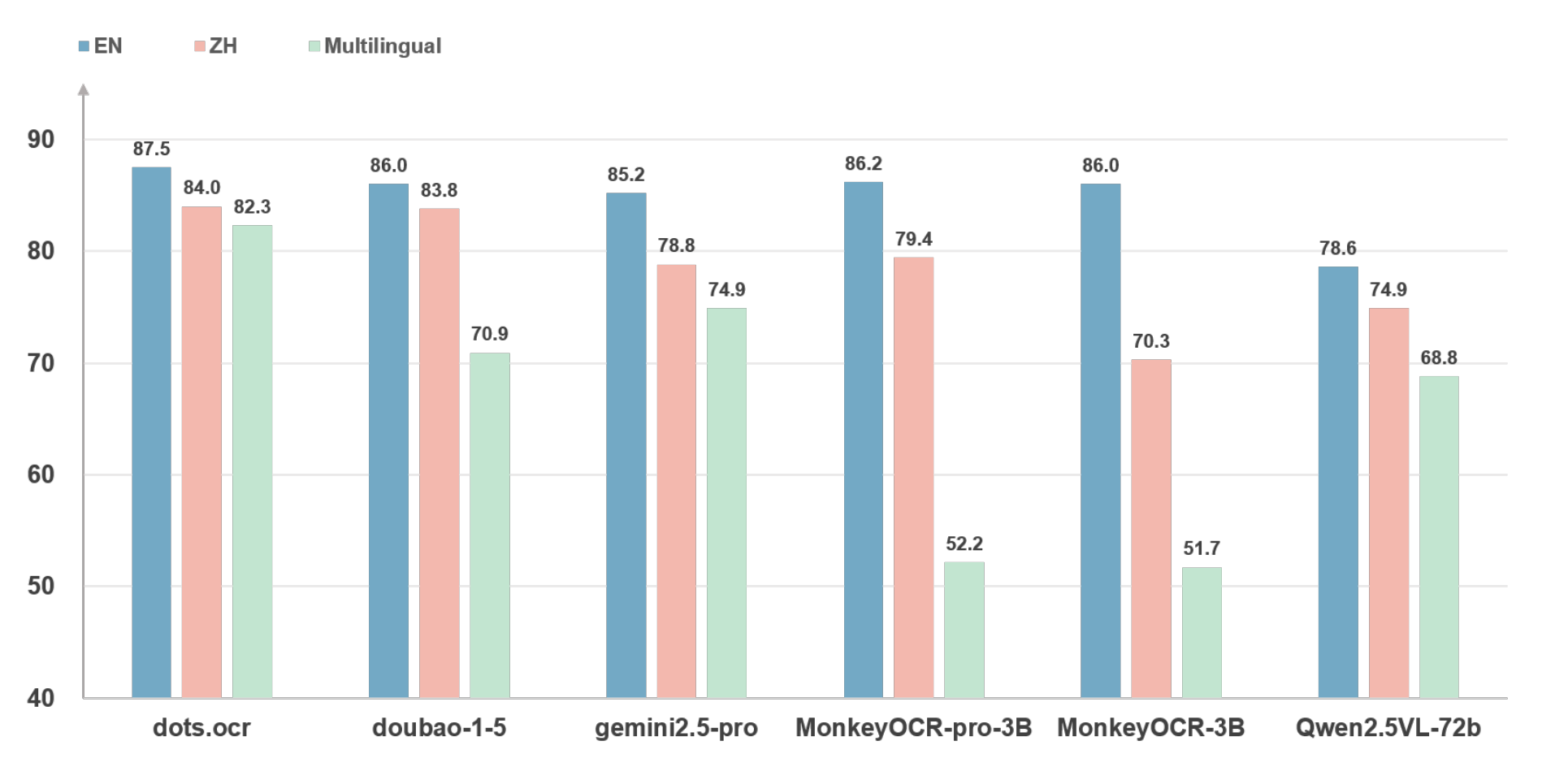
As shown in Figure 2, dots.ocr consistently outperforms all competing methods across all three settings, demonstrating its superior capability.
Thoughts
The core idea behind dots.ocr is simple: instead of breaking document parsing into isolated steps, treat it like a full read-through by a single model that sees and understands the entire page in a single generation task. The role of the Data Engine is to make sure this model has read widely (across many languages, layouts, and formats) and has been carefully corrected when it gets things wrong.
But I have a concern.
The model’s heavy reliance on Stage 3 — the targeted correction loop involving human feedback, auditing, and oracle-based diagnosis. As shown in Figure 3, The ablation results show that removing this stage leads to a catastrophic drop in detection F1 (0.849 → 0.788), highlighting just how critical this phase is for final performance.
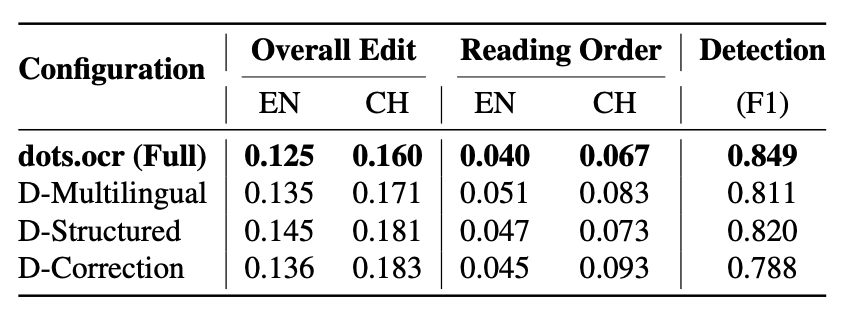
This raises a broader question about reproducibility. Organizations with access to the full data engine, especially considering this stage relies on a complex audit pipeline to generate a compact but crucial set of ~15,000 high-signal samples. Without the full infrastructure, replicating the results or meaningfully fine-tuning the model becomes significantly harder.
Reference: dots.ocr: Multilingual Document Layout Parsing in a Single Vision-Language Model.